kth8/gemma-4-E4B-it-Health_Benchmarks-benchmark
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/kth8/gemma-4-E4B-it-Health_Benchmarks-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
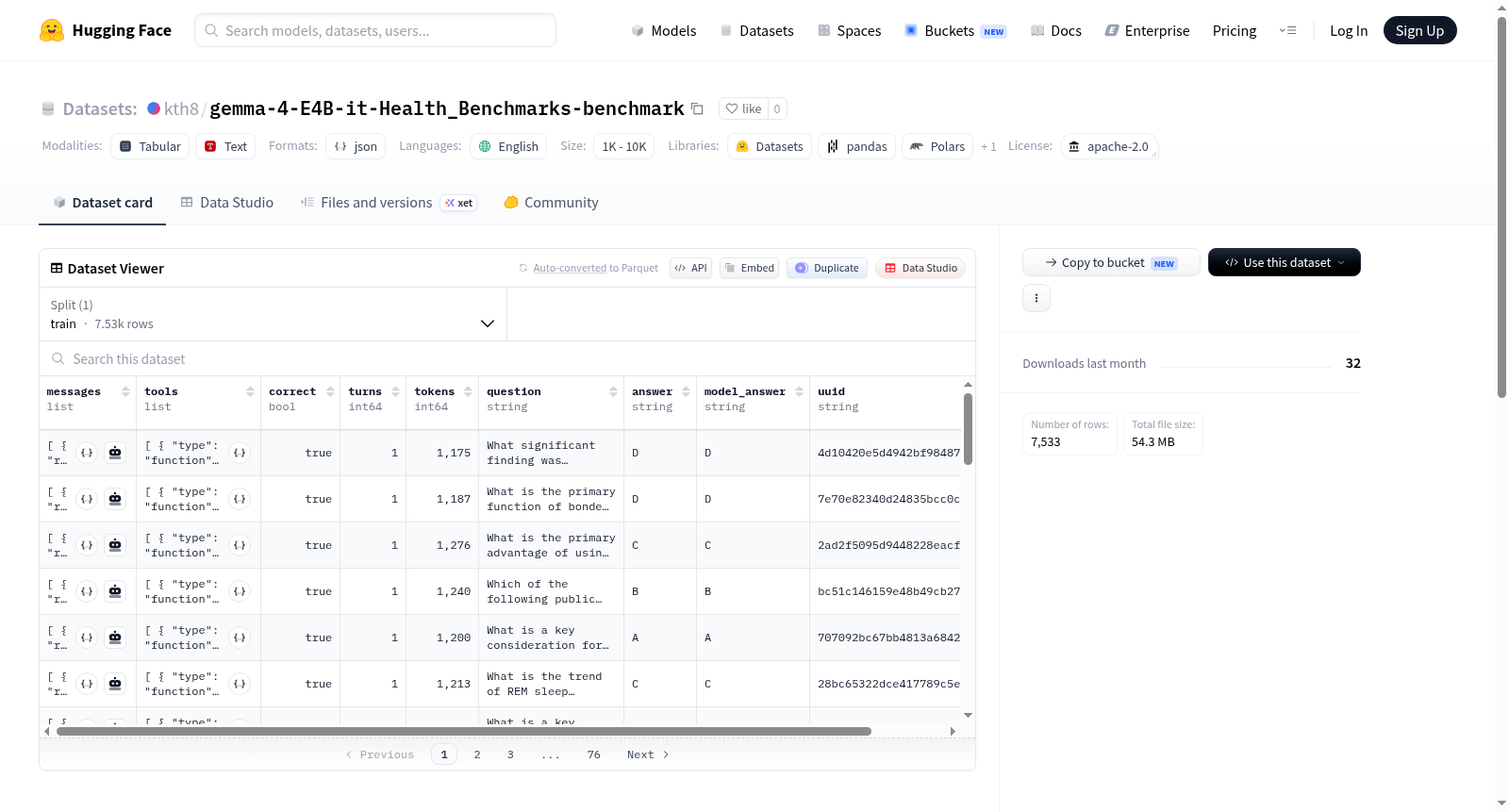
这是一个基准测试数据集,用于评估google/gemma-4-E4B-it模型在yesilhealth/Health_Benchmarks健康基准数据集上的性能。数据集包含7535个样本,其中5864个正确,1669个错误,2个错误样本,总完成token数为8,144,545,准确率为77.8%。
This is a benchmark dataset for evaluating the performance of the google/gemma-4-E4B-it model on the yesilhealth/Health_Benchmarks health benchmarks dataset. The dataset contains 7535 samples, with 5864 correct, 1669 incorrect, 2 errors, a total of 8,144,545 completion tokens, and an accuracy of 77.8%.
提供机构:
kth8
搜集汇总
数据集介绍
构建方式
本数据集基于Google开发的医疗领域大语言模型gemma-4-E4B-it,选取yesilhealth/Health_Benchmarks基准测试集作为评估语料,通过模型对医疗问答任务的推理生成,系统性地收集了模型在7535个样本上的预测结果。数据集的构建核心在于记录模型对每个样本的响应正确性,并归纳出正确、错误及异常样本的数量,同时统计了生成过程中耗费的完成令牌总数,从而形成一份结构化的模型性能基准报告。
特点
该数据集涵盖了医疗健康领域广泛的专业评测样本,包含7535条测试实例,其显著特征在于提供了模型预测结果的细粒度统计——正确回答5864例,错误1669例,仅2例异常,展现出高可靠性评估框架。尤为突出的是,数据集中记录了超过814万完成令牌的消耗量,反映了模型在处理复杂医疗问答时的计算负载,为衡量医疗大语言模型的推理效率与准确率提供了双重量化指标。
使用方法
研究人员可直接加载本数据集作为gemma-4-E4B-it模型在医疗健康任务上的性能评测结果,用于对比不同模型或版本间的推理表现。使用时可提取accuracy字段(0.778)作为核心评估指标,亦可深入分析correct、incorrect及error分布,以诊断模型在特定医学问题上的薄弱环节。此外,completion_tokens数据适用于计算模型部署的资源成本,辅助优化推理策略。
背景与挑战
背景概述
在大型语言模型(LLM)的快速发展浪潮中,如何系统地评估模型在特定领域(如医疗健康)中的能力成为关键挑战。由Google研究与Yesil Health团队联合创建的gemma-4-E4B-it-Health_Benchmarks-benchmark数据集,基于高效开源模型Gemma 4的指令微调版本(E4B-it),并整合了Yesil Health提供的健康领域基准测试数据,旨在评估LLM在医学知识问答、诊断推理等任务上的表现。该数据集创建于前沿AI模型与医疗应用交叉的时期,其核心研究问题聚焦于量化LLM在健康领域中的准确性、鲁棒性与实用价值。通过公开标准化评测结果,它为研究社区提供了可复现的评估范式,推动了医疗AI从模型开发到实际部署的验证进程,对深化AI辅助临床决策的研究具有重要影响力。
当前挑战
该数据集所解决的领域问题核心在于,医疗健康场景对模型输出的准确性与可靠性要求极高,但现有通用基准难以衡量LLM在医学知识精密度、错误敏感度等方面的实际能力。数据集构建过程中面临多重挑战:首先,需从多元临床文本(如病历、医学文献)中筛选并标准化高质量测试样本,确保覆盖不同专科与疾病谱系;其次,平衡问题难度与模型能力边界,避免因样本偏差(如偏重常见疾病)导致评估失真;最后,处理长文本推理带来的计算开销与语义歧义问题,在本次评测中模型消耗了814万个完成Token,且准确率仅77.8%,反映出模型在应对复杂医学逻辑或罕见病例时存在显著知识盲区与推理短板,这为后续模型迭代与数据增强指明了方向。
常用场景
经典使用场景
Gemma-4-E4B-it-Health_Benchmarks-benchmark数据集的核心价值在于对大规模语言模型在医疗健康领域的知识掌握与推理能力进行系统性评估。该数据集由7535个样本构成,涵盖了从基础医学常识到复杂临床决策的多维度问题,为验证生成式AI在医学术语理解、诊断逻辑构建以及治疗建议生成等关键环节的表现提供了标准化的测试平台。研究者通过对比模型输出与基准答案,能够量化模型在健康领域零样本或少样本学习场景下的泛化能力。
解决学术问题
在学术研究层面,该数据集有效解决了医疗AI领域中量化评估难、指标碎片化的痛点问题。传统上,语言模型在健康领域的性能评价往往依赖于主观专家评审或小规模、领域特定的测试集,难以横向对比。Gemma-4-E4B-it-Health_Benchmarks-benchmark通过统一的大规模基准测试,为模型在临床知识回忆、医学推理、安全性校验等维度的表现提供了可复现的量化指标。其77.8%的准确率基线揭示了当前模型在应对复杂医疗场景时的优势与短板,推动了可信赖医疗AI评估体系的构建。
衍生相关工作
围绕该数据集衍生了一系列具有影响力的相关工作,推动了医疗AI的边界探索。一方面,研究者基于此基准开发了针对医疗领域的高效微调方法,如领域适配的LoRA优化策略,显著提升了模型在专业问答中的准确率。另一方面,该数据集催生了多项关于模型医学幻觉检测与纠偏机制的经典研究,其中部分工作通过对比不同量级模型在同一基准上的表现,揭示了参数规模与医学推理精度之间的非线性关系。此外,跨语种迁移学习和多模态医疗评测也以此基准为重要参照,实现了从文本诊断到影像-文本融合评估的拓展。
以上内容由遇见数据集搜集并总结生成


