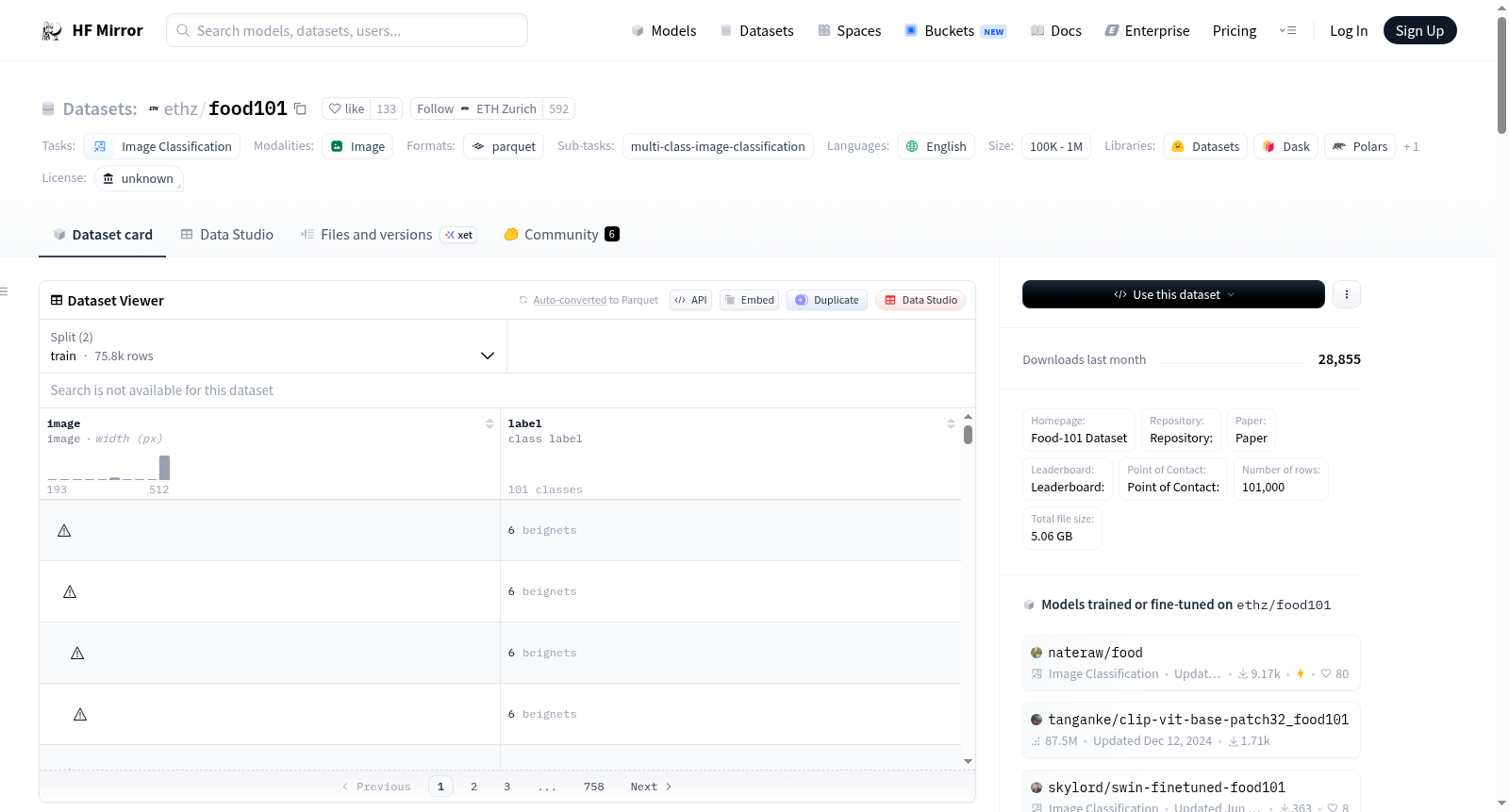
ethz/food101
收藏Hugging Face2026-03-09 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/ethz/food101
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|other-foodspotting
task_categories:
- image-classification
task_ids:
- multi-class-image-classification
paperswithcode_id: food-101
pretty_name: Food-101
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': apple_pie
'1': baby_back_ribs
'2': baklava
'3': beef_carpaccio
'4': beef_tartare
'5': beet_salad
'6': beignets
'7': bibimbap
'8': bread_pudding
'9': breakfast_burrito
'10': bruschetta
'11': caesar_salad
'12': cannoli
'13': caprese_salad
'14': carrot_cake
'15': ceviche
'16': cheesecake
'17': cheese_plate
'18': chicken_curry
'19': chicken_quesadilla
'20': chicken_wings
'21': chocolate_cake
'22': chocolate_mousse
'23': churros
'24': clam_chowder
'25': club_sandwich
'26': crab_cakes
'27': creme_brulee
'28': croque_madame
'29': cup_cakes
'30': deviled_eggs
'31': donuts
'32': dumplings
'33': edamame
'34': eggs_benedict
'35': escargots
'36': falafel
'37': filet_mignon
'38': fish_and_chips
'39': foie_gras
'40': french_fries
'41': french_onion_soup
'42': french_toast
'43': fried_calamari
'44': fried_rice
'45': frozen_yogurt
'46': garlic_bread
'47': gnocchi
'48': greek_salad
'49': grilled_cheese_sandwich
'50': grilled_salmon
'51': guacamole
'52': gyoza
'53': hamburger
'54': hot_and_sour_soup
'55': hot_dog
'56': huevos_rancheros
'57': hummus
'58': ice_cream
'59': lasagna
'60': lobster_bisque
'61': lobster_roll_sandwich
'62': macaroni_and_cheese
'63': macarons
'64': miso_soup
'65': mussels
'66': nachos
'67': omelette
'68': onion_rings
'69': oysters
'70': pad_thai
'71': paella
'72': pancakes
'73': panna_cotta
'74': peking_duck
'75': pho
'76': pizza
'77': pork_chop
'78': poutine
'79': prime_rib
'80': pulled_pork_sandwich
'81': ramen
'82': ravioli
'83': red_velvet_cake
'84': risotto
'85': samosa
'86': sashimi
'87': scallops
'88': seaweed_salad
'89': shrimp_and_grits
'90': spaghetti_bolognese
'91': spaghetti_carbonara
'92': spring_rolls
'93': steak
'94': strawberry_shortcake
'95': sushi
'96': tacos
'97': takoyaki
'98': tiramisu
'99': tuna_tartare
'100': waffles
splits:
- name: train
num_bytes: 3842657187.0
num_examples: 75750
- name: validation
num_bytes: 1275182340.5
num_examples: 25250
download_size: 5059972308
dataset_size: 5117839527.5
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
# Dataset Card for Food-101
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Food-101 Dataset](https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/)
- **Repository:**
- **Paper:** [Paper](https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/static/bossard_eccv14_food-101.pdf)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset consists of 101 food categories, with 101'000 images. For each class, 250 manually reviewed test images are provided as well as 750 training images. On purpose, the training images were not cleaned, and thus still contain some amount of noise. This comes mostly in the form of intense colors and sometimes wrong labels. All images were rescaled to have a maximum side length of 512 pixels.
### Supported Tasks and Leaderboards
- `image-classification`: The goal of this task is to classify a given image of a dish into one of 101 classes. The leaderboard is available [here](https://paperswithcode.com/sota/fine-grained-image-classification-on-food-101).
### Languages
English
## Dataset Structure
### Data Instances
A sample from the training set is provided below:
```
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x276021C5EB8>,
'label': 23
}
```
### Data Fields
The data instances have the following fields:
- `image`: A `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`.
- `label`: an `int` classification label.
<details>
<summary>Class Label Mappings</summary>
```json
{
"apple_pie": 0,
"baby_back_ribs": 1,
"baklava": 2,
"beef_carpaccio": 3,
"beef_tartare": 4,
"beet_salad": 5,
"beignets": 6,
"bibimbap": 7,
"bread_pudding": 8,
"breakfast_burrito": 9,
"bruschetta": 10,
"caesar_salad": 11,
"cannoli": 12,
"caprese_salad": 13,
"carrot_cake": 14,
"ceviche": 15,
"cheesecake": 16,
"cheese_plate": 17,
"chicken_curry": 18,
"chicken_quesadilla": 19,
"chicken_wings": 20,
"chocolate_cake": 21,
"chocolate_mousse": 22,
"churros": 23,
"clam_chowder": 24,
"club_sandwich": 25,
"crab_cakes": 26,
"creme_brulee": 27,
"croque_madame": 28,
"cup_cakes": 29,
"deviled_eggs": 30,
"donuts": 31,
"dumplings": 32,
"edamame": 33,
"eggs_benedict": 34,
"escargots": 35,
"falafel": 36,
"filet_mignon": 37,
"fish_and_chips": 38,
"foie_gras": 39,
"french_fries": 40,
"french_onion_soup": 41,
"french_toast": 42,
"fried_calamari": 43,
"fried_rice": 44,
"frozen_yogurt": 45,
"garlic_bread": 46,
"gnocchi": 47,
"greek_salad": 48,
"grilled_cheese_sandwich": 49,
"grilled_salmon": 50,
"guacamole": 51,
"gyoza": 52,
"hamburger": 53,
"hot_and_sour_soup": 54,
"hot_dog": 55,
"huevos_rancheros": 56,
"hummus": 57,
"ice_cream": 58,
"lasagna": 59,
"lobster_bisque": 60,
"lobster_roll_sandwich": 61,
"macaroni_and_cheese": 62,
"macarons": 63,
"miso_soup": 64,
"mussels": 65,
"nachos": 66,
"omelette": 67,
"onion_rings": 68,
"oysters": 69,
"pad_thai": 70,
"paella": 71,
"pancakes": 72,
"panna_cotta": 73,
"peking_duck": 74,
"pho": 75,
"pizza": 76,
"pork_chop": 77,
"poutine": 78,
"prime_rib": 79,
"pulled_pork_sandwich": 80,
"ramen": 81,
"ravioli": 82,
"red_velvet_cake": 83,
"risotto": 84,
"samosa": 85,
"sashimi": 86,
"scallops": 87,
"seaweed_salad": 88,
"shrimp_and_grits": 89,
"spaghetti_bolognese": 90,
"spaghetti_carbonara": 91,
"spring_rolls": 92,
"steak": 93,
"strawberry_shortcake": 94,
"sushi": 95,
"tacos": 96,
"takoyaki": 97,
"tiramisu": 98,
"tuna_tartare": 99,
"waffles": 100
}
```
</details>
### Data Splits
| |train|validation|
|----------|----:|---------:|
|# of examples|75750|25250|
## Dataset Creation
### Curation Rationale
Food-101 was constructed to create a challenging fine-grained image classification benchmark for computer vision research. The 101 categories were chosen to represent dishes commonly photographed and shared on the social platform Foodspotting.com, with an intentional emphasis on visually distinct dishes to make category discrimination non-trivial. The benchmark was designed to evaluate models capable of discriminating between foods that differ subtly in appearance (e.g., various noodle dishes) as well as dishes with high intra-class variance (e.g., pizza with many possible toppings).
### Source Data
#### Initial Data Collection and Normalization
Images were retrieved from [Foodspotting](http://www.foodspotting.com/), a social food photography platform where users shared photos of dishes eaten at restaurants. Category labels were assigned using the platform's dish taxonomy. Each category was populated with 1,000 images: 750 for training and 250 for testing. Test images were manually reviewed for label correctness; training images were left uncleaned and intentionally retain label noise and image artifacts. All images were resized so that the maximum side length is 512 pixels.
#### Who are the source language producers?
The images were contributed by Foodspotting.com users photographing dishes primarily in restaurant settings. The geographic distribution of source photos reflects the user base of Foodspotting.com, which was predominantly North American and Western European at the time of collection (c. 2014). Class labels are in English.
### Annotations
#### Annotation process
Test set labels (250 images per class) were verified by human annotators. Training set labels (750 images per class) were assigned automatically based on the Foodspotting dish taxonomy and were not manually reviewed, resulting in a known level of label noise in the training split.
#### Who are the annotators?
Test set annotations were reviewed by the dataset authors at ETH Zurich. Training set labels derive from Foodspotting.com's crowdsourced dish tagging and were not independently verified.
### Personal and Sensitive Information
Images contain photographs of restaurant dishes. Some images may incidentally include people's hands or partial faces in the background, as photos were taken in social dining settings. No systematic attempt was made to identify or redact personal information.
## Considerations for Using the Data
### Social Impact of Dataset
Food-101 has been widely adopted as a benchmark for food image classification models, which are deployed in applications including restaurant menu recognition, dietary logging, nutrition estimation, and food recommendation systems. Models trained on this benchmark may be integrated into consumer products that influence dietary choices, medical nutrition tracking, and health recommendations.
The dataset's category distribution reflects dishes photographed on a predominantly North American and European social platform. Models trained on Food-101 may underperform on dishes from cuisines not well represented in the benchmark. Practitioners deploying food classification models in global or multicultural contexts should evaluate performance across the specific cuisines relevant to their use case before deployment.
### Discussion of Biases
**Category selection bias:** The 101 categories were drawn from dishes popular on Foodspotting.com as of c. 2014, reflecting the platform's predominantly North American and Western European user base. Many cuisines with large global populations are absent or underrepresented (e.g., most Sub-Saharan African, Central Asian, and many South American regional cuisines).
**Dietary category imbalance:** Of the 101 classes, approximately 12-15 are predominantly or exclusively plant-based (including `edamame`, `falafel`, `guacamole`, `hummus`, `seaweed_salad`, `beet_salad`, and `greek_salad`). The majority of categories contain or are defined by animal-derived ingredients. Models fine-tuned on Food-101 and subsequently used for dietary classification tasks (e.g., identifying plant-based or vegetarian dishes) should be evaluated carefully: the skewed class distribution may cause such models to underperform on plant-based categories relative to their performance on the overall benchmark.
**Label noise in training split:** Training images were explicitly not cleaned, as noted by the original authors. Images sometimes carry incorrect labels or depict foods that visually resemble but differ from the target category. This noise affects the reliability of training signal, particularly for categories with high visual similarity.
**Photography style bias:** All images come from a social photography platform where users photograph prepared dishes in restaurant settings. Home-cooked meals, street food, or regional variations of the same dish may not be well captured. Image composition, lighting, and presentation style reflect the social photography norms of the early 2010s.
**Image recency:** Data was collected circa 2014. Food presentation styles, plating aesthetics, and the relative popularity of specific dishes have evolved since then.
### Other Known Limitations
- The training split intentionally contains noisy labels. Performance metrics computed on the training set are not reliable; only test-set metrics should be reported.
- With 250 test images per class, the benchmark may have insufficient statistical power to detect performance differences for rare presentation styles or long-tail variations within a category.
- The dataset does not include nutritional metadata, ingredient lists, or preparation method information. It cannot be used directly for nutrition analysis or ingredient detection without augmentation from external sources such as [Open Food Facts](https://world.openfoodfacts.org/) or [USDA FoodData Central](https://fdc.nal.usda.gov/).
- Extended benchmarks that include a broader range of international cuisines include [ETHZ Food-256](https://www.vision.ee.ethz.ch/datasets_extra/food-256/) (256 categories) and [UEC Food-100/256](http://foodcam.mobi/dataset.html) (Japanese cuisine focus).
## Additional Information
### Dataset Curators
The Food-101 dataset was created by Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool at ETH Zurich (Swiss Federal Institute of Technology), published at the European Conference on Computer Vision (ECCV) 2014. The dataset homepage is maintained by the Computer Vision Laboratory, ETH Zurich: https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/
### Licensing Information
LICENSE AGREEMENT
=================
- The Food-101 data set consists of images from Foodspotting [1] which are not
property of the Federal Institute of Technology Zurich (ETHZ). Any use beyond
scientific fair use must be negociated with the respective picture owners
according to the Foodspotting terms of use [2].
[1] http://www.foodspotting.com/
[2] http://www.foodspotting.com/terms/
### Citation Information
```
@inproceedings{bossard14,
title = {Food-101 -- Mining Discriminative Components with Random Forests},
author = {Bossard, Lukas and Guillaumin, Matthieu and Van Gool, Luc},
booktitle = {European Conference on Computer Vision},
year = {2014}
}
```
### Contributions
Thanks to [@nateraw](https://github.com/nateraw) for adding this dataset.
提供机构:
ethz
原始信息汇总
数据集概述
基本信息
- 数据集名称: Food-101
- 语言: 英语
- 许可证: 未知
- 多语言性: 单语种
- 数据集大小: 10K<n<100K
- 源数据集: 扩展自其他-foodspotting
- 任务类别: 图像分类
- 任务ID: 多类别图像分类
- PapersWithCode ID: food-101
- 美观名称: Food-101
数据集结构
特征
- 图像: 图像数据类型
- 标签: 分类标签,包含101个类别,如苹果派、婴儿背肋等。
数据分割
- 训练集: 75750个样本
- 验证集: 25250个样本
数据实例
json { "image": "<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x276021C5EB8>", "label": 23 }
数据集创建
数据集摘要
该数据集包含101个食品类别,共101,000张图片。每个类别有250张手动审核的测试图片和750张训练图片。训练图片未经清理,可能包含一些噪声,如颜色过于鲜艳或标签错误。所有图片已调整为最大边长512像素。
支持的任务和排行榜
- 图像分类: 目标是根据给定的菜品图像将其分类为101个类别之一。排行榜可在这里查看。
使用数据集的注意事项
社会影响
[更多信息需补充]
偏见讨论
[更多信息需补充]
其他已知限制
[更多信息需补充]
附加信息
数据集策展人
[更多信息需补充]
许可信息
数据集包含来自Foodspotting的图像,这些图像不属于联邦理工学院苏黎世分校(ETHZ)。超出科学合理使用的任何用途必须根据Foodspotting的使用条款与相应的图片所有者协商。
引用信息
@inproceedings{bossard14, title = {Food-101 -- Mining Discriminative Components with Random Forests}, author = {Bossard, Lukas and Guillaumin, Matthieu and Van Gool, Luc}, booktitle = {European Conference on Computer Vision}, year = {2014} }
贡献
感谢@nateraw添加此数据集。
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,构建细粒度图像分类基准数据集对于推动算法研究至关重要。Food-101数据集的构建源于从Foodspotting社交平台系统采集图像,该平台汇聚了大量用户上传的餐厅菜肴照片。数据收集过程涉及为101个食物类别各选取1000张图像,其中750张作为训练集,250张作为测试集。测试集图像经过人工审核确保标签准确性,而训练集则有意保留原始噪声,包括可能的错误标签和图像伪影,以模拟真实世界数据的复杂性。所有图像均被统一缩放,确保最大边长不超过512像素,为模型训练提供了标准化的输入尺寸。
使用方法
在应用Food-101数据集进行图像分类研究时,需遵循其特定的使用范式。研究者通常利用HuggingFace数据集库直接加载数据,数据集已预分为训练集和验证集,分别包含75,750和25,250个样本。标准流程涉及使用卷积神经网络等模型在训练集上进行训练,并在干净的验证集上评估性能,以准确衡量模型的泛化能力。鉴于训练集存在已知的标签噪声,建议采用噪声鲁棒性学习技术或专注于验证集指标。该数据集主要支持多类别图像分类任务,是开发和比较先进食物识别模型的基础资源,相关性能排行榜已在Papers with Code平台建立。
背景与挑战
背景概述
在计算机视觉领域,细粒度图像分类任务因其在类别间细微差异辨识上的高难度而备受关注。Food-101数据集由瑞士苏黎世联邦理工学院计算机视觉实验室的Lukas Bossard、Matthieu Guillaumin与Luc Van Gool团队于2014年构建,并发表于欧洲计算机视觉会议。该数据集旨在为食物图像识别建立一个具有挑战性的基准,其核心研究问题聚焦于如何让模型有效区分视觉上高度相似的不同菜肴,以及处理同一类别内因烹饪方式、食材搭配与拍摄角度所引发的巨大表观差异。通过涵盖101类常见食物、总计十万余张图像,Food-101迅速成为食物识别领域的重要评测标准,推动了餐饮推荐、膳食记录与营养分析等相关应用技术的发展。
当前挑战
Food-101数据集所应对的领域挑战在于细粒度食物图像分类,其难点体现在类间差异的微妙性与类内变化的多样性,例如不同面条类菜肴或各式披萨的精确区分。在构建过程中,数据集面临多重挑战:其一,数据来源于社交平台Foodspotting,训练集标签未经人工清洗,存在显著的标注噪声,可能影响模型学习的可靠性;其二,类别选择基于平台流行度,导致数据覆盖范围偏向北美与西欧菜系,未能充分体现全球饮食文化的多样性,引入了地理与文化的偏差;其三,图像均摄于餐厅环境,且反映2014年左右的摄影风格,难以泛化至家庭烹饪、街头小吃或当代餐饮呈现方式,限制了模型在现实场景中的适用性。
常用场景
经典使用场景
在计算机视觉领域,细粒度图像分类任务常面临类间差异细微、类内变化显著的挑战。Food-101数据集以其涵盖的101类常见菜肴图像,成为该领域经典的基准测试集。研究者通常利用其训练集与验证集,开发和评估深度卷积神经网络在复杂食物图像上的分类性能,尤其关注模型在存在标签噪声和视觉相似类别间的判别能力。
解决学术问题
该数据集有效解决了细粒度视觉识别中因类间相似度高而导致的分类困难问题。其精心设计的类别体系与带有噪声的训练数据,促使学术界探索更具鲁棒性的特征学习与模型正则化方法。通过提供大规模、真实场景的食物图像,它推动了迁移学习、领域自适应及噪声标签学习等研究方向的发展,为计算机视觉模型在复杂现实环境中的泛化能力评估设立了重要标准。
实际应用
基于Food-101训练的模型已广泛应用于智能餐饮与健康管理领域。例如,在移动应用中实现自动菜品识别,辅助用户进行饮食记录与营养分析;在餐厅场景中,支持菜单数字化与视觉搜索服务。这些应用不仅提升了用户体验,也为个性化膳食推荐与健康监测提供了技术基础,体现了计算机视觉技术从实验室走向日常生活的转化价值。
数据集最近研究
最新研究方向
在食品图像识别领域,Food-101数据集作为细粒度分类的经典基准,持续推动着计算机视觉前沿技术的发展。当前研究焦点集中于利用深度学习模型克服数据中固有的标签噪声与类别不平衡问题,例如通过自监督学习或噪声鲁棒训练策略提升模型在未清洗训练集上的泛化能力。同时,该数据集与健康计算、智能餐饮推荐等热点应用紧密结合,研究者正探索跨模态学习,将图像与营养成分或食谱文本关联,以支持膳食分析与个性化营养管理。鉴于数据集的西方饮食偏向,最新工作也致力于通过迁移学习或数据增强来扩展模型对全球多元菜系的识别范围,以促进更具包容性的食品AI系统发展。
以上内容由遇见数据集搜集并总结生成


