Rhetorical Roles Corpus
收藏arXiv2022-09-19 更新2024-06-21 收录
下载链接:
https://legal-nlp-ekstep.github.io/Competitions/Rhetorical-Role/
下载链接
链接失效反馈官方服务:
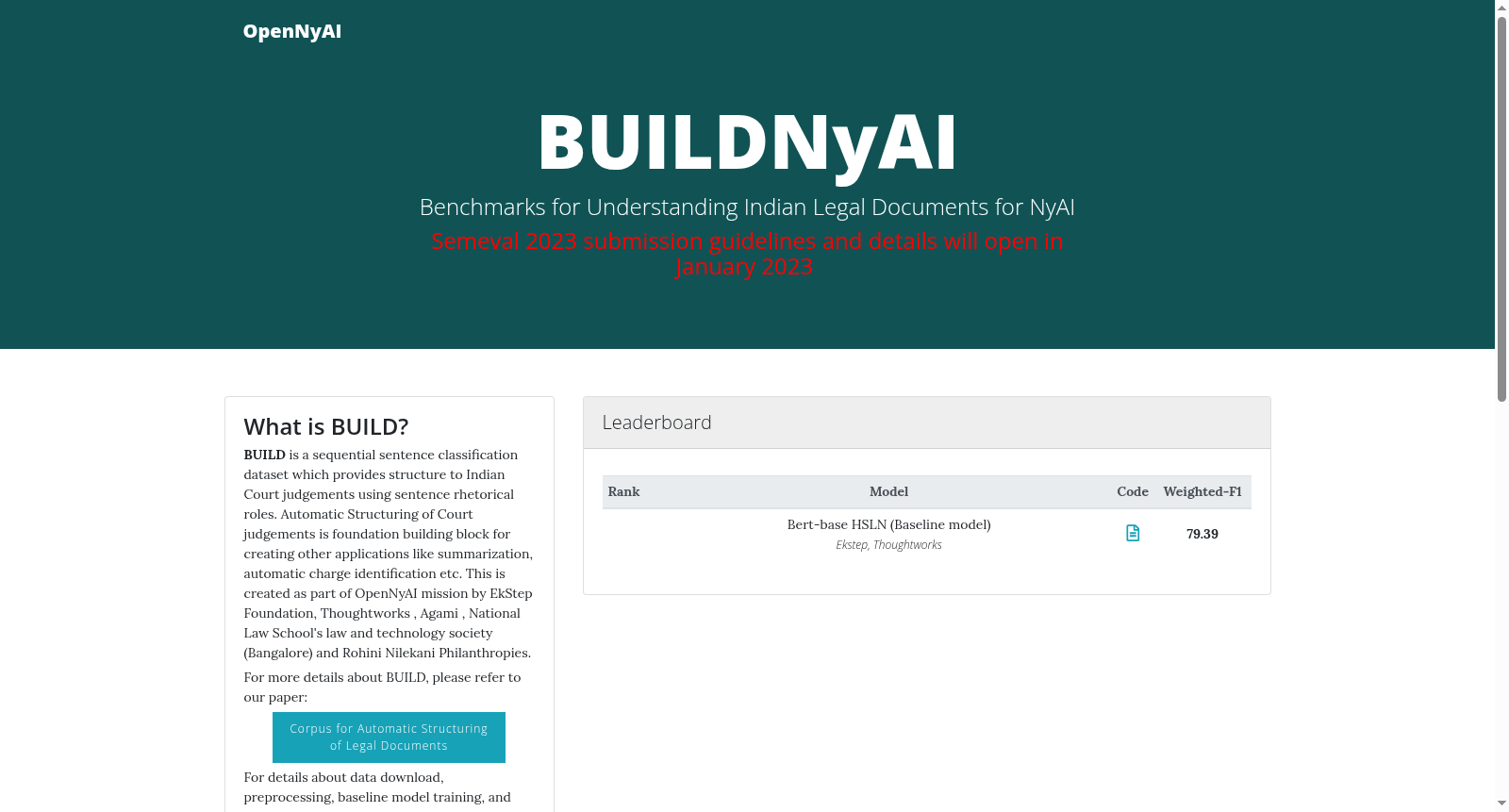
资源简介:
Rhetorical Roles Corpus是由EkStep Foundation创建的一个包含354份印度法律判决文件的数据集。该数据集的特点是将法律文件分割成主题连贯的部分,并为每个部分标注了12种预定义的修辞角色标签。数据集的创建旨在通过自然语言处理技术自动处理和组织法律文件,提高法律文件的可搜索性和可检索性。数据集的应用领域包括法律案例摘要和法律判决预测,旨在通过自动化技术辅助法律实践,加快司法系统的效率。
Created by the EkStep Foundation, the Rhetorical Roles Corpus is a dataset comprising 354 Indian legal judgment documents. A core characteristic of this dataset is that it segments legal documents into thematically coherent sections, with each section annotated with 12 pre-defined rhetorical role labels. The dataset was developed to automatically process and organize legal documents using natural language processing (NLP) technologies, thereby improving the searchability and retrievability of legal documents. Its application areas include legal case summarization and legal judgment prediction, with the objective of assisting legal practice via automated technologies and enhancing the efficiency of the judicial system.
提供机构:
EkStep Foundation
创建时间:
2022-01-31
搜集汇总
数据集介绍
构建方式
在法律自然语言处理领域,面对冗长且结构复杂的法律文书,构建高质量标注语料库是推动技术发展的基石。Rhetorical Roles Corpus的构建过程体现了严谨的学术协作与领域知识融合。该数据集通过众包方式,招募了来自印度多所法学院的学生志愿者,在法律专家和项目协调员的指导下完成标注。标注流程经过精心设计,包括志愿者筛选、大规模开放在线课程学习、校准训练、正式标注及最终裁决等多个阶段,以确保标注质量与一致性。标注对象为354份印度各级法院的英文判决书,共计40,305个句子,每个句子均被赋予12种预定义修辞角色或“NONE”标签中的一种,从而将非结构化的长文档转化为按语义连贯单元组织的结构化数据。
特点
该数据集的核心特点在于其规模、领域针对性与精细的语义标注。作为目前已知规模最大的法律修辞角色标注语料库,它涵盖了印度最高法院、高等法院及地方法院的判决,涉及刑事、税务等多个法律领域,并包含专门的跨领域测试集,为模型泛化能力评估提供了基础。其标注体系基于深入的法学讨论,定义了包括前言、事实、争议点、各方论点、分析、法律依据、先例引用、判决依据及当前法院裁决等在内的12种精细修辞角色,精准捕捉了法律文书的内在论证结构与语义功能。此外,数据集的构建充分考虑了法律文本的复杂性,采用句子级标注以平衡语义完整性与处理粒度,并通过计算Fleiss Kappa系数等方式对标注者间一致性进行了量化评估,确保了数据资源的可靠性与学术价值。
使用方法
该数据集主要服务于法律自然语言处理的研究与应用,其使用方法聚焦于模型训练、评估及下游任务增强。研究者可利用其训练集与验证集开发自动预测法律文书修辞角色的序列标注模型,例如论文中采用的基于SciBERT-HSLN的基线模型,并在提供的测试集上进行性能评估与比较。预测出的修辞角色结构可直接赋能多项下游任务:在文本摘要方面,可通过筛选特定角色(如争议点、判决依据、最终裁决)的句子构建抽取式摘要,或按角色分段后生成更高质量的生成式摘要;在法律判决预测任务中,可过滤出“分析”等关键角色的文本作为模型输入,以提升预测精度。数据集及相关代码已开源,为后续研究提供了可复现的基准与进一步探索的基础。
背景与挑战
背景概述
随着人口众多国家中待处理法律案件的指数级增长,自动化处理与组织法律文档的需求日益迫切。在此背景下,Rhetorical Roles Corpus应运而生,由EkStep基金会、Thoughtworks印度公司、Agami组织及印度坎普尔理工学院的研究团队于2022年共同创建。该数据集专注于法律自然语言处理领域,核心研究问题在于通过修辞角色标注实现法律判决文档的结构化分割,以支持自动摘要、判决预测等任务。作为目前规模最大的法律修辞角色标注语料库,它包含354份印度法律文档,共计40,305个句子,标注了12种修辞角色,显著推动了法律文本智能化处理的研究进展,并为后续模型开发提供了关键数据基础。
当前挑战
该数据集旨在解决法律文档自动结构化的领域挑战,包括法律文本长度冗长、信息分散、专业术语歧义以及文档噪声较多等问题,这些特性使得通用自然语言处理模型难以直接适用。在构建过程中,研究团队面临两大核心挑战:一是标注工作高度依赖法律专业知识,需协调大量法律专家与学生志愿者,并确保标注的一致性与质量;二是修辞角色本身存在语义模糊性,例如“分析”与“事实”、“论点”等角色易混淆,导致标注者间一致度仅为中等水平(Fleiss Kappa 0.59),且基线模型在跨领域泛化时性能出现显著下降。
常用场景
经典使用场景
在法律自然语言处理领域,Rhetorical Roles Corpus 为自动结构化法律文档提供了关键资源。该数据集通过将冗长的法律判决书分割为具有连贯主题的语义单元,并标注12种修辞角色,如事实陈述、争议焦点、法律分析等,为模型训练提供了精细的标注数据。其经典应用场景在于支持基于深度学习的修辞角色自动预测任务,研究者利用该数据集训练Transformer架构模型,实现法律文档的自动化语义分割,从而提升法律文本的理解与处理效率。
实际应用
在实际应用中,Rhetorical Roles Corpus 已被用于构建增强法律工作效率的工具。例如,在法律案例摘要生成中,利用预测的修辞角色筛选关键句子,能够提升抽取式摘要的准确性与连贯性;在判决预测任务中,通过聚焦于“分析”等核心修辞角色部分,模型能更有效地捕捉判决依据,提高预测性能。这些应用有助于法律从业者快速梳理案件脉络,辅助司法决策,在案件积压严重的司法体系中具有重要的实践价值。
衍生相关工作
基于该数据集,衍生了一系列重要的研究工作。例如,研究者在修辞角色预测任务上构建了SciBERT-HSLN等先进基线模型,并在公开排行榜上持续推动性能提升。同时,该数据集与ILDC等法律语料库的结合,促进了面向判决预测与解释的多任务学习框架发展。此外,相关工作还探索了修辞角色在法律文档检索、论据挖掘等任务中的迁移应用,逐步形成了以修辞角色为核心的法律文本分析研究脉络。
以上内容由遇见数据集搜集并总结生成


