IIIT 5K-Words
收藏cvit.iiit.ac.in2024-11-01 收录
下载链接:
http://cvit.iiit.ac.in/projects/SceneTextUnderstanding/IIIT5K.html
下载链接
链接失效反馈官方服务:
资源简介:
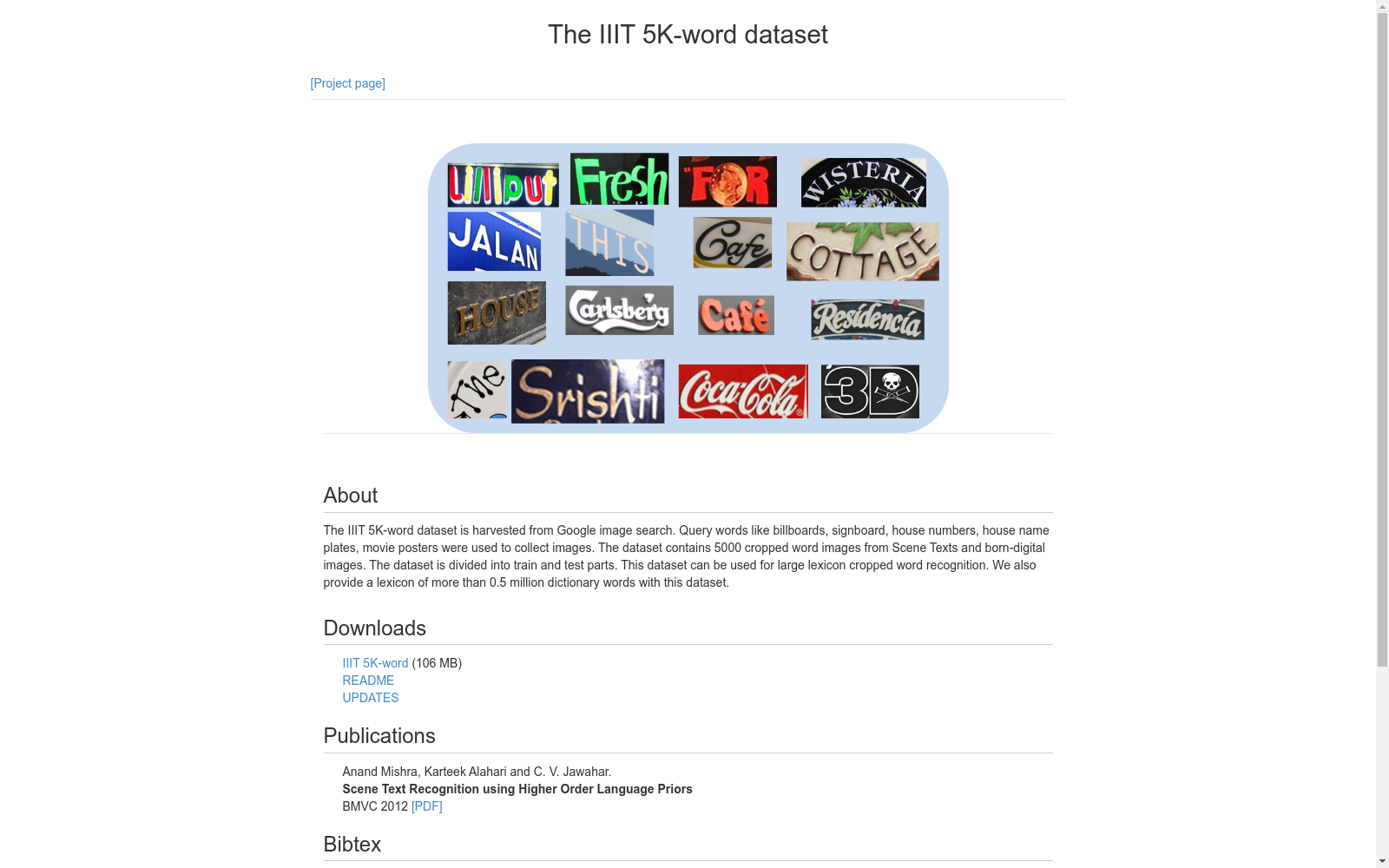
IIIT 5K-Words数据集是一个用于文本识别的图像数据集,包含5000张图像,每张图像包含一个单词。该数据集主要用于训练和评估文本识别算法。
The IIIT 5K-Words dataset is an image dataset tailored for text recognition tasks. It consists of 5000 images, each featuring exactly one word. This dataset is primarily used for training and evaluating text recognition algorithms.
提供机构:
cvit.iiit.ac.in
搜集汇总
数据集介绍
构建方式
在构建IIIT 5K-Words数据集时,研究者们精心挑选了来自不同字体、风格和背景的5000个单词图像。这些图像涵盖了多种语言和字符类型,确保了数据集的多样性和广泛性。通过使用先进的图像处理技术,研究者们对每个单词图像进行了标准化处理,包括尺寸调整、灰度转换和噪声过滤,以确保数据质量的一致性和可用性。此外,数据集还包含了每个单词的文本标签,为后续的机器学习和深度学习任务提供了丰富的标注信息。
特点
IIIT 5K-Words数据集以其高度的多样性和广泛的应用场景而著称。该数据集不仅包含了多种语言和字符类型的单词图像,还涵盖了不同的字体风格和背景条件,从而能够有效模拟现实世界中的文本识别挑战。此外,数据集的标注信息详尽且准确,为研究人员提供了可靠的训练和测试数据。其规模适中,既适合进行快速实验,也足以支持复杂的模型训练和验证。
使用方法
IIIT 5K-Words数据集主要用于文本识别和光学字符识别(OCR)领域的研究与开发。研究人员可以利用该数据集训练和验证各种文本识别模型,如卷积神经网络(CNN)和循环神经网络(RNN)。通过将数据集划分为训练集和测试集,研究者们可以评估模型的性能和泛化能力。此外,该数据集还可用于开发和测试新的图像处理和特征提取算法,以提高文本识别的准确性和鲁棒性。
背景与挑战
背景概述
IIIT 5K-Words数据集由印度国际信息技术研究所(IIIT)于2012年发布,旨在解决光学字符识别(OCR)领域中的复杂文本识别问题。该数据集包含了5000个从不同背景和字体中提取的单词图像,涵盖了多种语言和书写风格。IIIT 5K-Words的发布极大地推动了OCR技术的研究,特别是在处理多样化和复杂文本场景方面,为研究人员提供了一个标准化的测试平台。其影响力不仅限于学术界,还对工业界的OCR应用产生了深远影响,促进了相关技术的实际应用和商业化进程。
当前挑战
IIIT 5K-Words数据集在构建过程中面临了多重挑战。首先,收集和标注高质量的多样化文本图像是一项艰巨任务,涉及多种语言、字体和背景的复杂性。其次,数据集需要确保样本的广泛性和代表性,以覆盖实际应用中可能遇到的各种文本识别难题。此外,处理图像中的噪声、模糊和变形等问题,以及确保标注的准确性和一致性,也是构建过程中必须克服的挑战。这些挑战不仅考验了数据集构建者的技术能力,也推动了OCR领域技术的不断进步和创新。
发展历史
创建时间与更新
IIIT 5K-Words数据集由印度理工学院海得拉巴分校(IIIT Hyderabad)于2012年创建,旨在为场景文本识别研究提供一个标准化的基准。该数据集在创建后未有官方更新记录。
重要里程碑
IIIT 5K-Words数据集的发布标志着场景文本识别领域的一个重要里程碑。它包含了5000张从互联网上收集的图像,每张图像中包含一个单词,并附有相应的字符级标注。这一数据集的引入极大地推动了基于深度学习的场景文本识别算法的发展,为研究人员提供了一个统一的评估平台。此外,IIIT 5K-Words数据集还促进了多语言文本识别的研究,因为它包含了多种语言的文本样本。
当前发展情况
目前,IIIT 5K-Words数据集仍然是场景文本识别领域的一个重要参考基准。尽管近年来出现了更多复杂和大规模的数据集,如MJSynth和SynthText,IIIT 5K-Words依然因其简洁性和实用性而被广泛使用。它不仅用于评估现有算法的性能,还作为新算法开发的起点。此外,该数据集的成功应用也激发了更多针对特定场景和语言的文本识别数据集的创建,进一步推动了该领域的技术进步和应用扩展。
发展历程
- IIIT 5K-Words数据集首次发表,由印度国际信息技术研究所(IIIT)的研究团队创建,旨在解决光学字符识别(OCR)中的挑战。
- 该数据集首次应用于多个OCR研究项目中,显著提升了模型的识别准确率和鲁棒性。
- IIIT 5K-Words数据集被广泛接受为OCR领域的标准基准之一,促进了相关算法的快速发展和比较研究。
- 随着深度学习技术的进步,该数据集被用于训练和评估更复杂的神经网络模型,进一步推动了OCR技术的革新。
常用场景
经典使用场景
在光学字符识别(OCR)领域,IIIT 5K-Words数据集被广泛用于训练和评估文本识别模型。该数据集包含了5000个从不同背景和字体中提取的单词图像,涵盖了多种语言和字符类型。研究者们利用这一数据集进行深度学习模型的训练,以提高模型在复杂背景和多样化字体下的识别准确率。
解决学术问题
IIIT 5K-Words数据集解决了OCR领域中常见的多字体和多背景识别问题。通过提供多样化的训练样本,该数据集帮助研究者开发出更具鲁棒性的文本识别算法,从而在学术界推动了OCR技术的进步。其意义在于,它不仅提升了模型的泛化能力,还为后续研究提供了基准数据,促进了该领域的持续发展。
衍生相关工作
基于IIIT 5K-Words数据集,研究者们开发了多种改进的OCR模型,如基于卷积神经网络(CNN)和循环神经网络(RNN)的混合模型。这些模型在识别精度和处理速度上都有显著提升。此外,该数据集还激发了关于数据增强和迁移学习的研究,推动了OCR技术在多语言和多字体环境下的应用扩展。
以上内容由遇见数据集搜集并总结生成


