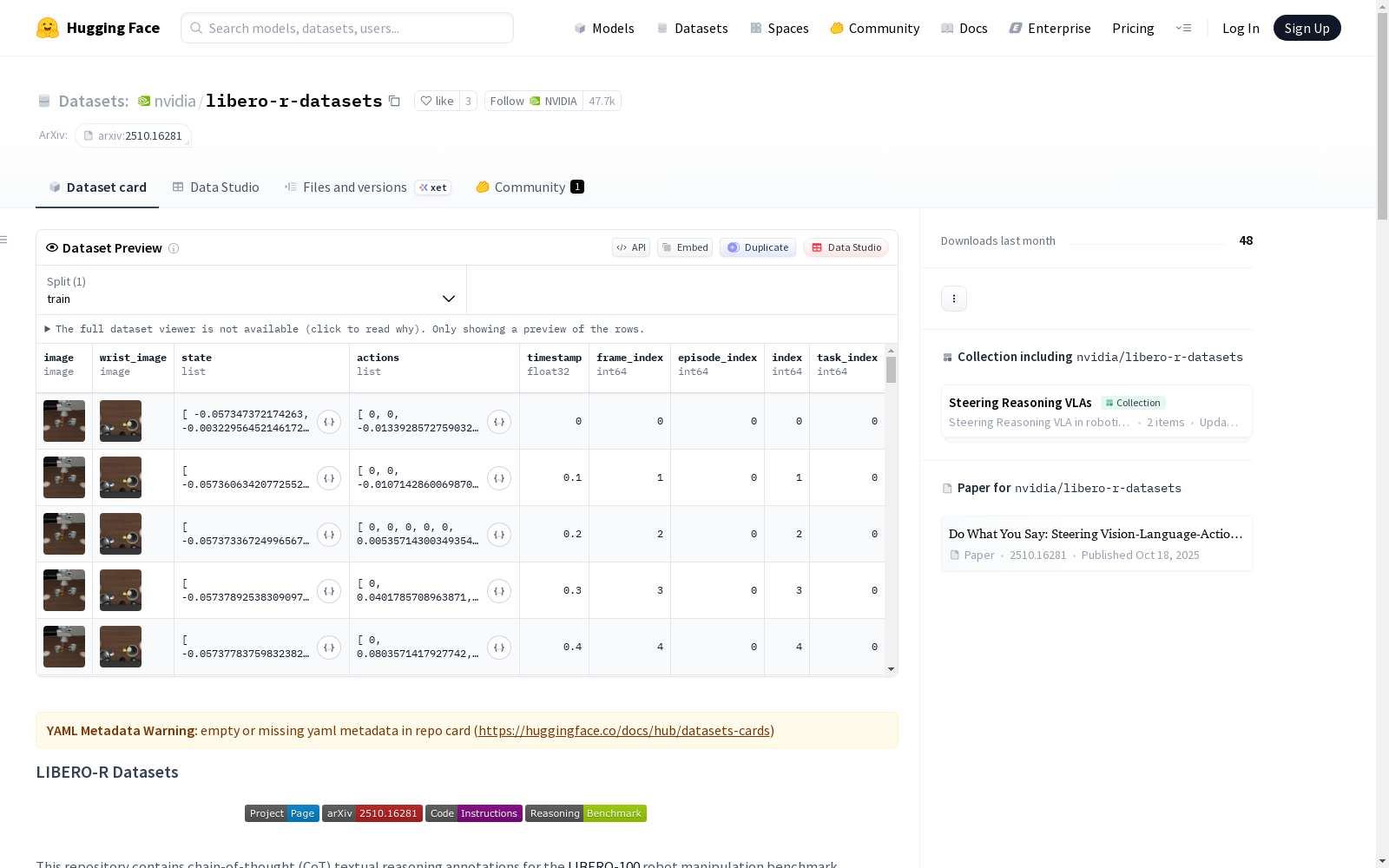
libero-r-datasets
收藏LIBERO-R 数据集概述
数据集简介
该数据集为机器人操作基准数据集 LIBERO-100 提供了逐步推理的链式思维文本标注。这些标注旨在将机器人操作任务分解为可执行的步骤。
数据集内容与结构
数据集包含三个主要部分:
- libero-10-r/:包含推理标注的 LIBERO-10 数据集。
- libero-100-basket-r/:LIBERO-100 数据集中与篮子相关任务的子集,包含推理标注。
- libero-100-r/:包含推理标注的完整 LIBERO-100 数据集。
每个部分均包含以下核心文件:
cot_simple.json:链式思维标注文件。data/:存储任务执行轨迹的 Parquet 文件目录。meta/:包含数据集元数据的目录(如 episodes.jsonl, info.json, stats.json, tasks.jsonl)。
标注格式与示例
标注的核心文件为 cot_simple.json,按任务执行片段组织,每个片段包含以下关键信息:
- Plan:完成指令所需的子任务编号列表。
- What I have done:已完成子任务的进度跟踪。
- Now I need to do:当前需要执行的下一步动作。
标注示例
对于一个指令为 “put the white mug on the left plate and put the yellow and white mug on the right plate” 的任务:
- 任务开始时:“Now I need to do: pick up the white mug”
- 完成第一个子任务后:“What I have done: 1. pick up the white mug” 与 “Now I need to do: place the white mug on the left plate”
- 任务完成时:“What I have done: 1. pick up the white mug 2. place the white mug on the left plate 3. pick up the yellow and white mug 4. place the yellow and white mug on the right plate” 与 “Now I need to do: Nothing. Task complete.”
JSON 结构
标注数据以 JSON 格式存储,结构示例如下: json { "episode_id": { "episode_start_interval": [start_step, end_step], "segments": [ { "start_step": 0, "end_step": 12, "content": "Current reasoning state...", "updated_content": "Updated reasoning after this segment...", "updated_content_w_instruction": "Full text including instruction..." } ] } }
相关资源
- 项目页面:https://yilin-wu98.github.io/steering-reasoning-vla/
- 论文:Yilin Wu, Anqi Li, Tucker Hermans, Fabio Ramos, Andrea Bajcsy, Claudia Pérez-DArpino: Do What You Say: Steering Vision-Language-Action Models via Runtime Reasoning-Action Alignment Verification, ArXiv 2025 (https://www.arxiv.org/abs/2510.16281)
- 代码:https://github.com/NVlabs/actalign
- 推理基准:https://github.com/NVlabs/Libero-10-r
引用信息
如果使用此数据集,请引用: bibtex @article{wu2025saysteeringvisionlanguageactionmodels, title={Do What You Say: Steering Vision-Language-Action Models via Runtime Reasoning-Action Alignment Verification}, author={Yilin Wu and Anqi Li and Tucker Hermans and Fabio Ramos and Andrea Bajcsy and Claudia P{e}rez-DArpino}, year={2025}, eprint={2510.16281}, archivePrefix={arXiv}, url={https://arxiv.org/abs/2510.16281}, }