Shekswess/mistral_medquad_instruct_dataset
收藏Hugging Face2024-04-13 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/Shekswess/mistral_medquad_instruct_dataset
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
size_categories:
- 10K<n<100K
task_categories:
- question-answering
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: instruction
dtype: string
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 47296307
num_examples: 16359
download_size: 17865039
dataset_size: 47296307
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- medical
---
Dataset made for instruction supervised finetuning of Mistral LLMs based on the Medquad dataset:
- Medquad dataset (https://www.kaggle.com/datasets/jpmiller/layoutlm)
## Medquad
MedQuAD is a comprehensive collection consisting of 47,457 medical question-answer pairs compiled from 12 authoritative sources within the National Institutes of Health (NIH), including domains like cancer.gov, niddk.nih.gov, GARD, and MedlinePlus Health Topics. These question-answer pairs span 37 distinct question types, covering a wide spectrum of medical subjects, including diseases, drugs, and medical procedures. The dataset features additional annotations provided in XML files, facilitating various Information Retrieval (IR) and Natural Language Processing (NLP) tasks. These annotations encompass crucial information such as question type, question focus, synonyms, Unique Identifier (CUI) from the Unified Medical Language System (UMLS), and Semantic Type. Moreover, the dataset includes categorization of question focuses into three main categories: Disease, Drug, or Other, with the exception of collections from MedlinePlus, which exclusively focus on diseases.
语言:
- 英语
样本规模区间:
- 10000 < 样本数量 < 100000
任务类别:
- 问答任务
数据集信息:
特征字段:
- 字段名:input,数据类型:字符串
- 字段名:output,数据类型:字符串
- 字段名:instruction,数据类型:字符串
- 字段名:prompt,数据类型:字符串
数据划分:
- 划分名称:训练集,字节数:47296307,样本数量:16359
下载大小:17865039
数据集总大小:47296307
配置项:
- 配置名称:默认,数据文件:
- 划分:训练集,路径:data/train-*
标签:
- 医疗领域
本数据集基于Medquad数据集构建,用于Mistral大语言模型(LLM)的指令监督微调。Medquad数据集可通过以下链接获取:https://www.kaggle.com/datasets/jpmiller/layoutlm
## Medquad 数据集
MedQuAD是一套全面的医疗问答对集合,共包含47457条问答样本,源自美国国立卫生研究院(National Institutes of Health,NIH)旗下12个权威数据源,涵盖cancer.gov、niddk.nih.gov、GARD以及MedlinePlus健康主题等多个领域。该数据集覆盖37种不同的问题类型,涉及疾病、药物、医疗操作等广泛的医学主题。
数据集附带XML格式的额外标注信息,可助力各类信息检索(Information Retrieval,IR)与自然语言处理(Natural Language Processing,NLP)任务。这些标注包含问题类型、问题焦点、同义词、统一医学语言系统(Unified Medical Language System,UMLS)中的唯一标识符(Unique Identifier,CUI)以及语义类型等关键信息。此外,数据集将问题焦点划分为疾病、药物及其他三大类别,但MedlinePlus数据源的样本集合仅聚焦于疾病主题。
提供机构:
Shekswess
原始信息汇总
数据集概述
基本信息
- 语言:英语
- 数据集大小:10K<n<100K
- 任务类别:问答
数据集特征
- 输入:字符串类型
- 输出:字符串类型
- 指令:字符串类型
- 提示:字符串类型
数据集划分
- 训练集:
- 示例数量:16359
- 数据大小:47296307字节
下载与数据集大小
- 下载大小:17865039字节
- 数据集总大小:47296307字节
配置
- 默认配置:
- 数据文件:
- 划分:训练
- 路径:data/train-*
- 数据文件:
标签
- 医疗
搜集汇总
数据集介绍
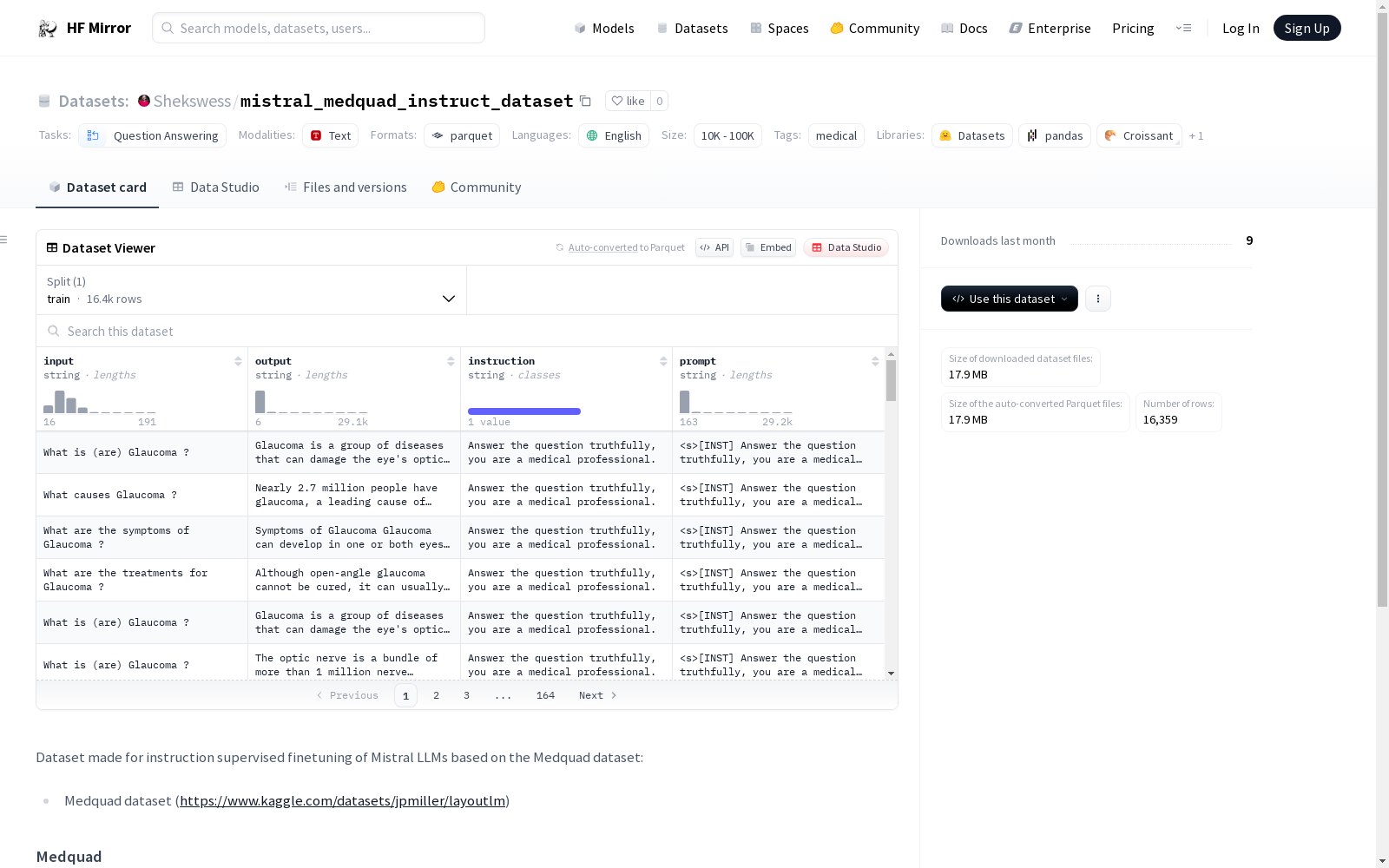
构建方式
Shekswess/mistral_medquad_instruct_dataset数据集的构建,是基于Medquad数据集进行的指令监督微调。Medquad数据集本身是由美国国立卫生研究院(NIH)的12个权威来源收集的47,457个医学问题-答案对组成,覆盖了37种不同的问题类型,涉及广泛的医学主题。本数据集通过选取Medquad中的问答对,并加入了特定的指令与提示文本,以适应Mistral大型语言模型的微调需求。
特点
该数据集的特点在于,它不仅包含了丰富的医学问答信息,还融合了针对特定任务的指令与提示,使得模型能够更好地理解和执行复杂的医学问答任务。此外,数据集的构建采用了XML格式的额外注释,为信息检索和自然语言处理任务提供了便利。在分类上,除MedlinePlus的集合外,问题焦点被分为疾病、药物或其他三大类,进一步增强了数据集的实用性。
使用方法
使用Shekswess/mistral_medquad_instruct_dataset数据集时,用户需先下载并解压数据集文件。随后,可以通过数据集提供的train split进行模型的训练。在训练过程中,用户应当关注输入、输出、指令和提示等字段的合理利用,以充分训练模型对医学问答任务的理解和应对能力。此外,数据集的XML注释也可以用于进一步的数据分析和任务扩展。
背景与挑战
背景概述
Shekswess/mistral_medquad_instruct_dataset 数据集,是在机器学习与医疗信息处理领域的一个里程碑。该数据集由Mistral LLMs的研究团队基于Medquad数据集创建于近年来,旨在为指令监督微调提供支持。Medquad数据集本身是源自12个权威的国立卫生研究院(NIH)资源,包含了47,457个医疗问题-答案对,跨越了37种不同的问题类型,涉及疾病、药物和医疗程序等多个医疗主题,为医学信息检索和自然语言处理任务提供了丰富的研究资源。
当前挑战
该数据集在构建过程中面临了诸多挑战,首先是数据的质量控制与一致性校验,确保每一对问题-答案都符合临床医学的严谨性。其次,由于涉及隐私问题,医疗数据的脱敏处理也是一大挑战。在研究领域,该数据集需要解决如何更精确地进行指令微调,以及如何处理和理解复杂的医学术语和语义关系的问题。此外,如何将此数据集应用于真实世界的医疗咨询场景,也是当前研究者和开发者需要克服的关键挑战。
常用场景
经典使用场景
在自然语言处理领域,Shekswess/mistral_medquad_instruct_dataset数据集被广泛应用于指令微调的精细训练。该数据集基于Medquad构建,利用其丰富的医学问答对,旨在提升大型语言模型如Mistral LLMs在医学信息检索与处理任务中的性能,特别是在遵循给定指令进行精准回答方面。
衍生相关工作
基于Shekswess/mistral_medquad_instruct_dataset的研究已经衍生出一系列相关工作,如改进的医学语言模型、专业的医学信息检索系统以及结合深度学习的医学问答系统等,这些研究进一步推动了医学信息处理技术的发展和医学服务的智能化。
数据集最近研究
最新研究方向
在医学信息检索与自然语言处理领域,Shekswess/mistral_medquad_instruct_dataset数据集的构建旨在推动指令微调的预训练语言模型在医疗问答任务中的应用。该数据集基于Medquad,整合了来自美国国立卫生研究院的权威资源,涵盖了丰富的医学问答对。近期研究聚焦于如何利用此数据集优化模型对医学相关指令的理解与执行能力,进而提升患者咨询、疾病解释及药物信息查询等场景的自动化服务水平。此类研究不仅推动了医疗信息获取的便捷性,也具有重要的社会与经济效益,对医疗健康领域的智能化发展影响深远。
以上内容由遇见数据集搜集并总结生成


