MOMIJI
收藏Hugging Face2025-05-13 更新2025-05-14 收录
下载链接:
https://huggingface.co/datasets/turing-motors/MOMIJI
下载链接
链接失效反馈官方服务:
资源简介:
MOMIJI是一个大规模的日语文档图像-文本交织数据集,包含5600万份文档、1100亿个字符和2.49亿张图像,用于训练大型视觉语言模型。
创建时间:
2025-04-30
原始信息汇总
MOMIJI 数据集概述
数据集描述
- 名称: MOMIJI (Modern Open Multimodal Japanese filtered Dataset)
- 语言: 日语 (ja)
- 许可证: CC-BY-4.0
- 规模: 10M < n < 100M
- 内容: 大规模、经过精心筛选的公开图像-文本交错网页文档数据集
- 来源: Common Crawl 2024年2月至2025年1月的转储数据
- 规模统计:
- 约56M日语文档
- 约110B字符
- 约249M图像
数据字段
每个样本包含以下字段:
| 字段名 | 类型 | 描述 |
|---|---|---|
docId |
str | 源自Common Crawl ID的唯一标识符 |
url |
str | 源网页URL |
text_list |
list<str> | 分割为单独片段的文档文本 |
text |
str | 包含图像占位符的完整文本 |
image_info |
list<dict> | 图像元数据列表,包含:<br>• placeholder (str)<br>• url (str)<br>• original_width / original_height (int)<br>• exif (dict, 可选)<br>• alt (str, 可选) |
规模与统计
- 文档数量: 56,119,639
- 图像数量: 249,745,953
- 总字符数: 109,980,725,957
- 平均字符数/文档: 1,959
- 平均图像数/文档: 4.45
使用许可
- 允许用途:
- 机器学习模型训练、评估和审计
- 自动摘要、文本挖掘、统计分析等非消费性研究
- 禁止用途:
- 以人类可读形式重新分发全文
- 公开传播、广播或以其他方式使原始或修改后的文本/图像可供人类消费
- 以允许重建或识别的方式引用或嵌入原始作品
许可信息
- 元数据(包括YAML头、统计表和文档)采用CC-BY-4.0许可
- 底层网页文本和图像仍受各自版权持有者约束
注意事项
- 数据集不包含图像二进制文件,仅包含链接和元数据
- 尽管应用了NSFW过滤器,但仍可能包含令人不适的内容
- 数据集仅用于科学研究或安全分析
致谢
基于新能源产业技术综合开发机构(NEDO)资助项目JPNP20017的成果
搜集汇总
数据集介绍
构建方式
在构建现代多模态数据集MOMIJI的过程中,研究团队从2024年2月至2025年1月的Common Crawl网络存档中系统性地提取了约5600万份日语文档。通过精心设计的过滤流程,该数据集整合了文本与图像交织的网页内容,形成包含1099亿字符文本和2.49亿张图像的大规模语料库。这种构建方法特别注重保持原始文档中图文交替的天然结构,为视觉语言模型训练提供了高质量的多模态数据基础。
特点
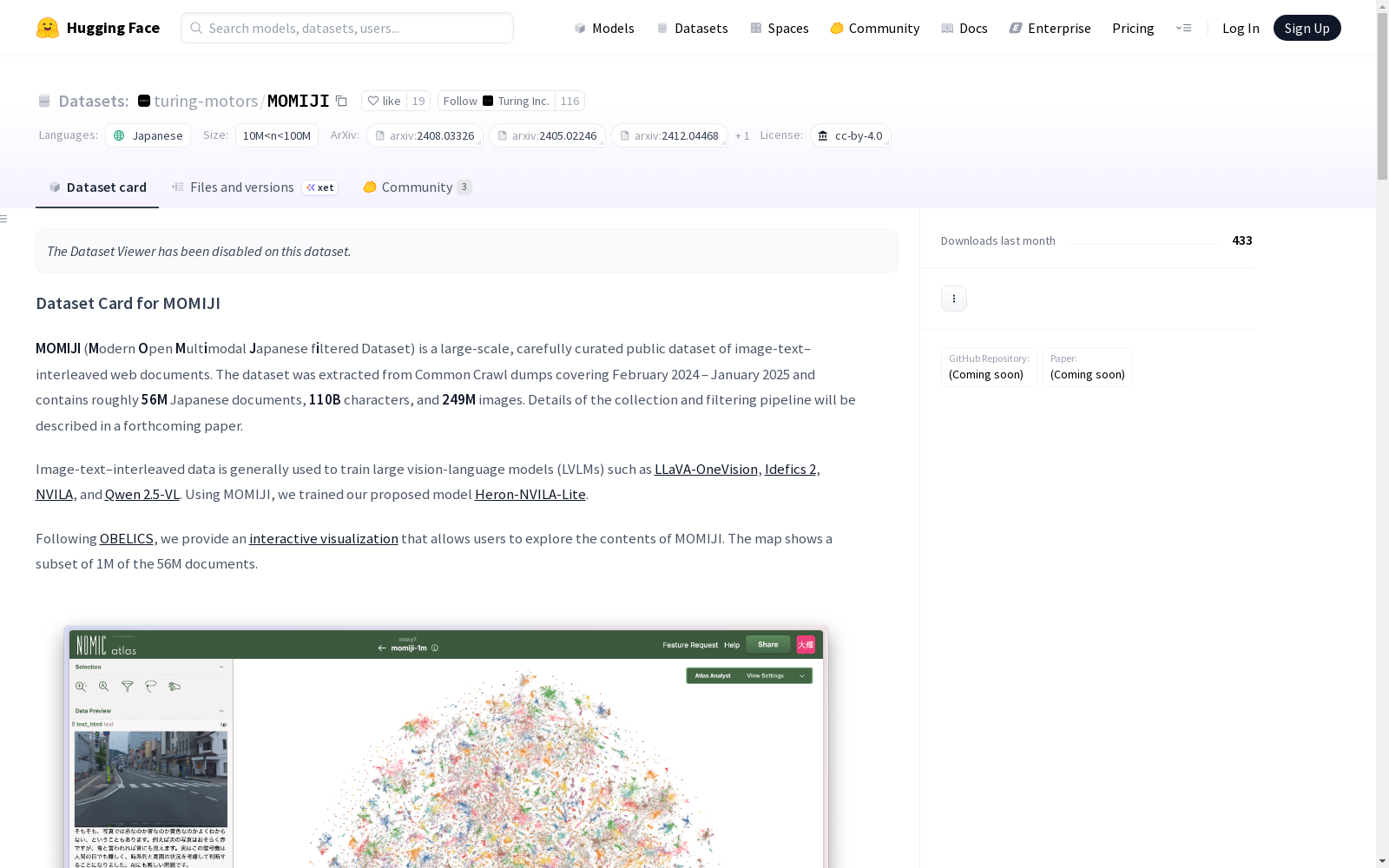
MOMIJI数据集最显著的特征在于其纯日语多模态文档的丰富性,平均每份文档包含4.45张图像并具有1959个字符的文本量。数据集通过独特的图文交织格式呈现内容,其中图像信息以结构化元数据形式存储,包含尺寸、替代文本和EXIF数据等关键属性。特别值得关注的是,该数据集通过交互式可视化平台提供了百万级文档的探索功能,使研究者能够直观把握数据分布特征。
使用方法
使用MOMIJI数据集时需通过专用工具momiji_generator动态生成文本字段,该工具能将原始URL数据转换为包含图文占位符的完整文档。根据日本著作权法第30-4条规定,数据集仅限用于信息分析目的,包括机器学习模型训练与评估等非消费性研究。研究者应注意数据集不包含图像二进制文件,仅提供元数据链接,且需自行承担内容访问风险。
背景与挑战
背景概述
随着多模态人工智能技术的快速发展,大规模图文交错数据成为训练先进视觉语言模型的关键资源。MOMIJI数据集由Turing Motors等机构于2024-2025年间构建,基于Common Crawl网络爬虫数据,收录了约5600万份日语文档、2.49亿张图像及1100亿字符文本。该数据集专门针对日语多模态理解任务设计,通过精细的数据清洗流程为视觉语言模型训练提供高质量语料,其创新性体现在对日语文化语境下图文关联模式的深度挖掘,为跨模态表示学习研究奠定了重要基础。
当前挑战
在视觉语言模型训练领域,如何有效建模图文交错文档中的跨模态语义关联始终是核心难题。MOMIJI构建过程中面临双重挑战:技术层面需解决网页原始数据的噪声过滤问题,包括非结构化文本解析、低质量图像识别以及图文对齐关系验证;法律合规层面则需严格遵循日本著作权法第三十条之四的规定,确保数据仅用于信息分析目的。此外,数据集仅提供图像元数据而缺乏二进制文件的实际分布策略,也为下游应用带来了数据完整性与可复现性的考验。
常用场景
经典使用场景
在视觉语言模型研究领域,MOMIJI数据集作为大规模日语图文交错数据的代表,主要应用于训练先进的大规模视觉语言模型。其精心筛选的5600万份文档与2.49亿张图像构成的语料库,为模型学习图文关联性提供了丰富素材。通过动态生成的文本段落与图像占位符的有机组合,研究者能够构建具有复杂推理能力的多模态系统,例如在文档理解任务中实现文本与视觉元素的协同解析。
解决学术问题
该数据集有效解决了多模态学习中的语言资源不平衡问题,为日语语境下的视觉语言理解研究提供了关键基础设施。通过覆盖2024至2025年度的网络文档,它克服了传统日语数据集中存在的时效性局限与规模瓶颈。其严格的过滤流程确保了数据质量,为研究社区探索跨模态表示学习、零样本迁移等前沿课题奠定了坚实基础,显著推进了非英语多模态模型的发展进程。
衍生相关工作
该数据集的发布催生了系列创新研究,其中NVILA、Qwen 2.5-VL等模型架构通过借鉴其数据构建范式,实现了多模态理解的突破。受OBELICS可视化系统的启发,研究者开发了交互式探索工具,使56万文档的子集可通过语义映射进行直观分析。这些衍生工作不仅验证了数据集的工程价值,更形成了从数据构建到模型优化的完整技术链条,持续推动着多模态人工智能生态的发展。
以上内容由遇见数据集搜集并总结生成


