nq-hardnegatives
收藏Hugging Face2025-04-25 更新2025-04-26 收录
下载链接:
https://huggingface.co/datasets/bobox/nq-hardnegatives
下载链接
链接失效反馈官方服务:
资源简介:
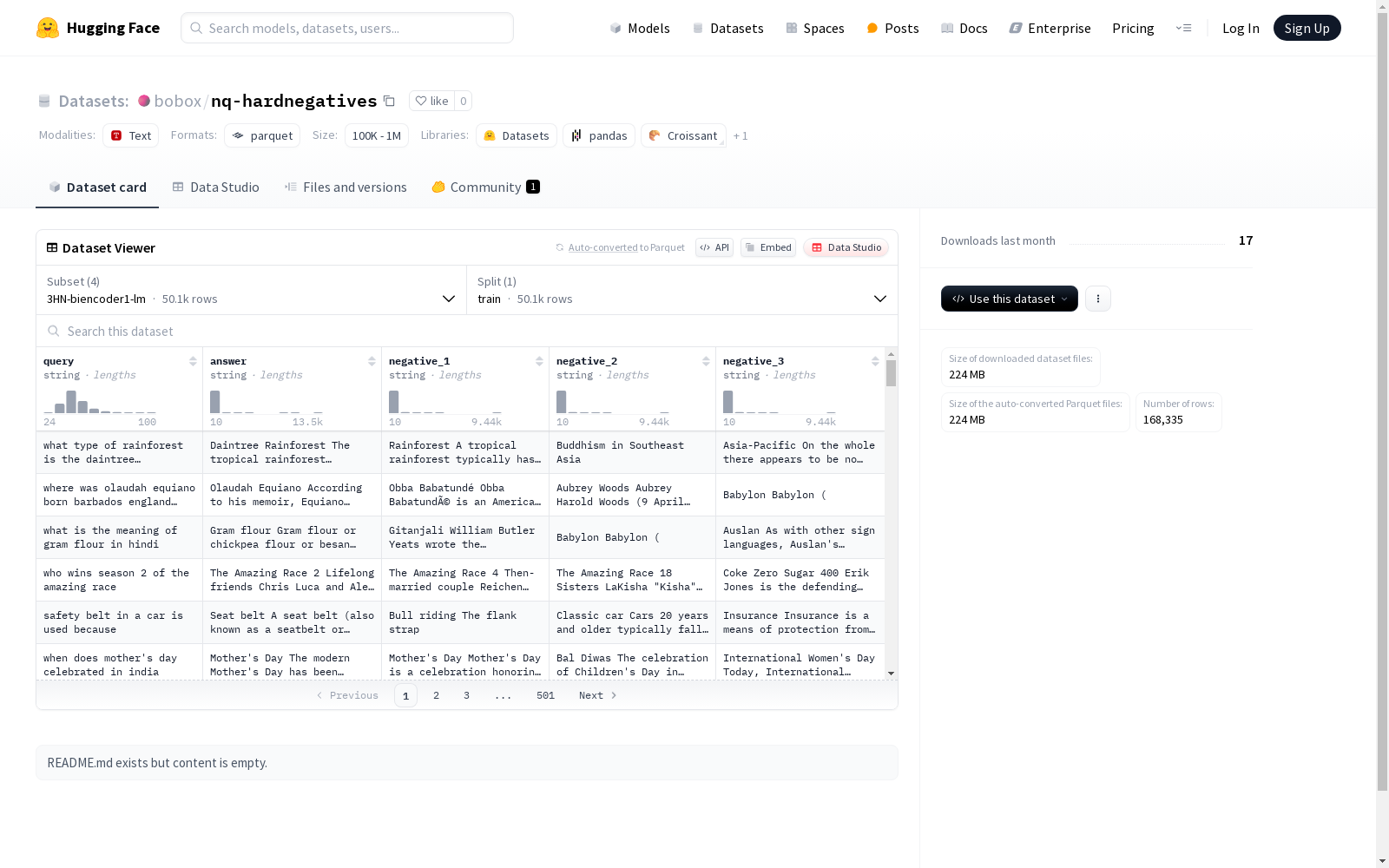
该数据集包含查询(query)、答案(answer)和五个负例(negative_1, negative_2, negative_3, negative_4, negative_5)。数据集分为3HN-biencoder1-lm、3HN-biencoder2-lm、biencoder和test四个配置,每个配置都有训练集(train)。3HN-biencoder1-lm和3HN-biencoder2-lm的训练集分别包含50089和99241个示例,而biencoder和test的训练集分别包含13279和5726个示例。数据集用于训练可能涉及排序或检索的模型。
创建时间:
2025-04-25
搜集汇总
数据集介绍
构建方式
nq-hardnegatives数据集基于自然问答任务构建,通过精心设计的负采样策略增强模型对困难样本的区分能力。该数据集包含多个配置版本,其中3HN-biencoder1-lm和3HN-biencoder2-lm分别包含50,089和99,241条训练样本,每条数据由查询语句、正确答案及3个高混淆度的负例答案组成。biencoder和test配置则扩展至5个负例,通过分层抽样确保负例与正例在语义和句法上的高相似性,从而提升模型在真实场景中的鲁棒性。
特点
该数据集的核心价值在于其精心筛选的困难负例,这些负例与正确答案具有高度语义相关性,能够有效模拟真实问答系统中的挑战性场景。不同配置版本覆盖了从基础到进阶的训练需求,其中3HN-biencoder2-lm版本规模最大,包含近10万条样本,为模型提供丰富的对比学习素材。数据字段设计简洁明晰,query-answer-negative三元组结构便于直接应用于双编码器或交叉编码器的训练流程。
使用方法
使用者可根据具体任务需求选择对应配置,3HN-biencoder版本适合基础对比学习训练,而含5个负例的biencoder配置更适合需要更高判别力的场景。数据以标准JSON格式存储,加载后可直接输入至BERT等预训练模型进行微调。建议结合硬负例挖掘策略动态调整负例权重,或通过多任务学习框架联合优化查询和答案的嵌入表示。测试集包含5,726条样本,可用于评估模型在困难负例下的泛化性能。
背景与挑战
背景概述
nq-hardnegatives数据集是自然语言处理领域中针对问答系统优化的关键资源,专注于提升信息检索与答案匹配的精确度。该数据集由专业研究团队构建,旨在解决开放域问答系统中负样本选择对模型性能的影响问题。通过精心设计的负样本策略,该数据集为训练更鲁棒的问答模型提供了重要支持,显著推动了问答系统在复杂语境下的表现。其结构化的查询-答案对及多样化负样本设计,已成为评估和改进双编码器模型的重要基准。
当前挑战
nq-hardnegatives数据集面临的挑战主要集中在两个方面:领域问题的挑战在于如何有效区分高度相似的负样本与真实答案,这对模型的语义理解能力提出了极高要求;构建过程中的挑战则源于负样本的筛选与标注,需要确保负样本既具有足够的迷惑性又不偏离问题语境,这一过程耗费大量计算与人工成本。此外,数据集的规模与多样性平衡也是构建时需谨慎考虑的关键因素。
常用场景
经典使用场景
在信息检索与自然语言处理领域,nq-hardnegatives数据集通过提供查询-答案对及精心筛选的负样本,为双编码器模型的训练与评估提供了标准化基准。其结构化设计特别适用于对比学习框架,模型通过区分正确答案与语义相近的干扰项,能够有效学习文本表示的细粒度差异。
解决学术问题
该数据集显著缓解了密集检索系统中负样本质量不足的瓶颈问题。传统方法依赖随机负采样易导致模型陷入局部最优,而nq-hardnegatives提供的困难负样本(hard negatives)迫使模型区分语义高度相关的干扰项,从而提升了对查询意图的理解能力,为稠密向量检索的精度突破提供了数据支撑。
衍生相关工作
该数据集催生了多个稠密检索领域的里程碑式研究,如ANCE(Approximate Nearest Neighbor Negative Contrastive Learning)通过动态硬负采样策略优化表示空间,以及RocketQA提出的跨批次负样本挖掘技术。这些工作均采用nq-hardnegatives作为核心评估基准,推动了端到端检索模型的性能边界。
以上内容由遇见数据集搜集并总结生成


