RicardoRei/wmt-sqm-human-evaluation
收藏Hugging Face2023-02-17 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/RicardoRei/wmt-sqm-human-evaluation
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
size_categories:
- 1M<n<10M
language:
- cs
- de
- en
- hr
- ja
- liv
- ru
- sah
- uk
- zh
tags:
- mt-evaluation
- WMT
- 12-lang-pairs
---
# Dataset Summary
In 2022, several changes were made to the annotation procedure used in the WMT Translation task. In contrast to the standard DA (sliding scale from 0-100) used in previous years, in 2022 annotators performed DA+SQM (Direct Assessment + Scalar Quality Metric). In DA+SQM, the annotators still provide a raw score between 0 and 100, but also are presented with seven labeled tick marks. DA+SQM helps to stabilize scores across annotators (as compared to DA).
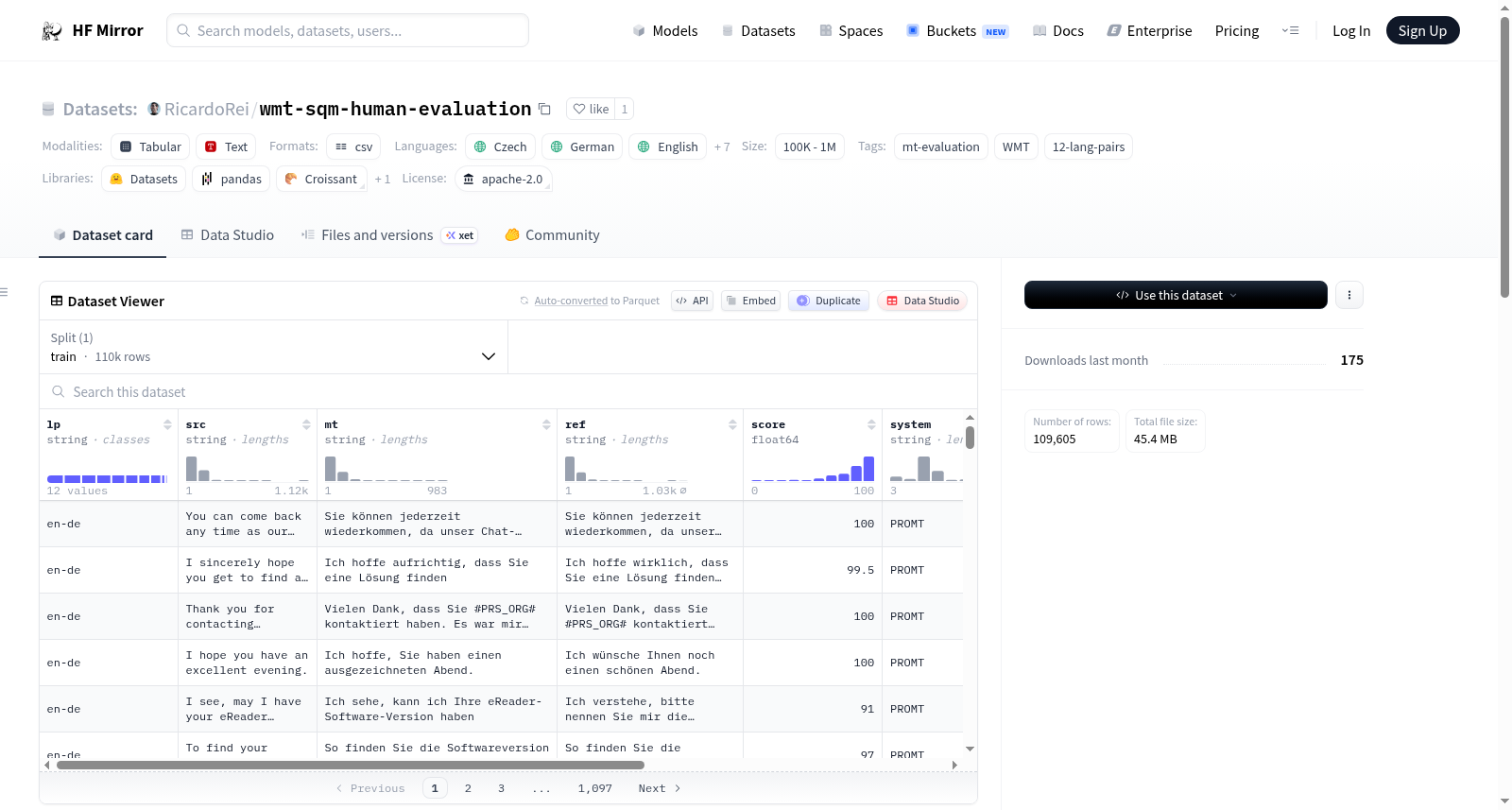
The data is organised into 8 columns:
- lp: language pair
- src: input text
- mt: translation
- ref: reference translation
- score: direct assessment
- system: MT engine that produced the `mt`
- annotators: number of annotators
- domain: domain of the input text (e.g. news)
- year: collection year
You can also find the original data [here](https://www.statmt.org/wmt22/results.html)
## Python usage:
```python
from datasets import load_dataset
dataset = load_dataset("RicardoRei/wmt-sqm-human-evaluation", split="train")
```
There is no standard train/test split for this dataset but you can easily split it according to year, language pair or domain. E.g. :
```python
# split by year
data = dataset.filter(lambda example: example["year"] == 2022)
# split by LP
data = dataset.filter(lambda example: example["lp"] == "en-de")
# split by domain
data = dataset.filter(lambda example: example["domain"] == "news")
```
Note that, so far, all data is from [2022 General Translation task](https://www.statmt.org/wmt22/translation-task.html)
## Citation Information
If you use this data please cite the WMT findings:
- [Findings of the 2022 Conference on Machine Translation (WMT22)](https://aclanthology.org/2022.wmt-1.1.pdf)
提供机构:
RicardoRei
原始信息汇总
数据集概述
数据集基本信息
- 许可: Apache-2.0
- 大小: 1M<n<10M
- 语言:
- cs
- de
- en
- hr
- ja
- liv
- ru
- sah
- uk
- zh
- 标签:
- mt-evaluation
- WMT
- 12-lang-pairs
数据集内容
- 组织结构: 数据集包含8个列,分别是:
- lp: 语言对
- src: 输入文本
- mt: 翻译文本
- ref: 参考翻译
- score: 直接评估分数
- system: 生成
mt的MT引擎 - annotators: 标注者数量
- domain: 输入文本的领域(例如:新闻)
- year: 收集年份
数据集使用
-
Python示例: python from datasets import load_dataset dataset = load_dataset("RicardoRei/wmt-sqm-human-evaluation", split="train")
-
数据分割: 无标准训练/测试分割,可根据年份、语言对或领域进行分割。
引用信息
- 若使用此数据集,请引用WMT的研究成果:
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是WMT 2022机器翻译任务的人类评估数据,采用DA+SQM注释方法,包含多种语言对的源文本、机器翻译、参考翻译和0-100评分。它用于评估机器翻译系统性能,涵盖多个领域(如新闻、对话),数据规模约为10万行,适用于机器翻译质量分析和模型训练。
以上内容由遇见数据集搜集并总结生成


