nrl-ai/vn-spell-correction-eval-real
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/nrl-ai/vn-spell-correction-eval-real
下载链接
链接失效反馈官方服务:
资源简介:
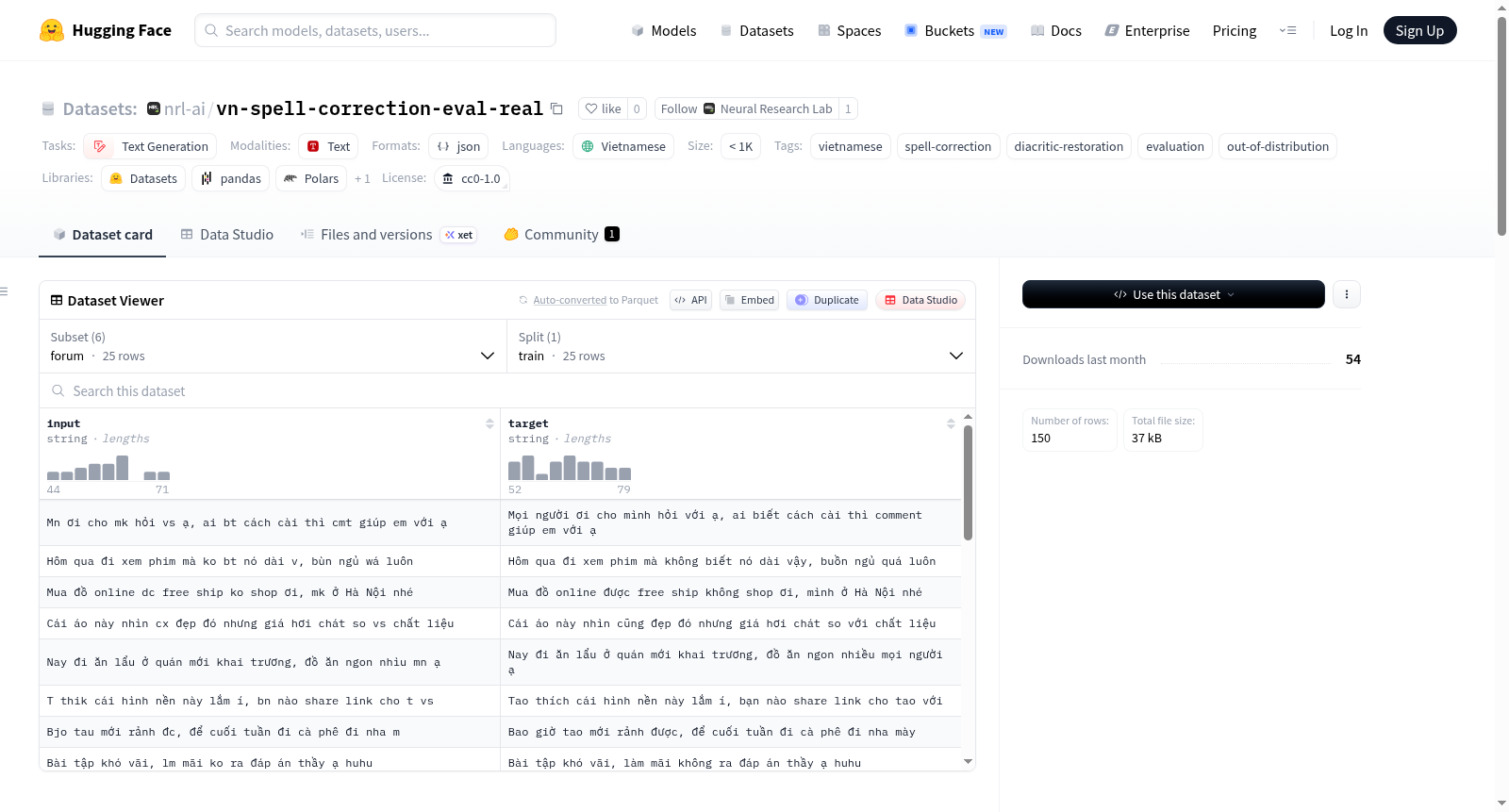
越南语拼写纠正非分布评估数据集(150个句子,6种来源)。该数据集包含手工整理的(有噪声,干净)句子对,噪声模式来自真实的越南语错误来源,而非合成噪声生成器。数据集分为6个配置,分别对应不同的噪声来源和测试目标,包括论坛/社交媒体帖子的缩写、手机输入法的自动纠正错误、真实的Telex/VNI键盘输入错误、OCR引擎输出错误、法律文件中的重音符号缺失以及新闻标题/正文中的重音符号缺失。每个配置包含25个句子,总计150个句子。数据集的设计目的是作为非分布评估的补充,与合成噪声生成的评估数据集区分开来。
Vietnamese spell-correction out-of-distribution evaluation dataset (150 sentences, 6 registers). The dataset contains hand-curated (noisy, clean) pairs whose noise patterns come from real Vietnamese error sources, not from a synthetic noise generator. It is divided into 6 configurations, each corresponding to different noise sources and test objectives, including abbreviations in forum/social-media posts, autocorrect mishaps in phone-typing, real Telex/VNI keystroke artefacts, OCR engine output errors, diacritic-stripped legal documents, and diacritic-stripped news headlines/body. Each configuration contains 25 sentences, totaling 150 sentences. The dataset is designed as the out-of-distribution complement to the in-distribution synthetic evaluation dataset.
提供机构:
nrl-ai
搜集汇总
数据集介绍
构建方式
该数据集旨在为越南语拼写校正模型提供一种真实的分布外评估基准。其构建过程避开了传统的合成噪声生成方式,转而从实际越南语错误来源中手工精挑细选出150对含噪与正确文本配对。数据覆盖六大现实场景:论坛与社交媒体中的青少年缩写及缺声调文本、手机键盘自动纠错产生的错误、真实Telex或VNI输入法击键错误、光学字符识别系统在扫描文档上的输出、缺失声调的越南语法律文本,以及同样缺失声调的新闻内容。每对数据均以UTF-8 NFC格式存储为JSON对象,确保编码一致性。
特点
该语料库的核心价值在于其真实性、多样性及对模型泛化能力的严峻拷问。每类配置仅含25个样本,统计上存在一定波动,但精准反映了现实世界噪声的复杂分布。尤为关键的是,它暴露了当前主流越南语拼写校正模型在Telex输入法错误这一“灾难性领域”上的显著短板(词准确率仅18%),相较于OCR或新闻领域的高分表现形成了鲜明反差。数据集明确标注为分布外测试集,旨在检验模型是否对合成训练数据产生了过拟合,而无法泛化至真实场景。
使用方法
该数据集可通过HuggingFace的datasets库直接加载,以六大配置分别调用,如'forum'或'ocr'。每个配置返回的训练集包含25条样本。使用时,用户可结合Transformers库,加载预训练的序列到序列模型进行推理。例如,将含噪输入文本经分词器处理后输入模型,并解码生成校正后的输出,进而与标准答案比对以计算准确率。值得注意的是,数据集规模较小,统计置信区间较宽,更适合作为方向性的“嗅觉测试”而非严格的排行榜基准。
背景与挑战
背景概述
越南语拼写校正领域长期受困于合成噪声数据的性能高估问题,现有模型在真实场景中常表现不佳。为应对这一挑战,Neural Research Lab的Viet-Anh Nguyen等人于2026年构建了vn-spell-correction-eval-real数据集,聚焦于检测模型在分布外真实噪声上的泛化能力。该数据集包含150条精心人工标注的(噪声-正确)文本对,覆盖论坛社交缩写、手机键盘纠错、Telex输入法误触、OCR扫描错误、法律文本去音调以及新闻去音调六类实源噪声。作为nom-vn项目的核心评估基准,它揭示了现有模型在Telex输入法上的灾难性缺陷(仅18%词汇准确率),促使研究者重新审视训练数据分布与真实噪声之间的鸿沟,对推动越南语拼写校正技术的落地具有标杆意义。
当前挑战
该数据集直面两大核心挑战。其一,领域问题层面,现有拼写校正模型多依赖合成噪声训练,在真实场景中因输入噪声模式多样且分布不均而泛化失败,例如社交媒体的缩写变体与Telex输入法的韵律标记错乱难以通过模拟生成。其二,构建过程中,数据集规模仅150条导致统计噪声显著(各分片词汇准确率95%置信区间±9个百分点),无法支撑精细的排行榜评估;同时,噪声文本涉及平台用户隐私,无法逐条追溯原始来源,需兼顾公共利益与合规性;此外,论坛俚语如“vcl”等随语言演变迅速老化,数据集需周期性更新以避免评测结果失真。
常用场景
经典使用场景
在越南语拼写校正领域,模型性能的评估长期依赖于合成噪声数据,这导致模型在真实场景中的泛化能力成疑。vn-spell-correction-eval-real数据集专为评估拼写校正模型的泛化能力而设计,涵盖了论坛社交媒体、手机键盘自动纠错、Telex/VNI输入法错误、光学字符识别(OCR)输出、法律文本以及新闻标题与正文六大真实噪声来源。该数据集的核心用途在于检验模型是否过度拟合于特定的噪声生成器,从而揭示其在真实世界、分布外场景下的真实表现,为模型的鲁棒性提供关键诊断。
实际应用
在实际应用中,该数据集为越南语拼写校正系统在多种真实场景下的部署提供了关键性能参照。例如,在社交媒体内容审核中,论坛和Telex配置的数据可检验模型对青少年缩写和输入法误触的校正能力;在文档数字化流程中,OCR配置的数据用于评估模型对扫描件输出错误的容错性;在法律和新闻领域,数据集有助于验证系统在处理缺失声调符号文本时的纠正精度。通过定向评估各子集,工程师能够识别模型在特定场景下的薄弱环节,从而进行针对性优化,提升产品的用户体验。
衍生相关工作
该数据集衍生了一系列聚焦于越南语拼写校正模型鲁棒性评价的相关工作。首先,研究者利用该数据集对现有的公开模型(如nrl-ai/vn-spell-correction-base)进行了基准测试,揭示了其在Telex输入法错误登记上的灾难性弱点,为后续模型改进明确了方向。其次,数据集中的六大子集被用于分析不同噪声类型对模型性能的影响,催生了针对特定噪声源的专用优化方案。此外,该数据集与nom-vn项目深度绑定,作为其评估流水线的核心组件,推动了越南语拼写校正领域从依赖合成测试向拥抱真实评估范式的转变。
以上内容由遇见数据集搜集并总结生成


