HAUSANLP1
收藏arXiv2025-05-20 更新2025-05-22 收录
下载链接:
https://catalog.hausanlp.org
下载链接
链接失效反馈官方服务:
资源简介:
HAUSANLP1是一个精心策划的目录,汇集了数据集、工具和研究工作,旨在增强可访问性并推动Hausa自然语言处理(NLP)的进一步发展。该目录作为发现和共享数据集、工具和论文的动态资源,不断从世界各地的研究人员和实践者那里获得贡献。
提供机构:
Imperial College London, Northeastern University, DSFSI, University of Pretoria, Kaduna State University, Kalinga University, Bayero University, Kano, Universiti Teknologi PETRONAS, University of the Witwatersrand, Johannesburg, Federal University of Lafia
创建时间:
2025-05-20
搜集汇总
数据集介绍
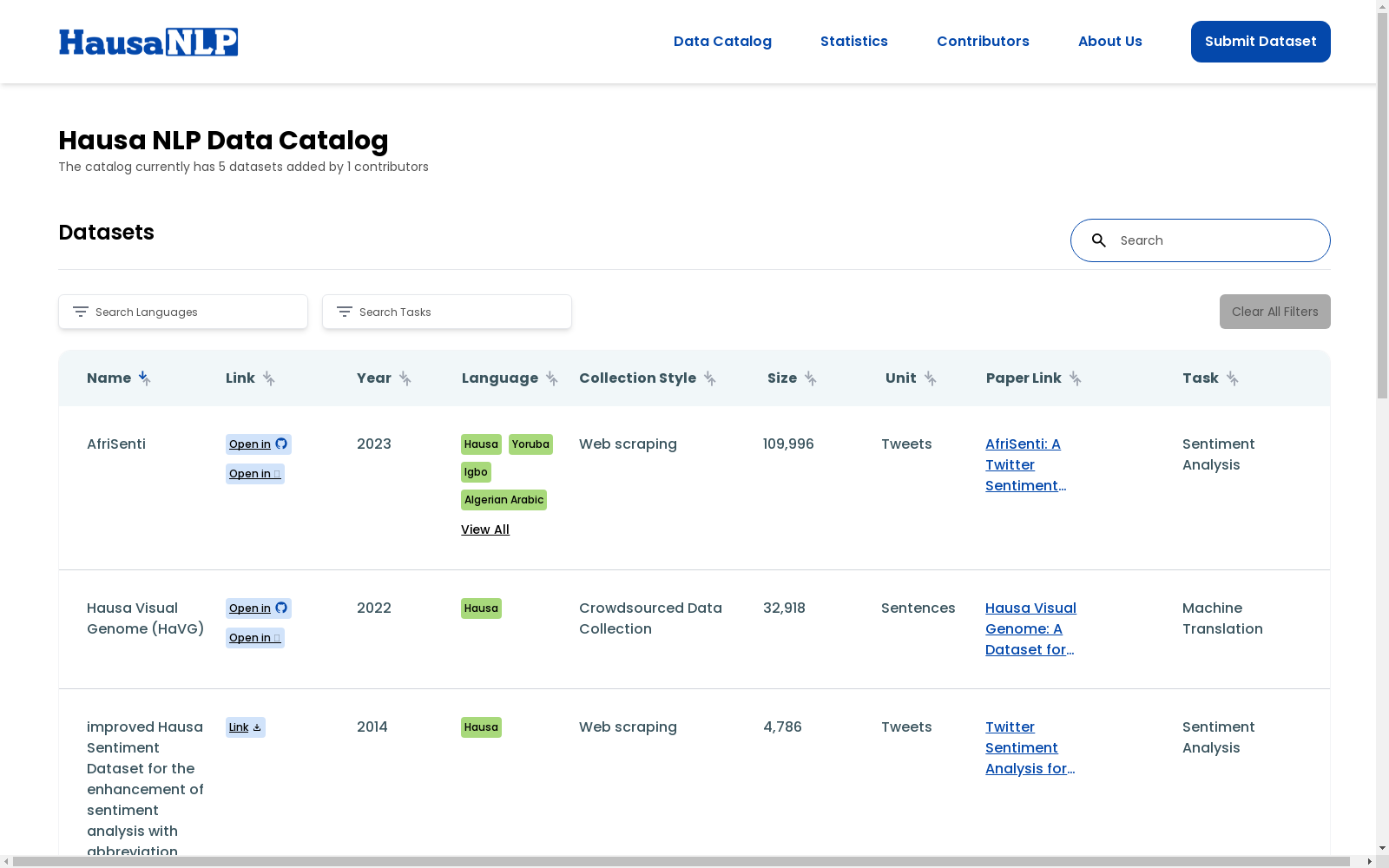
构建方式
HAUSANLP1数据集的构建基于对豪萨语自然语言处理资源的系统性整合与标准化处理。研究团队通过收集和标注来自社交媒体、新闻文章、维基百科等多源文本,涵盖了情感分析、机器翻译、命名实体识别、语音识别和问答系统等核心NLP任务。数据集的构建过程特别注重语言多样性,包含了豪萨语的主要方言变体,并采用人工与自动化相结合的方式进行质量校验,确保了数据的代表性和准确性。此外,团队还开发了专门的标注指南和工具,以支持社区驱动的数据扩展和更新。
特点
HAUSANLP1数据集以其广泛的覆盖范围和高质量标注著称。该数据集不仅包含了超过30,000条标注的情感分析推文,还整合了多个领域的平行语料,如新闻翻译、视觉问答和语音转录数据。其独特之处在于针对豪萨语的复杂语言特性(如声调、阿拉伯语借词)进行了专门处理,并提供了丰富的元数据以支持跨任务和跨方言研究。数据集还特别关注低资源场景下的挑战,通过提供多种规模的数据子集和基线模型,为研究者提供了灵活的基准测试平台。
使用方法
该数据集支持多种使用方式,研究者可通过官方发布的标准化接口访问不同任务的数据子集。对于模型训练,建议采用迁移学习策略,利用提供的预训练嵌入和基线模型进行微调。在多模态任务中,数据集提供了对齐的文本-图像和文本-语音对,支持端到端联合训练。社区贡献机制允许用户提交新的标注数据或工具,持续丰富资源。为确保可比性,官方推荐使用指定的评估指标和标准划分的训练/验证/测试集,并提供了详细的基准测试协议。
背景与挑战
背景概述
HAUSANLP1数据集是专为豪萨语自然语言处理(NLP)研究而设计的资源集合,由Shamsuddeen Hassan Muhammad等来自帝国理工学院、东北大学、比勒陀利亚大学等多个机构的研究人员于2025年发布。豪萨语作为非洲重要的语言之一,拥有超过1.2亿母语使用者和8000万第二语言使用者,但其在NLP领域的研究长期受限于资源匮乏。该数据集旨在解决豪萨语在文本分类、机器翻译、命名实体识别等基础NLP任务中的资源短缺问题,并推动相关技术的发展。通过整合分散的语料库、工具和研究文献,HAUSANLP1不仅提升了资源的可访问性,还为豪萨语NLP研究提供了系统化的基础支持。
当前挑战
HAUSANLP1数据集面临的挑战主要包括两方面:领域问题挑战和构建过程挑战。在领域问题方面,豪萨语作为低资源语言,缺乏高质量的标注数据,尤其是在多方言处理、复杂形态结构(如声调标记和名词复数系统)以及文化特定表达的理解上存在显著困难。此外,现有的大型语言模型对豪萨语的表示不足,导致其在情感分析、机器翻译等任务中表现欠佳。在构建过程中,数据收集面临方言多样性带来的标注一致性难题,且开源资源的分散性增加了整合成本。同时,豪萨语的罗马化与阿拉伯字母脚本(Ajami)并存现象,进一步加剧了文本标准化和预处理的复杂性。
常用场景
经典使用场景
HAUSANLP1数据集在豪萨语自然语言处理(NLP)研究中扮演了关键角色,尤其在文本分类、机器翻译、命名实体识别(NER)和情感分析等领域。该数据集通过整合多个公开可用的豪萨语语料库,为研究者提供了一个统一的资源平台,极大地促进了豪萨语这一低资源语言的NLP研究。例如,在情感分析任务中,研究者利用该数据集中的30,000条标注推文,成功训练了高性能的分类模型,加权F1分数达到0.81。
衍生相关工作
HAUSANLP1催生了多项豪萨语NLP的标志性研究。例如,Adelani等人(2022a)利用其语料开发了非洲语言机器翻译系统,支持16种低资源语言;Muhammad等人(2025b)基于数据集扩展了28种语言的细粒度情感分析框架;Abdulmumin等人(2023)则通过数据过滤技术提升了翻译模型的鲁棒性。此外,社区驱动的MasakhaNER项目(Adelani et al., 2022c)和AfriSenti基准(Muhammad et al., 2023)均以该数据集为基础,推动了非洲语言NLP的标准化进程。
数据集最近研究
最新研究方向
近年来,HAUSANLP1数据集在豪萨语自然语言处理领域的研究方向主要集中在多模态学习、低资源语言模型优化及跨语言迁移学习等方面。作为非洲使用最广泛的低资源语言之一,豪萨语在文本分类、机器翻译、命名实体识别等基础NLP任务中面临数据稀缺和方言变体等挑战。当前研究热点包括:利用多模态数据增强模型性能,如Hausa Visual Genome项目将图像描述与文本翻译结合;探索轻量化模型架构以适应低资源环境,如BabyLM挑战启发的样本高效预训练方法;以及通过跨语言迁移学习从斯瓦希里语等高资源非洲语言中获取知识。这些研究不仅推动了豪萨语NLP技术的发展,也为其他低资源语言提供了可借鉴的解决方案。
相关研究论文
- 1HausaNLP: Current Status, Challenges and Future Directions for Hausa Natural Language ProcessingImperial College London, Northeastern University, DSFSI, University of Pretoria, Kaduna State University, Kalinga University, Bayero University, Kano, Universiti Teknologi PETRONAS, University of the Witwatersrand, Johannesburg, Federal University of Lafia · 2025年
以上内容由遇见数据集搜集并总结生成


