Udacity Object Dataset
收藏github2020-06-17 更新2024-05-31 收录
下载链接:
https://github.com/BeSlower/Udacity_object_dataset
下载链接
链接失效反馈官方服务:
资源简介:
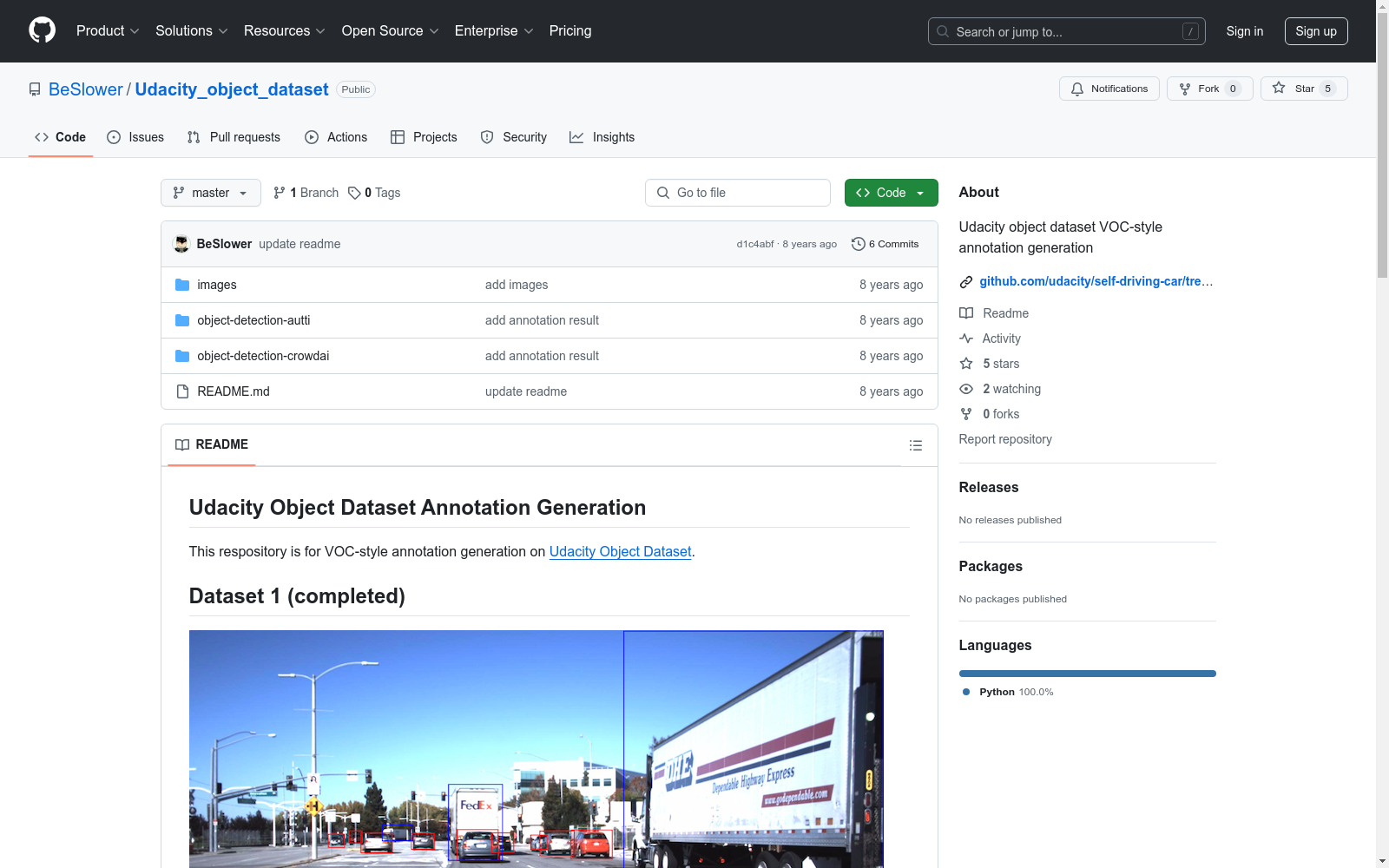
该数据集包括在加利福尼亚州山景城及周边城市白天驾驶的情况,包含超过65,000个标签,覆盖9,423帧,使用Point Grey研究相机以1920x1200分辨率在2hz频率下收集。数据集由CrowdAI使用机器学习和人工结合的方式进行标注。
This dataset encompasses daytime driving scenarios in Mountain View, California, and surrounding cities. It includes over 65,000 labels, covering 9,423 frames, collected at a resolution of 1920x1200 at a frequency of 2Hz using Point Grey research cameras. The dataset was annotated by CrowdAI using a combination of machine learning and manual efforts.
创建时间:
2017-04-06
原始信息汇总
数据集1概述
- 地点与条件:包含在加利福尼亚州山景城及周边城市白天驾驶的场景。
- 数据量:包含9,423帧,超过65,000个标签。
- 摄像机规格:使用Point Grey研究相机,分辨率为1920x1200,帧率为2hz。
- 标签类型:
- 汽车
- 卡车
- 行人
- CSV格式:
- xmin
- xmax
- ymin
- ymax
- frame
- label
- 预览URL
- 数据集大小:1.5 GB
- 标注者:CrowdAI
- 下载链接:http://bit.ly/udacity-annoations-crowdai
数据集2概述
- 数据特点:与数据集1类似,但增加了遮挡信息和交通灯标签。
- 数据量:包含15,000帧。
- 标签类型:
- 汽车
- 卡车
- 行人
- 交通灯
- CSV格式:
- frame
- xmin
- ymin
- xmax
- ymax
- occluded
- label
- 属性(仅用于交通灯)
- 数据集大小:3.3 GB
- 标注者:Autti
- 下载链接:http://bit.ly/udacity-annotations-autti
搜集汇总
数据集介绍
构建方式
Udacity Object Dataset的构建基于加利福尼亚州山景城及其周边城市的日间驾驶场景,通过Point Grey研究相机以1920x1200分辨率和2Hz的频率采集数据。数据集1包含9,423帧图像,共计65,000多个标注,由CrowdAI结合机器学习与人工标注完成。数据集2则进一步扩展至15,000帧,增加了遮挡信息和交通灯标签,完全由Autti的人工标注团队完成。
特点
该数据集的特点在于其高分辨率的图像质量和多样化的标注类别。数据集1涵盖汽车、卡车和行人三类目标,而数据集2在此基础上增加了交通灯标签,并提供了遮挡信息。两个数据集均以CSV格式存储,包含目标的边界框坐标、帧编号、标签及预览链接,便于研究人员快速定位和分析目标。
使用方法
使用Udacity Object Dataset时,研究人员可通过提供的CSV文件获取每帧图像中目标的边界框坐标及标签信息。数据集1适用于基础的物体检测任务,而数据集2则更适合研究复杂场景下的目标识别与遮挡处理。下载链接可直接获取数据,结合图像预览功能,用户能够快速验证标注的准确性并开展相关实验。
背景与挑战
背景概述
Udacity Object Dataset是由Udacity与CrowdAI、Autti等机构合作创建的一个面向自动驾驶领域的目标检测数据集。该数据集于2017年发布,主要采集自美国加州山景城及其周边城市的日间驾驶场景,涵盖了超过65,000个标注对象,分布在9,423帧高分辨率图像中。数据集的核心研究问题在于通过精确的目标检测与标注,推动自动驾驶系统中环境感知能力的发展。其标注对象包括车辆、卡车、行人及交通信号灯等关键元素,为自动驾驶算法的训练与验证提供了重要支持。该数据集在自动驾驶领域具有广泛的影响力,成为相关研究的重要基准之一。
当前挑战
Udacity Object Dataset在构建与应用过程中面临多重挑战。首先,自动驾驶环境中的目标检测任务本身具有高度复杂性,尤其是在动态变化的交通场景中,如何准确识别并标注车辆、行人及交通信号灯等目标成为核心难题。其次,数据集的构建过程中,标注的准确性与一致性至关重要,尽管采用了机器学习与人工标注相结合的方式,但如何确保大规模数据的标注质量仍是一个技术难点。此外,数据集中的遮挡问题(如部分目标被其他物体遮挡)进一步增加了标注与检测的难度,尤其是在交通信号灯的识别中,其属性信息的标注要求更为精细。这些挑战不仅体现在数据集的构建过程中,也对后续的算法开发与性能评估提出了更高的要求。
常用场景
经典使用场景
Udacity Object Dataset 在自动驾驶领域的研究中扮演着重要角色,尤其是在目标检测和场景理解方面。该数据集通过提供高分辨率的驾驶场景图像及其对应的标注信息,为研究人员提供了丰富的实验材料。经典的使用场景包括训练和评估深度学习模型,特别是卷积神经网络(CNN)和区域卷积神经网络(R-CNN),以识别道路上的车辆、行人和交通信号灯等关键目标。
解决学术问题
该数据集解决了自动驾驶研究中目标检测的精度和鲁棒性问题。通过提供大量真实场景下的标注数据,研究人员能够更准确地训练模型,减少误检和漏检的情况。此外,数据集中的遮挡标注信息为研究复杂场景下的目标识别提供了重要支持,推动了自动驾驶技术在复杂环境中的应用。
衍生相关工作
基于 Udacity Object Dataset,许多经典的研究工作得以展开。例如,一些研究利用该数据集开发了更高效的目标检测算法,如 Faster R-CNN 和 YOLO 的改进版本。此外,该数据集还催生了一系列关于自动驾驶场景理解的论文,探讨了如何在复杂环境中实现更精确的目标识别和路径规划。这些工作不仅推动了自动驾驶技术的发展,也为相关领域的研究提供了宝贵的参考。
以上内容由遇见数据集搜集并总结生成


