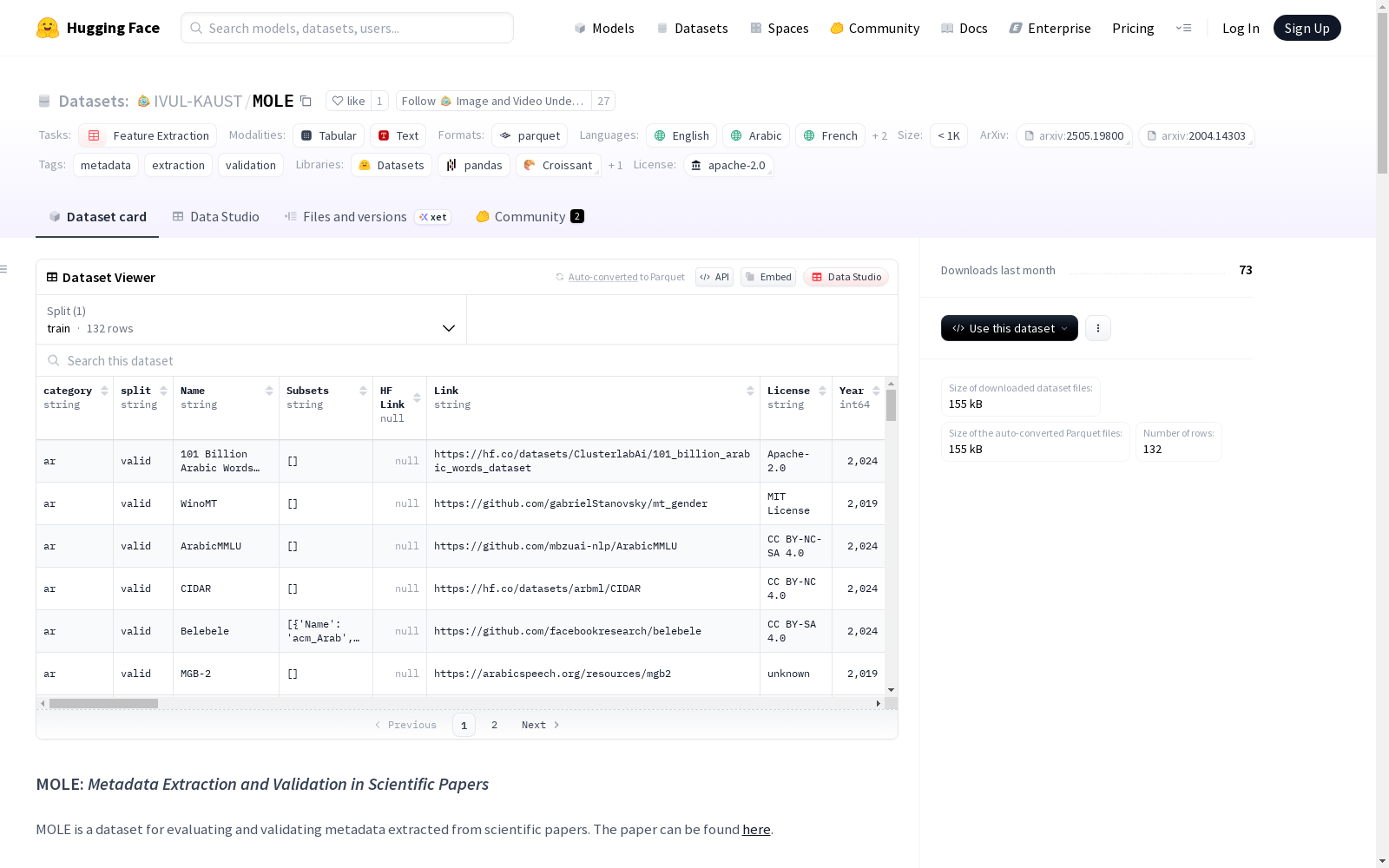
MOLE
收藏MOLE 数据集概述
基本信息
- 名称: MOLE (Metadata Extraction and Validation in Scientific Papers)
- 语言: 英语 (en)、阿拉伯语 (ar)、法语 (fr)、日语 (jp)、俄语 (ru)
- 许可证: Apache 2.0
- 规模类别: 小于1K样本 (n<1K)
- 任务类别: 特征提取 (feature-extraction)
- 标签: 元数据 (metadata)、提取 (extraction)、验证 (validation)
数据集结构
- 主要属性:
Name (str): 数据集名称Subsets (List[Dict[Name, Volume, Unit, Dialect]]): 数据集的方言子集Link (url): 数据集访问链接HF Link (url): Huggingface数据集链接License (str): 数据集许可证Year (date[year]): 数据集发布年份Language (str): 数据集语言Dialect (str): 数据集方言Domain (List[str]): 数据集来源Form (str): 数据形式Collection Style (List[str]): 数据集收集方式Description (str): 数据集描述Volume (float): 数据集大小Unit (str): 数据集包含的示例类型Ethical Risks (str): 数据集的伦理风险级别Provider (List[str]): 数据集提供者Derived From (List[str]): 用于创建该数据集的数据集Paper Title (str): 论文标题Paper Link (url): 论文链接Script (str): 数据集脚本Tokenized (bool): 数据集是否已分词Host (str): 数据集托管仓库名称Access (str): 数据集可访问性Cost (str): 数据集费用(若非免费)Test Split (bool): 数据集是否包含训练/验证和测试分割Tasks (List[str]): 数据集适用的NLP任务Venue Title (str): 论文发表场所标题Venue Type (str): 场所类型Venue Name (str): 论文发表场所全称Authors (List[str]): 论文作者Affiliations (List[str]): 作者所属机构Abstract (str): 论文摘要
加载数据集
python from datasets import load_dataset dataset = load_dataset(IVUL-KAUST/mole)
样本示例
python { "metadata": { "Name": "TUNIZI", "Subsets": [], "Link": "https://github.com/chaymafourati/TUNIZI-Sentiment-Analysis-Tunisian-Arabizi-Dataset", "HF Link": "", "License": "unknown", "Year": 2020, "Language": "ar", "Dialect": "Tunisia", "Domain": ["social media"], "Form": "text", "Collection Style": ["crawling", "manual curation", "human annotation"], "Description": "TUNIZI is a sentiment analysis dataset of over 9,000 Tunisian Arabizi sentences collected from YouTube comments, preprocessed, and manually annotated by native Tunisian speakers.", "Volume": 9210.0, "Unit": "sentences", "Ethical Risks": "Medium", "Provider": ["iCompass"], "Derived From": [], "Paper Title": "TUNIZI: A TUNISIAN ARABIZI SENTIMENT ANALYSIS DATASET", "Paper Link": "https://arxiv.org/abs/2004.14303", "Script": "Latin", "Tokenized": false, "Host": "GitHub", "Access": "Free", "Cost": "", "Test Split": false, "Tasks": ["sentiment analysis"], "Venue Title": "International Conference on Learning Representations", "Venue Type": "conference", "Venue Name": "International Conference on Learning Representations 2020", "Authors": ["Chayma Fourati", "Abir Messaoudi", "Hatem Haddad"], "Affiliations": ["iCompass"], "Abstract": "On social media, Arabic people tend to express themselves in their own local dialects. More particularly, Tunisians use the informal way called Tunisian Arabizi. Analytical studies seek to explore and recognize online opinions aiming to exploit them for planning and prediction purposes such as measuring the customer satisfaction and establishing sales and marketing strategies. However, analytical studies based on Deep Learning are data hungry. On the other hand, African languages and dialects are considered low resource languages. For instance, to the best of our knowledge, no annotated Tunisian Arabizi dataset exists. In this paper, we introduce TUNIZI as a sentiment analysis Tunisian Arabizi Dataset, collected from social networks, preprocessed for analytical studies and annotated manually by Tunisian native speakers." } }
局限性
- 数据集包含52篇标注论文,可能不足以全面评估LLMs。
许可证
- 许可证类型: Apache 2.0
- 许可证链接: https://www.apache.org/licenses/LICENSE-2.0
引用
bibtex @misc{mole, title={MOLE: Metadata Extraction and Validation in Scientific Papers Using LLMs}, author={Zaid Alyafeai and Maged S. Al-Shaibani and Bernard Ghanem}, year={2025}, eprint={2505.19800}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2505.19800}, }