gilkeyio/librispeech-alignments
收藏Hugging Face2023-11-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/gilkeyio/librispeech-alignments
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: sex
dtype: string
- name: subset
dtype: string
- name: id
dtype: string
- name: audio
dtype: audio
- name: transcript
dtype: string
- name: words
list:
- name: end
dtype: float64
- name: start
dtype: float64
- name: word
dtype: string
- name: phonemes
list:
- name: end
dtype: float64
- name: phoneme
dtype: string
- name: start
dtype: float64
splits:
- name: dev_clean
num_bytes: 365310608.879
num_examples: 2703
- name: dev_other
num_bytes: 341143993.784
num_examples: 2864
- name: test_clean
num_bytes: 377535532.98
num_examples: 2620
- name: test_other
num_bytes: 351207892.569557
num_examples: 2938
- name: train_clean_100
num_bytes: 6694747231.610863
num_examples: 28538
- name: train_clean_360
num_bytes: 24163659711.787865
num_examples: 104008
- name: train_other_500
num_bytes: 32945085271.89443
num_examples: 148645
download_size: 62101682957
dataset_size: 65238690243.50571
configs:
- config_name: default
data_files:
- split: dev_clean
path: data/dev_clean-*
- split: dev_other
path: data/dev_other-*
- split: test_clean
path: data/test_clean-*
- split: test_other
path: data/test_other-*
- split: train_clean_100
path: data/train_clean_100-*
- split: train_clean_360
path: data/train_clean_360-*
- split: train_other_500
path: data/train_other_500-*
license: cc-by-4.0
task_categories:
- automatic-speech-recognition
language:
- en
pretty_name: Librispeech Alignments
size_categories:
- 100K<n<1M
---
# Dataset Card for Librispeech Alignments
Librispeech with alignments generated by the [Montreal Forced Aligner](https://montreal-forced-aligner.readthedocs.io/en/latest/). The original alignments in TextGrid format can be found [here](https://zenodo.org/records/2619474)
## Dataset Details
### Dataset Description
Librispeech is a corpus of read English speech, designed for training and evaluating automatic speech recognition (ASR) systems. The dataset contains 1000 hours of 16kHz read English speech derived from audiobooks.
The Montreal Forced Aligner (MFA) was used to generate word and phoneme level alignments for the Librispeech dataset.
- **Curated by:** Vassil Panayotov, Guoguo Chen, Daniel Povey, Sanjeev Khudanpur (for Librispeech)
- **Funded by:** DARPA LORELEI
- **Shared by:** Loren Lugosch (for Alignments)
- **Language(s) (NLP):** English
- **License:** Creative Commons Attribution 4.0 International License
### Dataset Sources
- **Repository:** https://www.openslr.org/12
- **Paper:** https://arxiv.org/abs/1512.02595
- **Alignments:** https://zenodo.org/record/2619474
## Uses
### Direct Use
The Librispeech dataset can be used to train and evaluate ASR systems. The alignments allow for forced alignment techniques.
### Out-of-Scope Use
The dataset only contains read speech, so may not perform as well on spontaneous conversational speech.
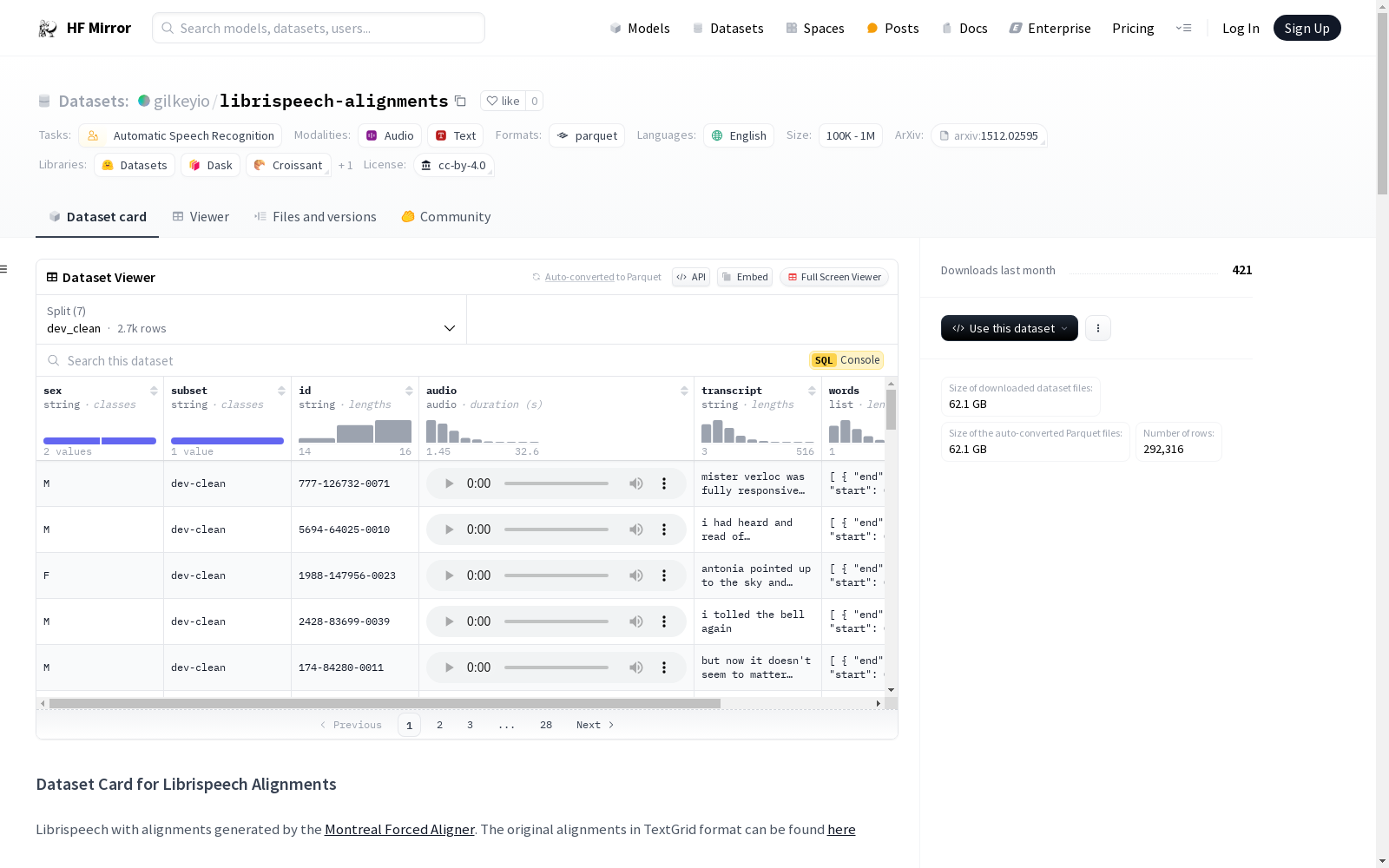
## Dataset Structure
The dataset contains 1000 hours of segmented read English speech from audiobooks. There are three train subsets: 100 hours (train-clean-100), 360 hours (train-clean-360) and 500 hours (train-other-500).
The alignments connect the audio to the reference text transcripts on word and phoneme level.
### Data Fields
- sex: M for male, F for female
- subset: dev_clean, dev_other, test_clean, test_other, train_clean_100, train_clean_360, train_other_500
- id: unique id of the data sample. (speaker id)-(chapter-id)-(utterance-id)
- audio: the audio, 16kHz
- transcript: the spoken text of the dataset, normalized and lowercased
- words: a list of words with fields:
- word: the text of the word
- start: the start time in seconds
- end: the end time in seconds
- phonemes: a list of phonemes with fields:
- phoneme: the phoneme spoken
- start: the start time in seconds
- end: the end time in seconds
## Dataset Creation
### Curation Rationale
Librispeech was created to further speech recognition research and to benchmark progress in the field.
### Source Data
#### Data Collection and Processing
The audio and reference texts were sourced from read English audiobooks in the LibriVox project. The data was segmented, filtered and prepared for speech recognition.
#### Who are the source data producers?
The audiobooks are read by volunteers for the LibriVox project. Information about the readers is available in the LibriVox catalog.
### Annotations
#### Annotation process
The Montreal Forced Aligner was used to create word and phoneme level alignments between the audio and reference texts. The aligner is based on Kaldi.
In the process of formatting this into a HuggingFace dataset, words with empty text and phonemes with empty text, silence tokens, or spacing tokens were removed
#### Who are the annotators?
The alignments were generated automatically by the Montreal Forced Aligner and shared by Loren Lugosch. The TextGrid files were parsed and integrated into this dataset by Kim Gilkey.
#### Personal and Sensitive Information
The data contains read speech and transcripts. No personal or sensitive information expected.
## Bias, Risks, and Limitations
The dataset contains only read speech from published books, not natural conversational speech. Performance on other tasks may be reduced.
### Recommendations
Users should understand that the alignments may contain errors and account for this in applications. For example, be wary of <UNK> tokens.
## Citation
**Librispeech:**
```
@inproceedings{panayotov2015librispeech,
title={Librispeech: an ASR corpus based on public domain audio books},
author={Panayotov, Vassil and Chen, Guoguo and Povey, Daniel and Khudanpur, Sanjeev},
booktitle={ICASSP},
year={2015},
organization={IEEE}
}
```
**Librispeech Alignments:**
```
Loren Lugosch, Mirco Ravanelli, Patrick Ignoto, Vikrant Singh Tomar, and Yoshua Bengio, "Speech Model Pre-training for End-to-End Spoken Language Understanding", Interspeech 2019.
```
**Montreal Forced Aligner:**
```
Michael McAuliffe, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger. "Montreal Forced Aligner: trainable text-speech alignment using Kaldi", Interspeech 2017.
```
数据集信息:
特征字段:
- 性别(sex),数据类型:字符串
- 子集(subset),数据类型:字符串
- 样本ID(id),数据类型:字符串
- 音频(audio),数据类型:音频
- 转录文本(transcript),数据类型:字符串
- 词语(words):列表类型,每个元素包含:结束时间(end,64位浮点型)、开始时间(start,64位浮点型)、词语文本(word,字符串)
- 音素(phonemes):列表类型,每个元素包含:结束时间(end,64位浮点型)、音素文本(phoneme,字符串)、开始时间(start,64位浮点型)
数据划分:
- 干净开发集(dev_clean):字节数365310608.879,样本量2703
- 非干净开发集(dev_other):字节数341143993.784,样本量2864
- 干净测试集(test_clean):字节数377535532.98,样本量2620
- 非干净测试集(test_other):字节数351207892.569557,样本量2938
- 100小时干净训练集(train_clean_100):字节数6694747231.610863,样本量28538
- 360小时干净训练集(train_clean_360):字节数24163659711.787865,样本量104008
- 500小时非干净训练集(train_other_500):字节数32945085271.89443,样本量148645
下载大小:62101682957字节,数据集总大小:65238690243.50571字节
配置项:
- 默认配置(default):数据文件路径对应各划分的data/xxx-*格式文件
许可协议:CC BY 4.0(知识共享署名4.0国际许可协议)
任务类别:自动语音识别(automatic-speech-recognition)
语言:英语(en)
展示名称:Librispeech Alignments
# Librispeech对齐数据集数据集卡片
本数据集为带有由蒙特利尔强制对齐工具(Montreal Forced Aligner,MFA)生成对齐信息的Librispeech数据集。原始TextGrid格式的对齐文件可在此处获取:https://zenodo.org/records/2619474
## 数据集详情
### 数据集描述
Librispeech是一个面向自动语音识别(Automatic Speech Recognition,ASR)系统训练与评估的英文朗读语音语料库,包含源自有声读物的1000小时16kHz英文朗读语音数据。研究人员使用蒙特利尔强制对齐工具(Montreal Forced Aligner,MFA)为该数据集生成了词级与音素级的对齐信息。
- **数据整理者**:Vassil Panayotov、Guoguo Chen、Daniel Povey、Sanjeev Khudanpur(Librispeech原始语料)
- **资助方**:美国国防高级研究计划局(DARPA)LORELEI项目
- **对齐数据分享者**:Loren Lugosch
- **自然语言处理所用语言**:英语
- **许可协议**:知识共享署名4.0国际许可协议(CC BY 4.0)
## 数据集来源
- **官方仓库**:https://www.openslr.org/12
- **相关论文**:https://arxiv.org/abs/1512.02595
- **对齐数据来源**:https://zenodo.org/record/2619474
## 数据集用途
### 直接用途
Librispeech数据集可用于训练与评估自动语音识别系统,其附带的对齐信息可支持强制对齐相关技术的应用。
### 超出适用范围的用途
本数据集仅包含朗读语音,因此在自然会话语音场景下的表现可能欠佳。
## 数据集结构
本数据集包含源自有声读物的1000小时分段英文朗读语音,共包含三类训练子集:100小时干净训练集(train_clean_100)、360小时干净训练集(train_clean_360)以及500小时非干净训练集(train_other_500)。对齐信息在词级与音素级上将音频与参考转录文本进行了关联。
### 数据字段
- 性别(sex):M代表男性,F代表女性
- 子集(subset):包含dev_clean、dev_other、test_clean、test_other、train_clean_100、train_clean_360、train_other_500
- 样本ID(id):数据样本的唯一标识符,格式为「说话人ID-章节ID-utterance-ID」
- 音频(audio):16kHz采样率的音频数据
- 转录文本(transcript):经过标准化处理并转为小写的朗读文本
- 词语列表(words):包含词语信息的列表,每个元素包含:词语文本(word)、词语起始时间(单位:秒,start)、词语结束时间(单位:秒,end)
- 音素列表(phonemes):包含音素信息的列表,每个元素包含:音素文本(phoneme)、音素起始时间(单位:秒,start)、音素结束时间(单位:秒,end)
## 数据集构建
### 整理初衷
Librispeech的构建旨在推动语音识别领域的研究,并为该领域的进展提供基准测试基准。
### 源数据
#### 数据收集与处理
音频与参考文本源自LibriVox项目中的英文有声读物,数据经过分段、筛选处理后适配语音识别任务需求。
#### 源数据生产者
本数据集的有声读物由LibriVox项目的志愿者朗读,朗读者的相关信息可在LibriVox目录中查询。
### 标注信息
#### 标注流程
研究人员使用基于Kaldi框架的蒙特利尔强制对齐工具,为音频与参考文本生成词级与音素级的对齐信息。在将数据格式化为Hugging Face数据集的过程中,空文本词语、空文本音素、静音标记与空格标记均已被移除。
#### 标注者
对齐信息由蒙特利尔强制对齐工具自动生成,并由Loren Lugosch分享。Kim Gilkey负责解析TextGrid格式文件并将其整合至本数据集。
#### 个人与敏感信息
本数据集仅包含朗读语音与转录文本,不包含任何个人或敏感信息。
## 偏差、风险与局限性
本数据集仅包含公开出版物的朗读语音,而非自然会话语音,因此在其他任务中的表现可能会受到影响。
### 建议
用户应注意对齐信息可能存在错误,并在应用中予以考量,例如需警惕<UNK>(未知)标记。
## 引用信息
### Librispeech原始语料引用
@inproceedings{panayotov2015librispeech,
title={Librispeech: an ASR corpus based on public domain audio books},
author={Panayotov, Vassil and Chen, Guoguo and Povey, Daniel and Khudanpur, Sanjeev},
booktitle={ICASSP},
year={2015},
organization={IEEE}
}
### Librispeech对齐数据引用
Loren Lugosch, Mirco Ravanelli, Patrick Ignoto, Vikrant Singh Tomar, and Yoshua Bengio, "Speech Model Pre-training for End-to-End Spoken Language Understanding", Interspeech 2019.
### 蒙特利尔强制对齐工具引用
Michael McAuliffe, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger. "Montreal Forced Aligner: trainable text-speech alignment using Kaldi", Interspeech 2017.
提供机构:
gilkeyio
原始信息汇总
数据集概述
数据集描述
Librispeech是一个用于训练和评估自动语音识别(ASR)系统的英语阅读语音语料库。该数据集包含1000小时、16kHz采样的英语阅读语音,源自有声读物。
数据集特征
- sex: 性别,字符串类型(M表示男性,F表示女性)
- subset: 子集,字符串类型(如dev_clean, dev_other等)
- id: 数据样本的唯一ID,字符串类型(格式为speaker_id-chapter_id-utterance_id)
- audio: 音频数据,16kHz采样
- transcript: 语音的文本转录,已归一化和小写处理,字符串类型
- words: 单词列表,包含以下字段:
- word: 单词文本,字符串类型
- start: 开始时间,浮点数类型
- end: 结束时间,浮点数类型
- phonemes: 音素列表,包含以下字段:
- phoneme: 音素文本,字符串类型
- start: 开始时间,浮点数类型
- end: 结束时间,浮点数类型
数据集分割
- dev_clean: 365310608.879字节,2703个样本
- dev_other: 341143993.784字节,2864个样本
- test_clean: 377535532.98字节,2620个样本
- test_other: 351207892.569557字节,2938个样本
- train_clean_100: 6694747231.610863字节,28538个样本
- train_clean_360: 24163659711.787865字节,104008个样本
- train_other_500: 32945085271.89443字节,148645个样本
数据集大小
- 下载大小: 62101682957字节
- 数据集大小: 65238690243.50571字节
许可证
Creative Commons Attribution 4.0 International License
任务类别
自动语音识别(Automatic Speech Recognition, ASR)
语言
英语(English)
数据集名称
Librispeech Alignments
数据集配置
- default: 包含各个子集的数据文件路径
数据集创建
- 数据收集和处理: 音频和参考文本来自LibriVox项目中的英语有声读物。数据经过分割、过滤和准备,用于语音识别。
- 标注过程: 使用Montreal Forced Aligner生成单词和音素级别的对齐。在格式化为HuggingFace数据集的过程中,删除了空文本的单词和音素、静音标记或间隔标记。
偏差、风险和限制
该数据集仅包含阅读语音,可能不适用于自然对话语音。
推荐
用户应了解对齐可能包含错误,并在应用中考虑这一点。例如,对<UNK>标记保持警惕。
搜集汇总
数据集介绍
构建方式
该数据集的构建基于Librispeech语料库,该语料库包含1000小时的16kHz英语朗读语音,源自LibriVox项目中的有声读物。为了生成单词和音素级别的对齐,使用了Montreal Forced Aligner(MFA)工具。MFA基于Kaldi,能够自动生成音频与文本之间的对齐信息。在数据集的准备过程中,去除了包含空文本的单词和音素,以及静音标记和间隔标记,确保数据的质量和一致性。
特点
该数据集的主要特点在于其丰富的对齐信息,包括单词和音素级别的精确时间戳,这为语音识别和语音合成等任务提供了强大的支持。此外,数据集包含了不同子集,如100小时、360小时和500小时的训练数据,以及开发和测试集,满足了不同规模和需求的研究和应用。
使用方法
该数据集适用于自动语音识别(ASR)系统的训练和评估,尤其是需要精确对齐信息的任务。用户可以直接使用提供的音频和文本对齐数据,进行模型训练和性能评估。此外,数据集的结构化设计使得用户可以轻松地提取和处理特定子集的数据,以适应不同的研究需求和应用场景。
背景与挑战
背景概述
Librispeech Alignments数据集源自Librispeech语料库,该语料库由Vassil Panayotov、Guoguo Chen、Daniel Povey和Sanjeev Khudanpur于2015年创建,旨在为自动语音识别(ASR)系统提供高质量的训练和评估资源。该数据集包含1000小时的16kHz英语朗读语音,源自LibriVox项目中的有声读物。通过使用Montreal Forced Aligner(MFA)工具,生成了单词和音素级别的对齐信息,进一步增强了数据集在语音识别任务中的应用潜力。Librispeech Alignments的发布不仅推动了ASR技术的发展,还为语音与文本对齐研究提供了宝贵的资源。
当前挑战
Librispeech Alignments数据集在构建过程中面临多项挑战。首先,数据集仅包含朗读语音,缺乏自然对话语音,这限制了其在处理非结构化语音任务中的表现。其次,生成单词和音素级别的对齐信息需要高度精确的算法,Montreal Forced Aligner虽然在处理上表现出色,但仍可能存在对齐错误,尤其是在处理未知词汇时。此外,数据集的规模和复杂性要求高效的存储和处理技术,以确保在训练和评估ASR系统时的计算效率。最后,数据集的使用需谨慎考虑潜在的偏见和局限性,特别是在处理不同口音和语速的语音时。
常用场景
经典使用场景
在语音识别领域,gilkeyio/librispeech-alignments数据集的经典应用场景主要集中在自动语音识别(ASR)系统的训练与评估。该数据集提供了1000小时的高质量英语语音数据,并附带了通过Montreal Forced Aligner生成的词和音素级别的对齐信息。这些对齐信息使得研究者能够更精确地分析语音与文本之间的关系,从而优化语音识别模型的性能。
实际应用
在实际应用中,gilkeyio/librispeech-alignments数据集被广泛用于开发和测试语音识别系统,如智能语音助手、语音转文字服务和语音翻译工具。其高质量的语音数据和对齐信息使得这些应用能够更准确地理解和转录用户的语音输入,从而提升用户体验。此外,该数据集还被用于语音合成和语音增强等领域的研究,进一步扩展了其应用范围。
衍生相关工作
基于gilkeyio/librispeech-alignments数据集,研究者们开发了多种语音识别和处理技术。例如,Montreal Forced Aligner的引入为语音与文本的对齐提供了自动化解决方案,推动了相关工具的发展。此外,该数据集还被用于预训练语音模型,如在端到端语音理解任务中的应用,展示了其在提升模型泛化能力方面的潜力。
以上内容由遇见数据集搜集并总结生成


