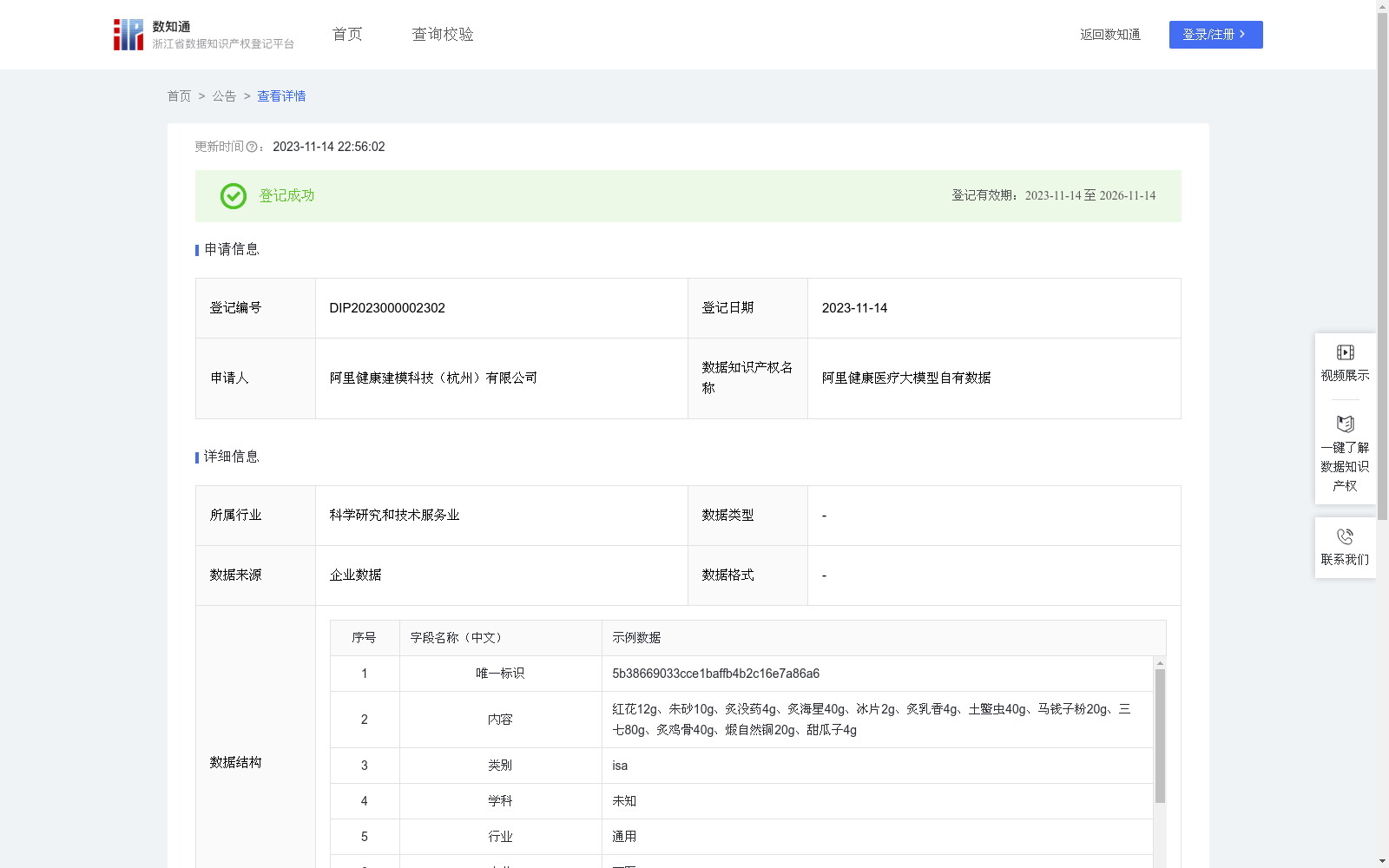
阿里健康医疗大模型自有数据
收藏浙江省数据知识产权登记平台2023-11-14 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/10609
下载链接
链接失效反馈官方服务:
资源简介:
在“互联网健康咨询、在线辅助问诊、临床决策辅助支持”场景中,通过训练挖掘内容与学科、行业、专业、科室之间的相关性,获取药品、诊断、疾病、检查、检验等诊疗知识,构建出具备自我学习、数据分析、引导提问等能力医疗大模型。辅助医生为用户提供精准、可靠、及时的全流程健康咨询服务,主要包含AI诊前服务和AI诊后服务,AI诊前服务利用大模型技术,提供健康自诊断、知识问答、用药咨询、智能导诊等功能的服务,帮助用户在就医前获得初步的医疗建议和指导;AI诊后服务是指利用医疗大模型技术,在诊后随访、智能评估、专病管理、智能跟踪等院外场景中提供专业的知识服务能力。1.格式清洗:完成QA对答、知识图谱等原始数据的格式统一&清洗,获取内容、学科、数据集类型、数据集来源等信息
2.敏感信息&毒性信息过滤:去除隐私数据和黄赌毒/暴恐/政治等毒性数据。
3.质量过滤:清除语句不通顺、医学专业质量差的数据,并生产质量分字段
4.数据去重:通过模糊匹配和精准匹配完成数据集内部重复数据清除
5.多维度打标:基于质心的聚类,采用k均值算法,计算对象与聚类中心之间的距离,完成学科、类别、行业、专业、科室等字段的打标,便于数据洞察和选择。
In the scenarios of Internet health consultation, online auxiliary diagnosis, and clinical decision support, by mining the correlations between content and disciplines, industries, professions and departments through training, and acquiring diagnostic and therapeutic knowledge including drugs, diagnoses, diseases, examinations and tests, we construct a medical large language model (LLM) with capabilities such as self-learning, data analysis, and guided questioning. This model assists doctors in providing users with accurate, reliable and timely full-process health consultation services, which mainly include AI pre-diagnosis services and AI post-diagnosis services. AI pre-diagnosis services utilize LLM technology to provide functions such as health self-diagnosis, knowledge Q&A, medication consultation, and intelligent medical guidance, helping users obtain preliminary medical advice and guidance before seeing a doctor. AI post-diagnosis services refer to providing professional knowledge service capabilities in out-of-hospital scenarios such as post-diagnosis follow-up, intelligent assessment, specific disease management, and intelligent tracking by leveraging medical LLM technology. The data processing workflow includes five steps: 1. Format cleaning: Unify and clean the formats of raw data such as QA pairs and knowledge graphs, and collect information including content, disciplines, dataset type, and dataset source. 2. Sensitive and toxic information filtering: Remove privacy data and toxic data involving pornography, gambling, drugs, violence, terrorism, and politics. 3. Quality filtering: Eliminate data with ungrammatical sentences and poor medical professional quality, and generate a quality score field. 4. Data deduplication: Remove duplicate data within the dataset through both fuzzy matching and exact matching. 5. Multi-dimensional labeling: Adopt the k-means algorithm based on centroid clustering to calculate the distance between objects and cluster centers, and complete the labeling of fields such as disciplines, categories, industries, professions and departments to facilitate data insight and selection.
提供机构:
阿里健康建模科技(杭州)有限公司
创建时间:
2023-10-24
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


