有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
Mixed Arabic Datasets (MAD) Corpus 是一个动态的阿拉伯语文本集合,来源于各种在线平台和数据集。它旨在解决阿拉伯语数据集在互联网上的分散问题,将这些分散的资源集中到一个综合的存储库中。
该语料库涵盖了从社交媒体对话到文学杰作的广泛内容,捕捉了阿拉伯语交流的丰富性,包括标准阿拉伯语和地区方言。
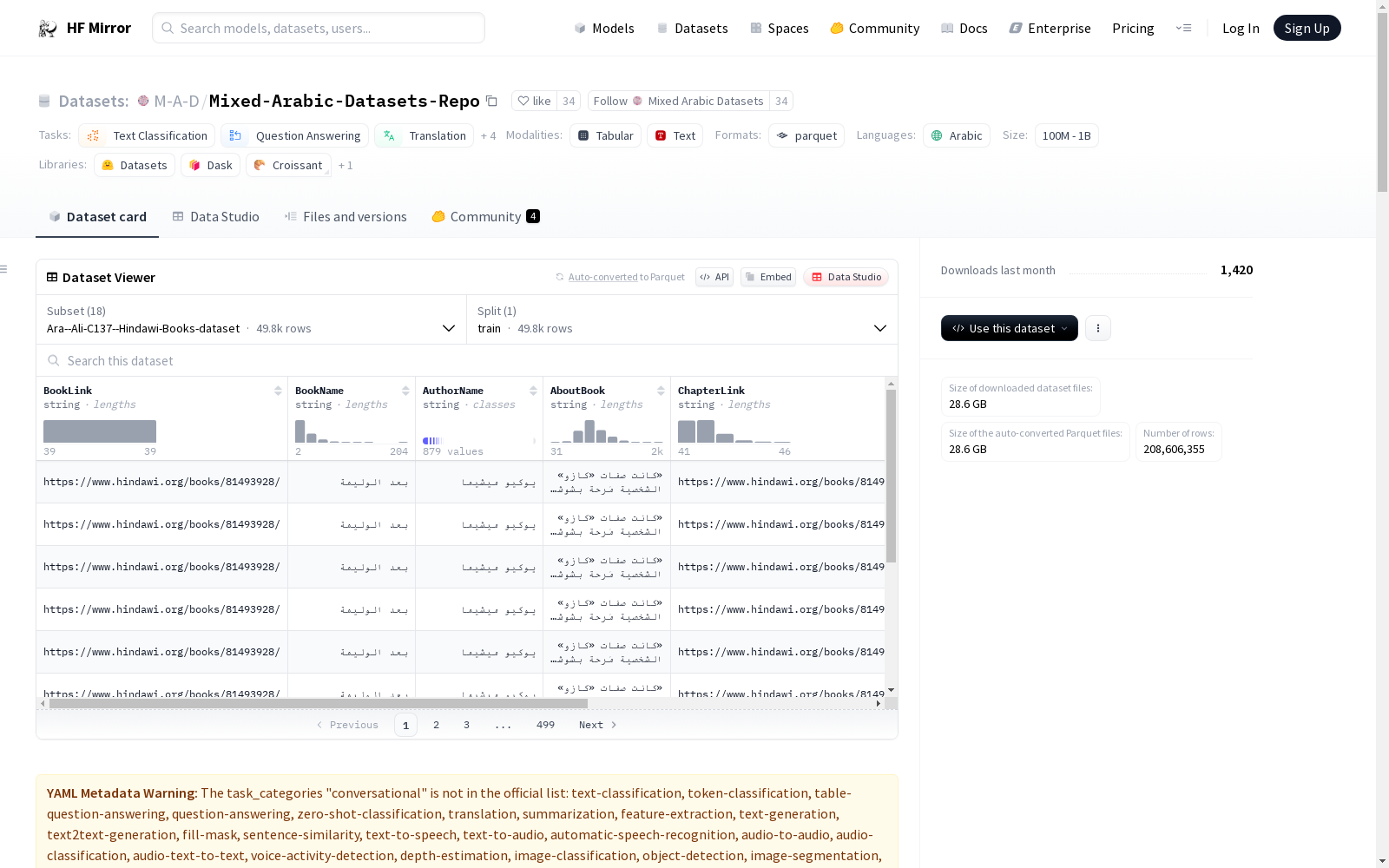
Ara--Ali-C137--Hindawi-Books-dataset
Ara--Goud--Goud-sum
Ara--J-Mourad--MNAD.v1
Ara--JihadZa--IADD
Ara--LeMGarouani--MAC-corpus
Ara--MBZUAI--Bactrian-X
Ara--OpenAssistant--oasst1
Ara--Wikipedia
Ara--bigscience--xP3
Ara--cardiffnlp--tweet_sentiment_multilingual
Ara--miracl--miracl
Ara--mustapha--QuranExe
Ara--pain--Arabic-Tweets
Ara--saudinewsnet
Ary--AbderrahmanSkiredj1--Darija-Wikipedia
Ary--Ali-C137--Darija-Stories-Dataset
Ary--Wikipedia
Arz--Wikipedia
Mixed Arabic Datasets (MAD) 是一个动态和不断发展的集合,其大小随着新数据集的添加或移除而波动。随着 MAD 的不断扩展,它成为一个适应阿拉伯语数据集不断变化格局的活资源。
Mixed Arabic Datasets (MAD) 具有推动多种创新应用的潜力:
LFW
人脸数据集;LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。 URL: http://vis-www.cs.umass.edu/lfw/index.html#download
AI_Studio 收录
TCIA
TCIA(The Cancer Imaging Archive)是一个公开的癌症影像数据集,包含多种癌症类型的医学影像数据,如CT、MRI、PET等。这些数据通常与临床和病理信息相结合,用于癌症研究和临床试验。
www.cancerimagingarchive.net 收录
中国农村教育发展报告
该数据集包含了中国农村教育发展的相关数据,涵盖了教育资源分布、教育质量、学生表现等多个方面的信息。
www.moe.gov.cn 收录
中国农村金融统计数据
该数据集包含了中国农村金融的统计信息,涵盖了农村金融机构的数量、贷款余额、存款余额、金融服务覆盖率等关键指标。数据按年度和地区分类,提供了详细的农村金融发展状况。
www.pbc.gov.cn 收录
RadDet
RadDet是一个包含11种雷达类别的数据集,包括6种新的低概率干扰(LPI)多相码(P1, P2, P3, P4, Px, Zadoff-Chu)和一种新的宽带调频连续波(FMCW)。数据集覆盖500 MHz频段,包含40,000个雷达帧,分为训练集、验证集和测试集。数据集在两种不同的雷达环境中提供:稀疏数据集(RadDet-1T)和密集数据集(RadDet-9T)。
github 收录