old-newpapers
收藏Hugging Face2024-12-17 更新2024-12-18 收录
下载链接:
https://huggingface.co/datasets/1024m/old-newpapers
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是为了避免gpt3发布后可能出现的错误标签样本而筛选出来的。
创建时间:
2024-12-11
原始信息汇总
Dataset Card for Dataset Name
Dataset Details
Dataset Description
- Curated by: [More Information Needed]
- Funded by [optional]: [More Information Needed]
- Shared by [optional]: [More Information Needed]
- Language(s) (NLP): [More Information Needed]
- License: apache-2.0
Dataset Sources [optional]
- Repository: [More Information Needed]
- Paper [optional]: [More Information Needed]
- Demo [optional]: [More Information Needed]
Uses
Direct Use
[More Information Needed]
Out-of-Scope Use
[More Information Needed]
Dataset Structure
[More Information Needed]
Dataset Creation
Curation Rationale
[More Information Needed]
Source Data
Data Collection and Processing
[More Information Needed]
Who are the source data producers?
[More Information Needed]
Annotations [optional]
Annotation process
[More Information Needed]
Who are the annotators?
[More Information Needed]
Personal and Sensitive Information
[More Information Needed]
Bias, Risks, and Limitations
[More Information Needed]
Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
Citation [optional]
BibTeX:
[More Information Needed]
APA:
[More Information Needed]
Glossary [optional]
[More Information Needed]
More Information [optional]
[More Information Needed]
Dataset Card Authors [optional]
[More Information Needed]
Dataset Card Contact
[More Information Needed]
搜集汇总
数据集介绍
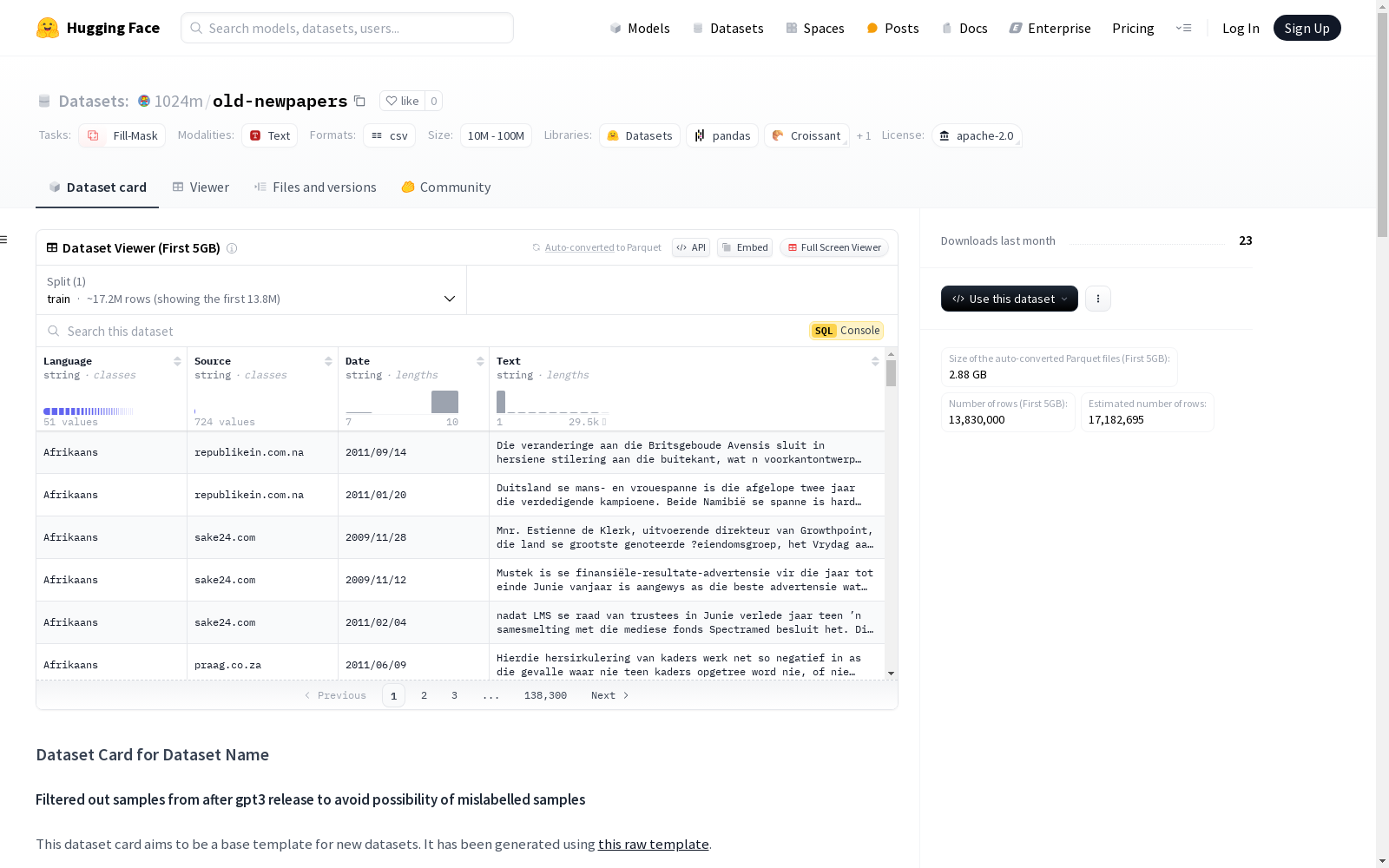
构建方式
该数据集的构建方式尚未详细披露,但根据现有信息,可以推测其可能涉及对历史报纸文本的筛选与处理。特别值得注意的是,数据集在筛选过程中排除了GPT-3发布后的样本,以避免潜在的标签错误问题。这一策略确保了数据集的时间一致性和可靠性。
使用方法
该数据集主要适用于自然语言处理任务中的填空任务(fill-mask)。用户可以通过加载数据集并应用相应的模型进行训练或评估,以提高模型在处理历史文本时的表现。使用时需注意数据集的时间范围和潜在的偏见风险。
背景与挑战
背景概述
旧报纸数据集(old-newpapers)是一个专注于历史报纸文本的精选数据集,旨在为自然语言处理领域的研究人员提供丰富的历史文本资源。该数据集的创建时间尚未明确,但其核心研究问题在于通过历史文本的分析,探索语言演变、文化变迁以及历史事件的文本表达。尽管具体的研究人员或机构信息尚未披露,但该数据集的构建无疑为历史语言学、文本挖掘以及自然语言处理等领域的研究提供了宝贵的资源。其影响力在于为研究人员提供了一个独特的视角,通过分析历史文本,揭示语言与社会历史的深层联系。
当前挑战
旧报纸数据集在构建过程中面临诸多挑战。首先,历史文本的收集与处理需要克服文本质量参差不齐、格式多样等问题,确保数据的准确性与一致性。其次,由于数据集过滤了GPT-3发布后的样本,以避免潜在的误标注问题,这使得数据集的时效性与完整性受到一定限制。此外,历史文本中可能包含的偏见、敏感信息以及文化差异,也为数据集的使用带来了伦理与技术上的双重挑战。研究人员在使用该数据集时,需谨慎处理这些潜在问题,以确保研究的公正性与可靠性。
常用场景
经典使用场景
在自然语言处理领域,old-newpapers数据集常被用于文本生成和填充任务。该数据集通过提供历史报纸文本,帮助模型学习语言的演变和特定历史时期的表达方式。研究者可以利用这一数据集训练模型,使其在生成与历史背景相关的文本时表现更为准确和自然。
解决学术问题
old-newpapers数据集为研究者提供了一个独特的视角,用以探讨语言随时间的变化及其在不同历史背景下的应用。通过分析该数据集,学者们能够深入研究语言模型的历史适应性,解决语言模型在处理历史文本时的偏差问题,从而提升模型的泛化能力和文化敏感性。
实际应用
在实际应用中,old-newpapers数据集可用于开发历史文本分析工具,帮助历史学家和研究人员更准确地解读和分析历史文献。此外,该数据集还可用于构建智能辅助写作系统,帮助作家和编剧在创作历史题材作品时,更真实地还原历史场景和语言风格。
数据集最近研究
最新研究方向
在新闻文本分析领域,old-newpapers数据集因其独特的历史文本资源而备受关注。该数据集专注于收集和整理GPT-3发布之前的报纸文本,旨在避免因模型生成内容导致的标签错误问题。这一特性使得该数据集在历史文本的语义理解和上下文分析中具有重要价值。当前的研究方向主要集中在利用该数据集进行文本生成模型的训练与评估,特别是在模型对历史文本的适应性和生成质量方面。此外,该数据集还被用于探索历史文本中的潜在偏见和风险,为构建更加公平和透明的自然语言处理模型提供了宝贵的资源。
以上内容由遇见数据集搜集并总结生成


