有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
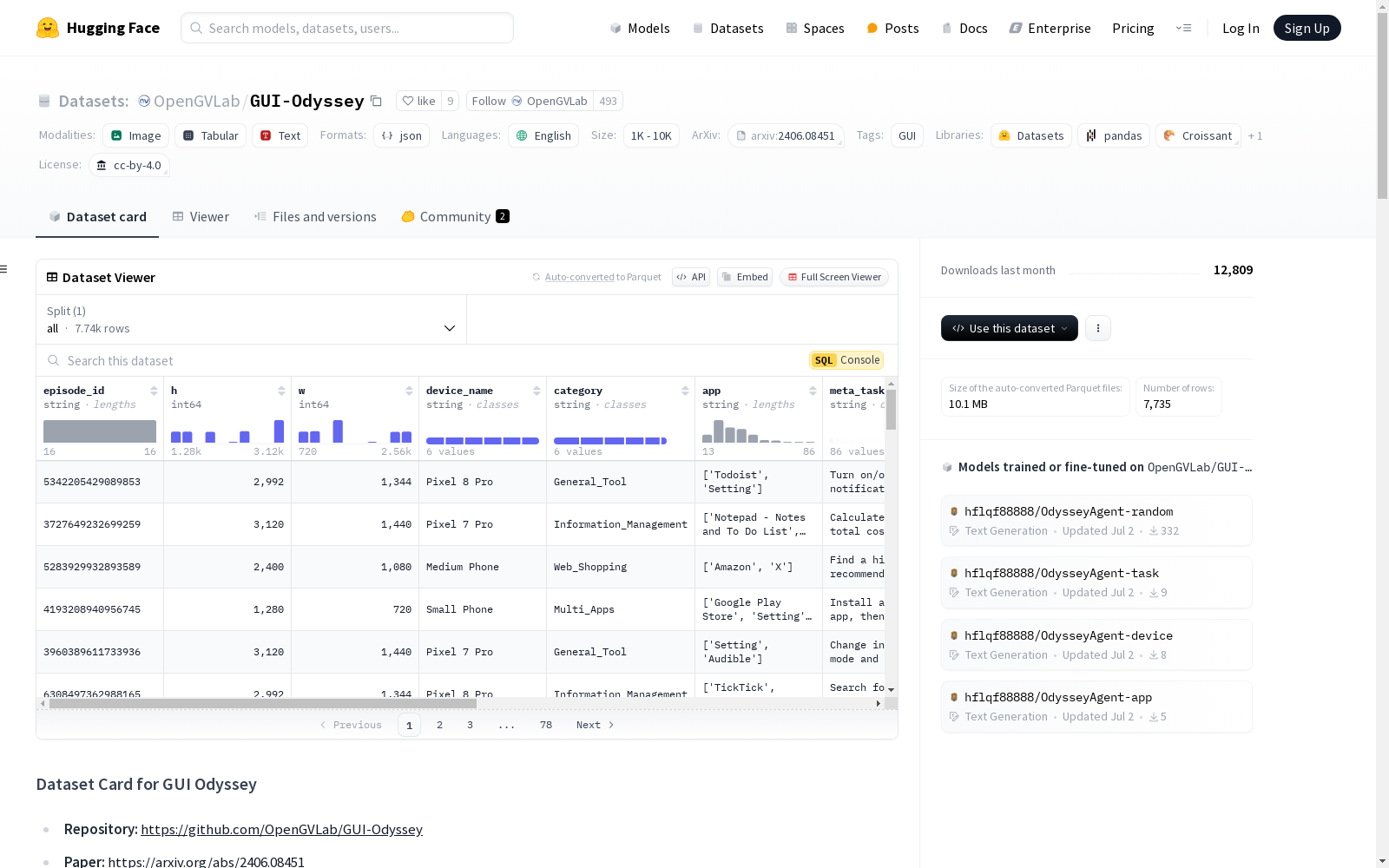
GUI Odyssey 是一个全面的用于训练和评估跨应用导航代理的数据集。该数据集包含来自6种移动设备的7,735个片段,涵盖6种类型的跨应用任务、201个应用和1.4K个应用组合。
每个注释字段如下:
episode_id (str): 片段的唯一标识符。device_info (dict): 收集片段的虚拟设备的详细信息。
product (str): 模拟器的产品名称。release_version (str): 模拟器的Android API级别。sdk_version (str): 用于模拟器的软件开发工具包的版本。h (int): 设备屏幕的高度。w (int): 设备屏幕的宽度。device_name (str): 虚拟设备的名称,包括 Pixel Fold, Pixel Tablet, Pixel 8 Pro, Pixel 7 Pro, Medium Phone, Small Phone。task_info (dict): 收集片段的任务的详细信息。
category (str): 任务的类别,包括 Multi_Apps, Web_Shopping, General_Tool, Information_Management, Media_Entertainment, Social_Sharing。app (list[str]): 用于该任务的应用。meta_task (str): 该任务的模板,例如 "Search for the next {} and set a reminder."。task (str): 通过填充元任务创建的具体任务,例如 "Search for the next New York Fashion Week and set a reminder."。instruction (str): 任务的详细和改写版本,包括特定工具或应用程序,例如 "Utilize DuckDuckgo to find the dates for the next New York Fashion Week and then use TickTick to set a reminder for the event."。step_length (int): 该片段的总步数。steps (list[dict]): 该片段的每个单独步骤,包括以下字段:
step (int): 片段中的每个步骤由一个零索引的步骤号标识,表示其在序列中的位置。例如,如果 step 是1,则对应于片段的第二步。screenshot (str): 该步骤的当前屏幕截图。action (str): 该步骤的相应动作,包括 CLICK, SCROLL, LONG_PRESS, TYPE, COMPLETE, IMPOSSIBLE, HOME, BACK。info (Union[str, list[list]]): 提供执行 action 字段中指定的动作所需的具体细节。注意,所有坐标都归一化到 [0, 1000] 范围内。
ps (str): 根据动作字段的值提供额外的详细信息或上下文。
可以通过两种方式分割 GUI Odyssey 数据集来评估代理的域内和域外性能:
每个分类对应的 JSON 文件字段如下:
train (list[str]): 训练集的注释文件名列表,等同于 episode_id。test (list[str]): 测试集的注释文件名列表,等同于 episode_id。该数据集根据 Creative Commons Attribution 4.0 International License 进行许可。
该数据集主要用于研究目的。我们强烈反对任何有害使用数据或技术的行为。
bib @misc{lu2024gui, title={GUI Odyssey: A Comprehensive Dataset for Cross-App GUI Navigation on Mobile Devices}, author={Quanfeng Lu and Wenqi Shao and Zitao Liu and Fanqing Meng and Boxuan Li and Botong Chen and Siyuan Huang and Kaipeng Zhang and Yu Qiao and Ping Luo}, year={2024}, eprint={2406.08451}, archivePrefix={arXiv}, primaryClass={cs.CV} }
典型分布式光伏出力预测数据集
光伏电站出力数据每5分钟从电站机房监控系统获取;气象实测数据从气象站获取,气象站建于电站30号箱变附近,每5分钟将采集的数据通过光纤传输到机房;数值天气预报数据利用中国电科院新能源气象应用机房的WRF业务系统(包括30TF计算刀片机、250TB并行存储)进行中尺度模式计算后输出预报产品,每日8点前通过反向隔离装置推送到电站内网预测系统。
国家基础学科公共科学数据中心 收录
中国农村金融统计数据
该数据集包含了中国农村金融的统计信息,涵盖了农村金融机构的数量、贷款余额、存款余额、金融服务覆盖率等关键指标。数据按年度和地区分类,提供了详细的农村金融发展状况。
www.pbc.gov.cn 收录
TPTP
TPTP(Thousands of Problems for Theorem Provers)是一个包含大量逻辑问题的数据集,主要用于定理证明器的测试和评估。它包含了多种逻辑形式的问题,如一阶逻辑、高阶逻辑、命题逻辑等。
www.tptp.org 收录
Materials Project
材料项目是一组标有不同属性的化合物。数据集链接: MP 2018.6.1(69,239 个材料) MP 2019.4.1(133,420 个材料)
OpenDataLab 收录
CliMedBench
CliMedBench是一个大规模的中文医疗大语言模型评估基准,由华东师范大学等机构创建。该数据集包含33,735个问题,涵盖14个核心临床场景,主要来源于顶级三级医院的真实电子健康记录和考试练习。数据集的创建过程包括专家指导的数据选择和多轮质量控制,确保数据的真实性和可靠性。CliMedBench旨在评估和提升医疗大语言模型在临床决策支持、诊断和治疗建议等方面的能力,解决医疗领域中模型性能评估的不足问题。
arXiv 收录