mem-and-russian-jokes-dataset
收藏Hugging Face2025-06-01 更新2025-06-02 收录
下载链接:
https://huggingface.co/datasets/samedad/mem-and-russian-jokes-dataset
下载链接
链接失效反馈官方服务:
资源简介:
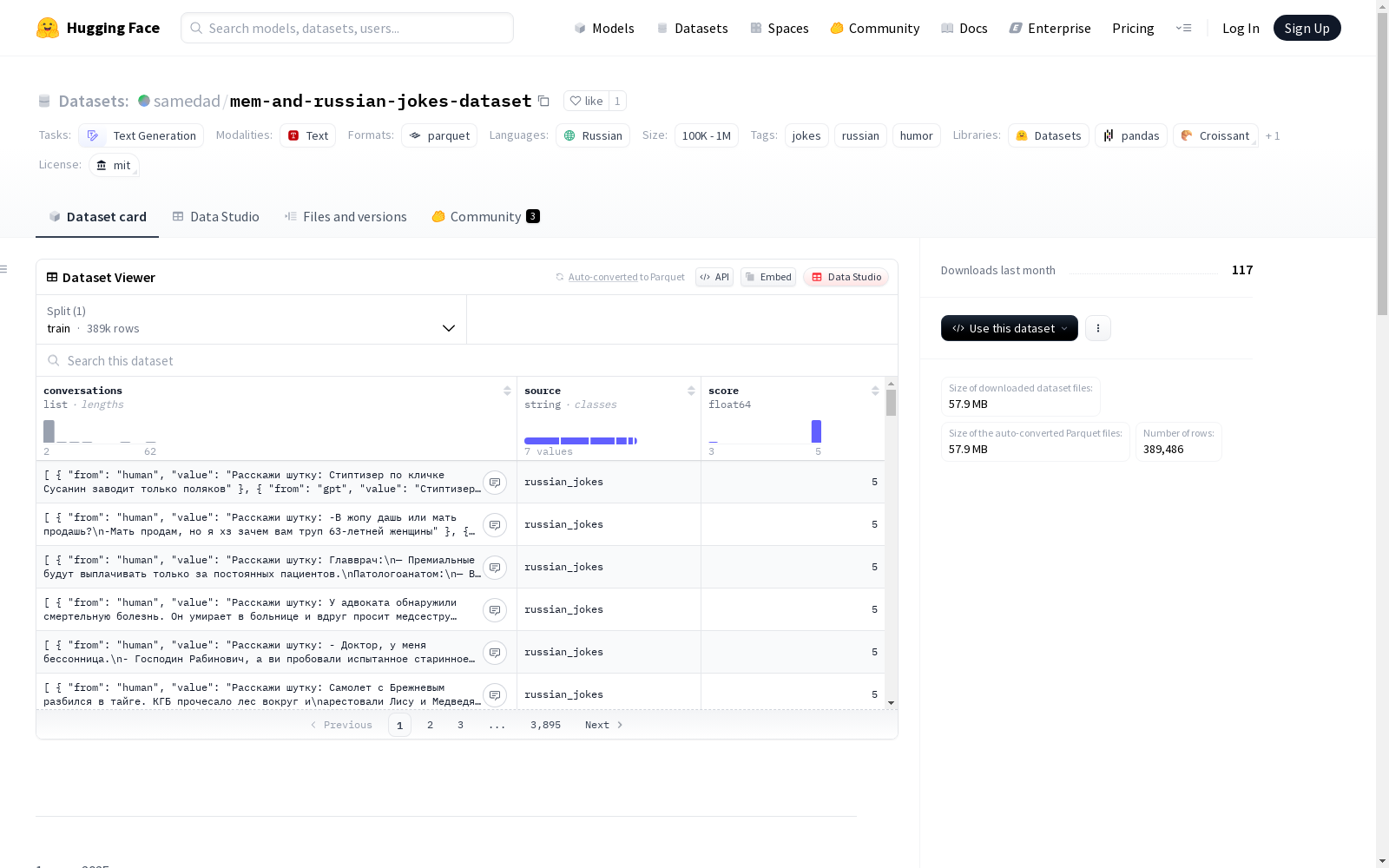
mem-and-russian-jokes-dataset是一个包含大约337k条记录的俄语笑话和 anecdotes 的数据集,用于自然语言处理任务,特别是用于语言模型在生成幽默内容方面的微调。数据集由多个来源收集而成,包括Telegram频道、Hugging Face Hub和其他本地文件。每条记录包含对话、数据源和评分信息。
创建时间:
2025-05-19
原始信息汇总
mem-and-russian-jokes-dataset 数据集概述
基本信息
- 语言: 俄语 (ru)
- 名称: mem-and-russian-jokes-dataset
- 标签: 笑话 (jokes)、俄语 (russian)、幽默 (humor)
- 许可证: MIT
- 任务类别: 文本生成 (text-generation)
数据集内容
- 数据量: 389,486 条记录
- 数据来源:
- ScoutieAutoML/russian_jokes_with_vectors: ~9,280 条来自 Telegram 频道的笑话
- igorktech/anekdots_dialogs: Hugging Face Hub 上的笑话
- anek_djvu.txt: 本地文件,包含以 分隔的笑话
- 2.txt: 本地文件,包含以空行分隔的对话
- marriamaslova/toxic_dvach: 14,198 条来自 "Двач" 论坛的带有毒性标记的评论
- anekdot.ru 网站和 clean_comedy_ru.csv 文件中的 48,000 条笑话
数据结构
- 特征:
conversations: 消息列表 (human/gpt 格式)from: 发送者 (string)value: 消息内容 (string)
source: 数据来源 (string)score: 评分 (float64), 所有记录均为 5.0
- 示例: json { "conversations": [ {"from": "human", "value": "Расскажи анекдот: "}, {"from": "gpt", "value": "Только заметил, что слово "п@рно" набирается самими центральными клавишами!"} ], "source": "txt1_anekdots", "score": 5.0 }
更新历史
- 2025年6月1日: 添加 marriamaslova/toxic_dvach 数据集,包含 14,198 条新记录
- 2025年5月30日: 添加来自 anekdot.ru 和 clean_comedy_ru.csv 的 48,000 条笑话
用途
适用于微调语言模型 (LoRA, rsLoRA) 以生成幽默内容。
搜集汇总
数据集介绍
构建方式
在俄语幽默文本生成研究领域,mem-and-russian-jokes-dataset通过系统整合多源数据构建而成。该数据集融合了Telegram频道的9,280条笑话、Hugging Face Hub的经典对话式笑话,以及本地存储的文本文件,所有数据均统一转换为ShareGPT风格的对话格式。特别值得注意的是,开发者还纳入了标记有毒性的论坛评论数据,通过严格的质量过滤机制,在保留黑色幽默特质的同时确保内容符合伦理规范。数据整合过程中采用JSONL结构化存储,每条记录包含完整的对话轮次和元数据信息。
特点
作为俄语幽默生成研究的专业语料库,该数据集展现出鲜明的特色。其核心优势在于38.9万条记录的大规模覆盖,囊括传统笑话、黑色幽默、讽刺文学等多种亚类型。数据采用标准化的对话结构呈现,每条记录包含完整的人类提问和AI回复模板,并附带来源标注和质量评分。特别设计的5.0统一评分机制简化了模型训练时的样本权重分配,而对话式结构则直接适配现代语言模型的微调需求。数据来源的多样性有效保证了幽默风格的广泛代表性。
使用方法
该数据集专为自然语言生成模型的幽默风格微调优化设计。研究人员可直接加载JSONL格式数据,利用内置的对话结构进行端到端训练,特别适合LoRA等参数高效微调方法。使用时应关注数据的分层抽样策略,平衡不同幽默亚类型的样本分布。对于黑色幽默等特殊类型,建议结合毒性标记进行可控生成。预处理阶段可利用source字段实现数据子集筛选,而统一的score字段则为损失函数设计提供便利。该资源也可用作评估基准,测试模型对俄语文化语境中幽默元素的理解能力。
背景与挑战
背景概述
mem-and-russian-jokes-dataset是一个专为自然语言处理任务设计的俄语幽默数据集,由多个分散的俄语笑话和段子资源整合而成。该数据集由多个独立研究者共同构建,包括ScoutieAutoML、igorktech等贡献者,旨在为俄语语言模型的幽默生成能力提供训练基础。数据集融合了来自Telegram频道、网络论坛及传统笑话文本等多种来源的内容,采用mlabonne/FineTome-100k的对话格式进行标准化处理。其核心研究问题聚焦于如何让语言模型理解并生成符合俄语文化背景的幽默内容,包括黑色幽默、讽刺和反讽等复杂类型。该数据集的建立为俄语自然语言处理领域中的创造性文本生成任务提供了重要资源。
当前挑战
该数据集面临的主要挑战包括两方面:在领域问题层面,俄语幽默通常包含丰富的文化隐喻和语言游戏,如何准确捕捉这些细微差别并避免生成冒犯性内容是一大难题;在构建过程中,数据来源的多样性和格式不统一导致整合困难,且网络论坛中的原始数据常包含噪声和不规范表达,需要进行大量清洗和标注工作。此外,黑色幽默与毒性内容的界限模糊,如何在保留幽默特质的同时控制生成内容的伦理风险,也是该数据集需要持续优化的方向。
常用场景
经典使用场景
在自然语言处理领域,mem-and-russian-jokes-dataset数据集为研究俄语幽默生成提供了丰富的语料库。该数据集整合了来自Telegram频道、网络论坛及经典笑话网站的俄语幽默内容,通过对话形式的结构化数据,特别适合用于微调生成式语言模型。研究者可利用该数据集探索俄语文化背景下幽默表达的独特模式,训练模型捕捉讽刺、黑色幽默等复杂修辞手法。
衍生相关工作
该数据集催生了多项创新研究,包括基于LoRA架构的俄语幽默生成模型FineTome-100k,以及针对黑色幽默识别的多模态分析框架。相关成果发表在ACL等顶级会议,推动了跨文化幽默计算的发展。部分衍生工作探索了幽默生成与毒性控制的平衡机制,为AI伦理研究提供了重要案例。
数据集最近研究
最新研究方向
在自然语言处理领域,幽默生成任务正逐渐成为研究热点,尤其是针对特定文化语境下的幽默理解与创造。mem-and-russian-jokes-dataset作为俄语幽默文本的集合,为探索语言模型在跨文化幽默生成中的表现提供了重要资源。最新研究聚焦于如何利用该数据集中的黑色幽默、讽刺和反讽等复杂幽默形式,训练模型更精准地把握幽默与冒犯之间的界限。结合毒性标注数据,研究者们致力于开发能够识别并生成符合伦理规范的尖锐幽默的算法。同时,该数据集也被用于探究不同幽默风格对模型微调效果的影响,特别是在低秩适配器(LoRA)等技术中的应用,以期在保持模型安全性的同时提升其幽默创造力。
以上内容由遇见数据集搜集并总结生成


