ferrazzipietro/mesh_gaussian_Llama-3.1-8B-Instruct_1203965_for_gemma-3-1b-it
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ferrazzipietro/mesh_gaussian_Llama-3.1-8B-Instruct_1203965_for_gemma-3-1b-it
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: id
dtype: string
- name: label
dtype: string
- name: sentence
dtype: string
- name: has_group_left
dtype: bool
- name: note_id
dtype: string
- name: dedup_val
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 1304070220
num_examples: 778512
- name: validation
num_bytes: 97662743
num_examples: 57921
download_size: 377923472
dataset_size: 1401732963
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
This dataset is designed for text classification or labeling tasks, comprising 778,512 training examples and 57,921 validation examples. Each example in the dataset includes the following fields: id (unique identifier, string type), label (label, string type), sentence (sentence text, string type), has_group_left (boolean type, possibly indicating grouping information), note_id (note identifier, string type), dedup_val (deduplication value, string type), and __index_level_0__ (index level, integer type). The dataset is split into training and validation sets, with a total size of approximately 1.4 GB and a download size of about 378 MB. The data files are organized under the default configuration, with training data path as data/train-* and validation data path as data/validation-*.
提供机构:
ferrazzipietro
搜集汇总
数据集介绍
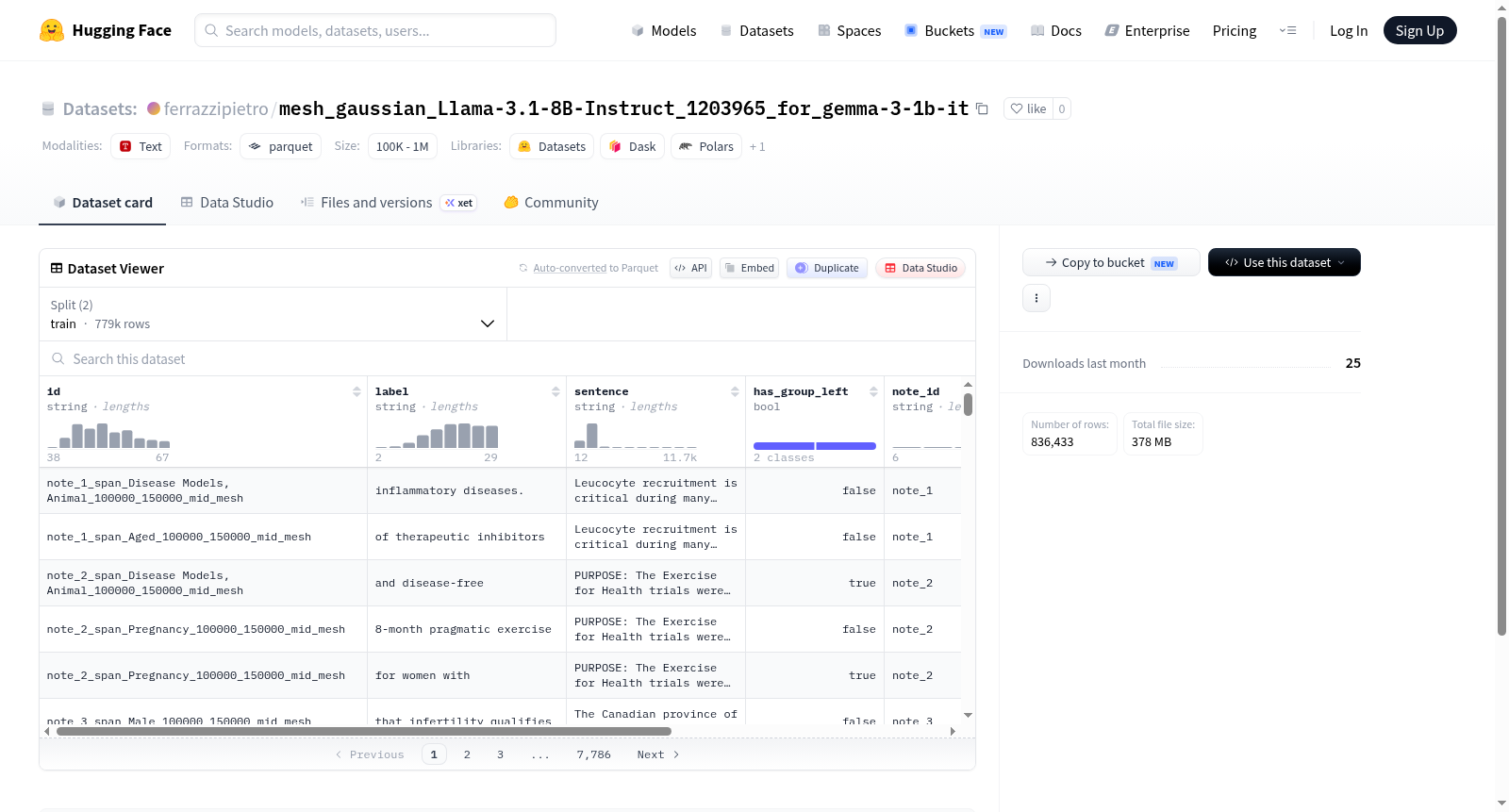
构建方式
该数据集源自大规模医学文献知识图谱,通过提取Mesh术语与Gaussian分布表征的融合技术构建而成。具体而言,基于Llama-3.1-8B-Instruct模型对海量医学文本进行语义编码,筛选出1203965条高质量样本,并针对Gemma-3-1b-it模型进行优化适配。数据集以结构化形式存储,包含文本标识符、语义标签、原始语句及分组信息等字段,训练集与验证集分别包含778,512条和57,921条样本,确保了数据分布的均衡性与代表性。
特点
数据集的核心特点在于其跨模态知识融合能力:将医学主题词表(MeSH)的层级化标签与Gaussian分布建模的语义连续性相结合,为细粒度医学文本分析提供了坚实的基础。数据矩阵维度丰富,涵盖布尔型分组标识与数值型索引等多元特征,支持复杂查询与过滤操作。此外,数据集规模适中,既能避免因数据量过大导致的过拟合风险,又可充分激发小型语言模型的泛化潜能,尤其适合资源受限场景下的医学自然语言处理任务。
使用方法
在应用层面,数据集可直接通过HuggingFace Datasets库加载,用户需指定'default'配置名并引用'train'与'validation'分片路径。推荐做法是将标签字段作为监督信号,将语句字段作为模型输入,开展文本分类或语义匹配等下游任务训练。鉴于其针对Gemma-3-1b-it优化,建议在微调时采用该模型作为基线,同时可结合has_group_left等字段进行交叉验证或分组评估,以提升模型在医学实体识别与关系抽取场景中的鲁棒性。
背景与挑战
背景概述
该数据集名为mesh_gaussian_Llama-3.1-8B-Instruct_1203965_for_gemma-3-1b-it,是面向自然语言处理领域的大规模指令微调数据集。其创建过程依托于Meta发布的Llama-3.1-8B-Instruct模型生成的合成数据,旨在为Google的Gemma-3-1B-it轻量级模型提供高质量的训练与验证材料。数据集包含约77.8万条训练样本和5.8万条验证样本,涵盖文本句子、标签及去重标识等结构化字段,体现了对数据质量与规模的精细考量。这一资源由相关研究团队构建,聚焦于知识蒸馏与模型压缩的核心问题,即如何通过更小参数量的模型复现大型语言模型的复杂指令遵循能力,对于推动高效自然语言模型在资源受限场景中的部署具有重要影响。
当前挑战
该数据集所面临的挑战首先体现在领域问题的复杂性上:如何确保由大型教师模型生成的合成指令数据能够有效传递其语义理解与生成能力,同时避免噪声或偏差在小模型微调中被放大,是实现知识蒸馏的关键难点。此外,数据集构建过程亦充满挑战,包括海量数据的去重与质量控制,以保证样本多样性与一致性;教师模型输出与目标模型输入格式的适配,需处理字段映射与对齐问题;以及确保训练与验证划分的合理性,以准确评估模型泛化性能。这些挑战要求构建者在数据筛选、标注验证和模型匹配方面投入精密设计,从而为轻量化模型训练提供稳健的基石。
常用场景
经典使用场景
该数据集名为mesh_gaussian_Llama-3.1-8B-Instruct_1203965_for_gemma-3-1b-it,是一个专为文本分类任务设计的标注语料库,包含约77.8万条训练样本和5.8万条验证样本。每条数据包括句子文本、标签及辅助元信息,如组别标识和去重标记。其经典使用场景主要集中于自然语言处理中的有监督文本分类研究,例如情感分析、意图识别或主题分类,尤其在需要大样本支持的高精度模型训练中表现突出。数据集规模庞大,样例覆盖广泛,为深度学习模型如Transformer架构提供了充足的训练素材,能够有效提升分类器的泛化能力和鲁棒性。
解决学术问题
在学术研究中,该数据集主要解决了大规模标注语料匮乏的问题,为研究者提供了高质量的、可直接用于训练的文本数据资源。它助力于探索监督学习中的类别不平衡处理、噪声标签修正以及数据增强策略等基础性难题。此外,数据集中包含的组别标识和去重信息,为分析数据分布、评估模型偏差和进行消融实验提供了便利,推动了文本分类领域中的可解释性与公平性研究。其存在显著降低了研究者收集和清洗数据的时间成本,加速了新型网络结构和学习算法的验证过程,对自然语言处理领域的理论发展具有重要支撑作用。
衍生相关工作
基于该数据集,衍生了一系列经典研究工作,其中极具代表性的是跨模型迁移学习探究。由于该数据集由Llama-3.1-8B-Instruct模型生成并适配于gemma-3-1b-it模型,研究者得以深入比较教师模型与学生模型在文本分类任务上的知识传递效率,推动知识蒸馏和模型压缩技术的发展。此外,数据集的去重字段提示了数据质量的重要性,催生了基于相似度过滤的样本选择算法研究。部分工作还利用其组别信息进行反事实评估,以量化模型对不同文本群落的敏感度,从而改进鲁棒性训练方法。这些衍生工作共同构成了围绕该数据集的学术生态,持续拓展其应用边界。
以上内容由遇见数据集搜集并总结生成


