GeneZC/MT-Bench-ZH
收藏Hugging Face2024-01-03 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/GeneZC/MT-Bench-ZH
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- text-generation
- conversational
language:
- zh
size_categories:
- n<1K
---
# 💬 MT-Bench-ZH
👻 [GitHub](https://github.com/GeneZC/MiniMA/tree/main/mt_bench_zh)
## 🎯 Motivation
MiniChat-1/1.5/2-3B are all instruction-following language models that could handle Chinese instructions, however, there is currently no instruciton-following benchamrk specialized for Chinese. Due to this, our previous evaluation has been limited to English-only benchmarks (i.e., AlpacaEval and MT-Bench).
To this demand, MT-Bench-ZH is made to mitigate this. MT-Bench-ZH is basically translated from MT-Bench-ZH by GPT-4 and further checked by human. Hopefully, MT-Bench-ZH could help the communnity to develop better instruction-following language models that are able to tackle Chinese instructions.
## 🚀 Quick Start
> [!NOTE]
> The code is either copied or modified from [FastChat](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge), yet we currently only support `single` mode judgment.
> Please refer to FastChat for more details.
### Install FastChat
```bash
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
pip install -e ".[model_worker,webui]"
```
### Generate Responses
```bash
python gen_model_answer.py --model-path GeneZC/MiniChat-2-3B --model-id minichat --bench-name mt_bench_zh --max-new-token 1536
```
### Evaluate Responses
```bash
export OPENAI_API_KEY=XXXXXX # Set the OpenAI API key.
python gen_judgment.py --model-list minichat --bench-name mt_bench_zh --judge-file data/judge_prompts_zh.jsonl --parallel 4
```
### Display Results
```bash
python show_result.py --bench-name mt_bench_zh
```
## 🏆 Leaderboard
|Method|MT-Bench-ZH|
|--|--|
|🥇 GPT-4|8.96|
|🥈 Zephyr-7B-Beta|6.27<sup>#</sup>|
|🥉 Qwen-Chat-7B|6.24|
|MiniChat-2-3B|6.04|
|Qwen-Chat-1.8B|5.65|
|LLaMA-2-Chat-7B|5.43<sup>#</sup>|
|Vicuna-7B|5.22<sup>#</sup>|
|StableLM-Zephyr-3B|4.31<sup>#</sup>|
|Rocket-3B|4.07<sup>#</sup>|
|Phi-2-DPO|1.59<sup>#</sup><sup>$</sup>|
<sup>#</sup> specialized mainly for English.
<sup>$</sup> finetuned without multi-turn instruction data.
## 🙌 Contributions
You can raise questions related to the benchmark by opening an issue. Or you can add results of other models to the leaderboard by opening a pull request. For the leaderboard, related files should be attached for sanity check (i.e., a separate model response file should be uploaded, and the GPT-4 judgement file should be updated).
许可证:Apache-2.0
任务类别:
- 文本生成
- 对话式
语言:
- 中文
规模类别:
- 数据量小于1000(n<1K)
# 💬 MT-Bench-ZH
👻 [GitHub仓库](https://github.com/GeneZC/MiniMA/tree/main/mt_bench_zh)
## 🎯 项目动机
MiniChat-1/1.5/2-3B均为支持中文指令的指令跟随大语言模型,但目前尚无专门针对中文场景的指令跟随评测基准。此前我们的模型评估只能局限于英文基准(如AlpacaEval与MT-Bench)。为填补这一需求空白,我们开发了MT-Bench-ZH。该基准本质上由GPT-4翻译自MT-Bench,并经人工进一步校核。期望MT-Bench-ZH能够助力社区开发出更优秀的、可适配中文指令的指令跟随大语言模型。
## 🚀 快速上手
> [!提示]
> 本项目代码部分复刻或修改自 [FastChat](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge),目前仅支持`单轮`(single)模式评测。
> 更多细节请参考FastChat官方仓库。
### 安装FastChat
bash
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
pip install -e ".[model_worker,webui]"
### 生成模型响应
bash
python gen_model_answer.py --model-path GeneZC/MiniChat-2-3B --model-id minichat --bench-name mt_bench_zh --max-new-token 1536
### 评测模型响应
bash
export OPENAI_API_KEY=XXXXXX # 设置OpenAI API密钥
python gen_judgment.py --model-list minichat --bench-name mt_bench_zh --judge-file data/judge_prompts_zh.jsonl --parallel 4
### 展示评测结果
bash
python show_result.py --bench-name mt_bench_zh
## 🏆 排行榜
|评测方法|MT-Bench-ZH得分|
|--|--|
|🥇 GPT-4|8.96|
|🥈 Zephyr-7B-Beta|6.27<sup>#</sup>|
|🥉 Qwen-Chat-7B|6.24|
|MiniChat-2-3B|6.04|
|Qwen-Chat-1.8B|5.65|
|LLaMA-2-Chat-7B|5.43<sup>#</sup>|
|Vicuna-7B|5.22<sup>#</sup>|
|StableLM-Zephyr-3B|4.31<sup>#</sup>|
|Rocket-3B|4.07<sup>#</sup>|
|Phi-2-DPO|1.59<sup>#</sup><sup>$</sup>|
<sup>#</sup> 该模型主要针对英文场景优化。
<sup>$</sup> 该模型未使用多轮指令数据进行微调。
## 🙌 贡献指南
您可通过提交Issue反馈与该基准相关的问题,或通过发起Pull Request向排行榜新增其他模型的评测结果。如需新增排行榜条目,请附带相关文件以进行合规性校验:即需单独上传模型响应文件,并更新GPT-4生成的评测结果文件。
提供机构:
GeneZC
原始信息汇总
MT-Bench-ZH 数据集概述
数据集基本信息
- 许可证:Apache-2.0
- 任务类别:
- 文本生成
- 对话系统
- 语言:中文
- 数据规模:n<1K
数据集动机
MT-Bench-ZH 是为了满足中文指令遵循语言模型的评估需求而创建的。该数据集由 GPT-4 从 MT-Bench 翻译并经人工校对,旨在帮助社区开发能够处理中文指令的更优秀的指令遵循语言模型。
快速开始
安装 FastChat
bash git clone https://github.com/lm-sys/FastChat.git cd FastChat pip install -e ".[model_worker,webui]"
生成响应
bash python gen_model_answer.py --model-path GeneZC/MiniChat-2-3B --model-id minichat --bench-name mt_bench_zh --max-new-token 1536
评估响应
bash export OPENAI_API_KEY=XXXXXX # 设置 OpenAI API 密钥 python gen_judgment.py --model-list minichat --bench-name mt_bench_zh --judge-file data/judge_prompts_zh.jsonl --parallel 4
显示结果
bash python show_result.py --bench-name mt_bench_zh
排行榜
| 方法 | MT-Bench-ZH |
|---|---|
| 🥇 GPT-4 | 8.96 |
| 🥈 Zephyr-7B-Beta | 6.27<sup>#</sup> |
| 🥉 Qwen-Chat-7B | 6.24 |
| MiniChat-2-3B | 6.04 |
| Qwen-Chat-1.8B | 5.65 |
| LLaMA-2-Chat-7B | 5.43<sup>#</sup> |
| Vicuna-7B | 5.22<sup>#</sup> |
| StableLM-Zephyr-3B | 4.31<sup>#</sup> |
| Rocket-3B | 4.07<sup>#</sup> |
| Phi-2-DPO | 1.59<sup>#</sup><sup>$</sup> |
<sup>#</sup> 主要针对英语进行优化。
<sup>$</sup> 未使用多轮指令数据进行微调。
贡献
可以通过提交 issue 提出与基准测试相关的问题,或者通过提交 pull request 将其他模型的结果添加到排行榜中。对于排行榜,需要附上相关文件进行合理性检查(例如,应上传单独的模型响应文件,并更新 GPT-4 判断文件)。
搜集汇总
数据集介绍
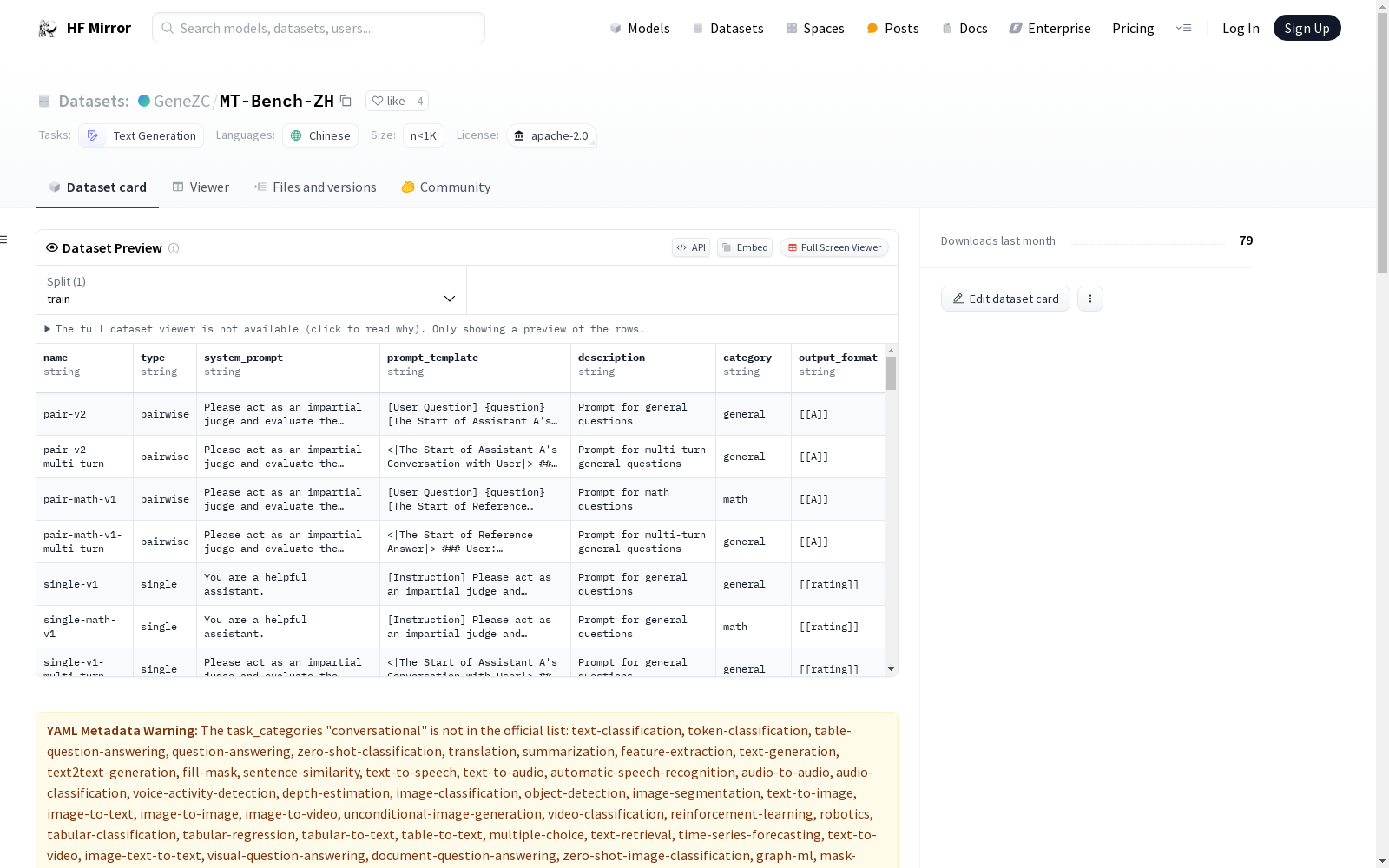
构建方式
MT-Bench-ZH数据集的构建旨在填补中文指令遵循语言模型评估的空白。该数据集由GPT-4翻译自MT-Bench,并经过人工校对,确保其准确性和适用性。通过这种方式,MT-Bench-ZH为中文指令遵循模型的开发和评估提供了一个专门的基准。
特点
MT-Bench-ZH数据集的主要特点在于其专门针对中文指令遵循模型的评估需求。该数据集不仅涵盖了多种语言模型的评估,还通过GPT-4的翻译和人工校对,确保了数据的高质量和准确性。此外,数据集支持单模式判断,便于快速评估和比较不同模型的性能。
使用方法
使用MT-Bench-ZH数据集进行模型评估时,首先需安装FastChat工具,然后通过gen_model_answer.py脚本生成模型响应。接着,利用gen_judgment.py脚本对生成的响应进行评估,并设置OpenAI API密钥以确保评估的准确性。最后,通过show_result.py脚本展示评估结果,便于直观比较各模型的性能。
背景与挑战
背景概述
在自然语言处理领域,指令遵循语言模型的发展日益受到关注,尤其是在多语言环境下的应用。尽管MiniChat-1/1.5/2-3B等模型能够处理中文指令,但缺乏专门针对中文的指令遵循基准测试。为填补这一空白,GeneZC团队于近期推出了MT-Bench-ZH数据集。该数据集由GPT-4翻译并经人工校对,旨在为中文指令遵循模型的评估提供标准化的测试平台。MT-Bench-ZH的推出不仅促进了中文自然语言处理技术的发展,也为全球多语言模型的研究提供了新的视角。
当前挑战
MT-Bench-ZH数据集在构建过程中面临多重挑战。首先,翻译和校对过程需要确保语言的准确性和文化适应性,这对数据质量提出了高要求。其次,由于当前支持的评估模式仅限于‘single’模式,模型的多轮对话能力未能得到充分测试,这限制了数据集的应用范围。此外,尽管已有一些模型在MT-Bench-ZH上进行了测试,但大多数模型仍主要针对英文进行优化,如何在多语言环境下实现模型的均衡发展仍是一个亟待解决的问题。
常用场景
经典使用场景
在自然语言处理领域,MT-Bench-ZH数据集的经典使用场景主要集中在评估和改进中文指令遵循语言模型的性能。该数据集通过提供一系列中文指令,帮助研究人员和开发者测试模型在处理中文文本生成和对话任务中的表现。通过对比不同模型的响应质量,MT-Bench-ZH为优化中文语言模型的指令遵循能力提供了宝贵的基准。
实际应用
在实际应用中,MT-Bench-ZH数据集被广泛用于开发和优化能够处理中文指令的智能助手和聊天机器人。通过使用该数据集进行模型训练和评估,开发者能够提升系统在真实世界中的交互能力,从而更好地满足用户需求。此外,MT-Bench-ZH还支持企业级应用,如客户服务自动化和智能客服系统,显著提高了服务效率和用户体验。
衍生相关工作
MT-Bench-ZH数据集的发布激发了一系列相关研究和工作。例如,基于该数据集,研究人员开发了多种中文指令遵循模型,如MiniChat-2-3B和Qwen-Chat-7B,这些模型在多个任务中表现出色。此外,MT-Bench-ZH还促进了跨语言模型的研究,探索了如何将中文模型的优势迁移到其他语言环境中,推动了多语言自然语言处理技术的发展。
以上内容由遇见数据集搜集并总结生成


