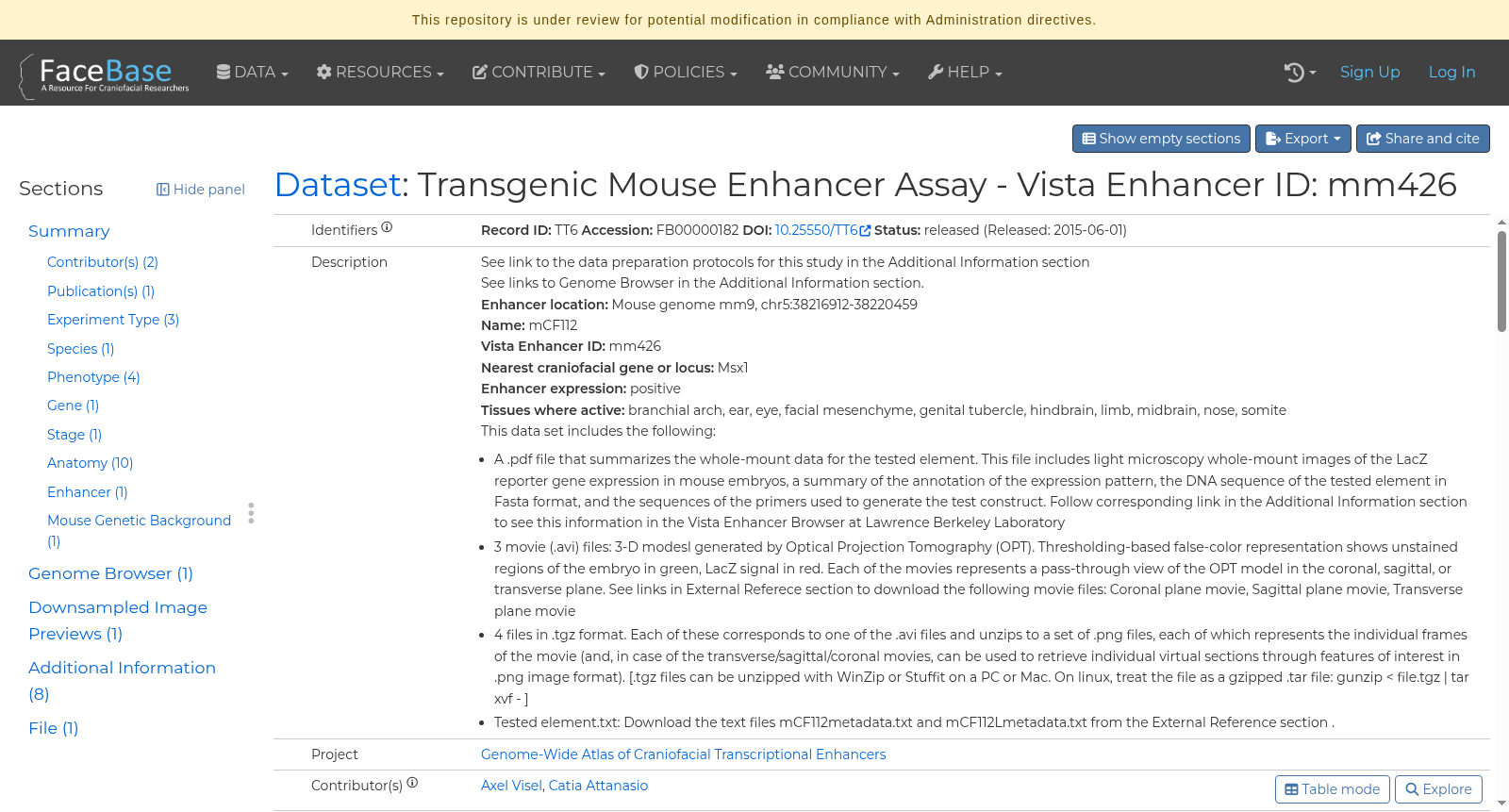
Transgenic Mouse Enhancer Assay - Vista Enhancer ID: mm426
收藏Mendeley Data2024-01-31 更新2024-06-27 收录
下载链接:
https://www.facebase.org/chaise/record/#1/isa:dataset/RID=TT6
下载链接
链接失效反馈官方服务:
资源简介:
See link to the data preparation protocols for this study in the Additional Information section See links to Genome Browser in the Additional Information section. **Enhancer location:** Mouse genome mm9, chr5:38216912-38220459 **Name:** mCF112 **Vista Enhancer ID:** mm426 **Nearest craniofacial gene or locus:** Msx1 **Enhancer expression:** positive **Tissues where active:** branchial arch, ear, eye, facial mesenchyme, genital tubercle, hindbrain, limb, midbrain, nose, somite This data set includes the following: * A .pdf file that summarizes the whole-mount data for the tested element. This file includes light microscopy whole-mount images of the LacZ reporter gene expression in mouse embryos, a summary of the annotation of the expression pattern, the DNA sequence of the tested element in Fasta format, and the sequences of the primers used to generate the test construct. Follow corresponding link in the Additional Information section to see this information in the Vista Enhancer Browser at Lawrence Berkeley Laboratory * 3 movie (.avi) files: 3-D modesl generated by Optical Projection Tomography (OPT). Thresholding-based false-color representation shows unstained regions of the embryo in green, LacZ signal in red. Each of the movies represents a pass-through view of the OPT model in the coronal, sagittal, or transverse plane. See links in External Referece section to download the following movie files: Coronal plane movie, Sagittal plane movie, Transverse plane movie * 4 files in .tgz format. Each of these corresponds to one of the .avi files and unzips to a set of .png files, each of which represents the individual frames of the movie (and, in case of the transverse/sagittal/coronal movies, can be used to retrieve individual virtual sections through features of interest in .png image format). [.tgz files can be unzipped with WinZip or Stuffit on a PC or Mac. On linux, treat the file as a gzipped .tar file: gunzip < file.tgz | tar xvf - ] * Tested element.txt: Download the text files mCF112metadata.txt and mCF112Lmetadata.txt from the External Reference section .
本研究的数据制备方案及基因组浏览器(Genome Browser)的相关链接,请参见补充信息(Additional Information)章节。
**增强子位置:** 小鼠基因组mm9,5号染色体:38216912-38220459
**名称:** mCF112
**Vista增强子编号(Vista Enhancer ID):** mm426
**最近的颅面基因或基因座:** Msx1
**增强子表达:** 阳性
**活性组织:** 鳃弓、耳、眼、面部间充质、生殖结节、后脑、肢体、中脑、鼻、体节
本数据集涵盖以下内容:
* 1份PDF文件:汇总了受试元件的整装数据。该文件包含小鼠胚胎中LacZ报告基因表达的光学显微镜整装图像、表达模式注释摘要、Fasta格式的受试元件DNA序列,以及用于构建测试载体的引物序列。相关内容可通过补充信息章节中的对应链接,在劳伦斯伯克利实验室的Vista增强子浏览器(Vista Enhancer Browser)中查看。
* 3个AVI格式视频文件:由光学投影断层扫描(Optical Projection Tomography, OPT)生成的三维模型。基于阈值的伪彩色标注中,胚胎未染色区域以绿色显示,LacZ信号以红色显示。每个视频分别展示OPT模型在冠状面、矢状面或横断面的穿透视图。可通过外部参考(External Reference)章节中的链接下载以下视频文件:冠状面视图视频、矢状面视图视频、横断面视图视频。
* 4个TGZ格式压缩文件:每个文件对应1个AVI视频文件,解压后将得到一组PNG格式图像文件,每个图像对应视频的单帧画面(对于冠状、矢状及横断面视图视频,这些PNG文件可用于提取目标特征的虚拟切片图像)。[TGZ文件解压方法:在PC或Mac设备上可使用WinZip或Stuffit工具;在Linux系统中,可将其视为gzip压缩的TAR文件,执行命令`gunzip < file.tgz | tar xvf -`即可解压。]
* 受试元件相关文本:请从外部参考章节下载mCF112metadata.txt与mCF112Lmetadata.txt文本文件。
创建时间:
2024-01-31
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集记录了增强子mCF112(Vista ID: mm426)在转基因小鼠胚胎中的活性检测结果,使用LacZ报告基因和光学投影断层扫描技术进行成像分析。增强子位于小鼠基因组chr5特定区域,与颅面发育基因Msx1相邻,在E11.5胚胎阶段的多类组织中表达阳性,包括鳃弓、耳、眼和面部间充质等。数据集包含实验总结文档、3D模型视频和图像序列文件,用于研究增强子在颅面发育中的调控功能。
以上内容由遇见数据集搜集并总结生成


