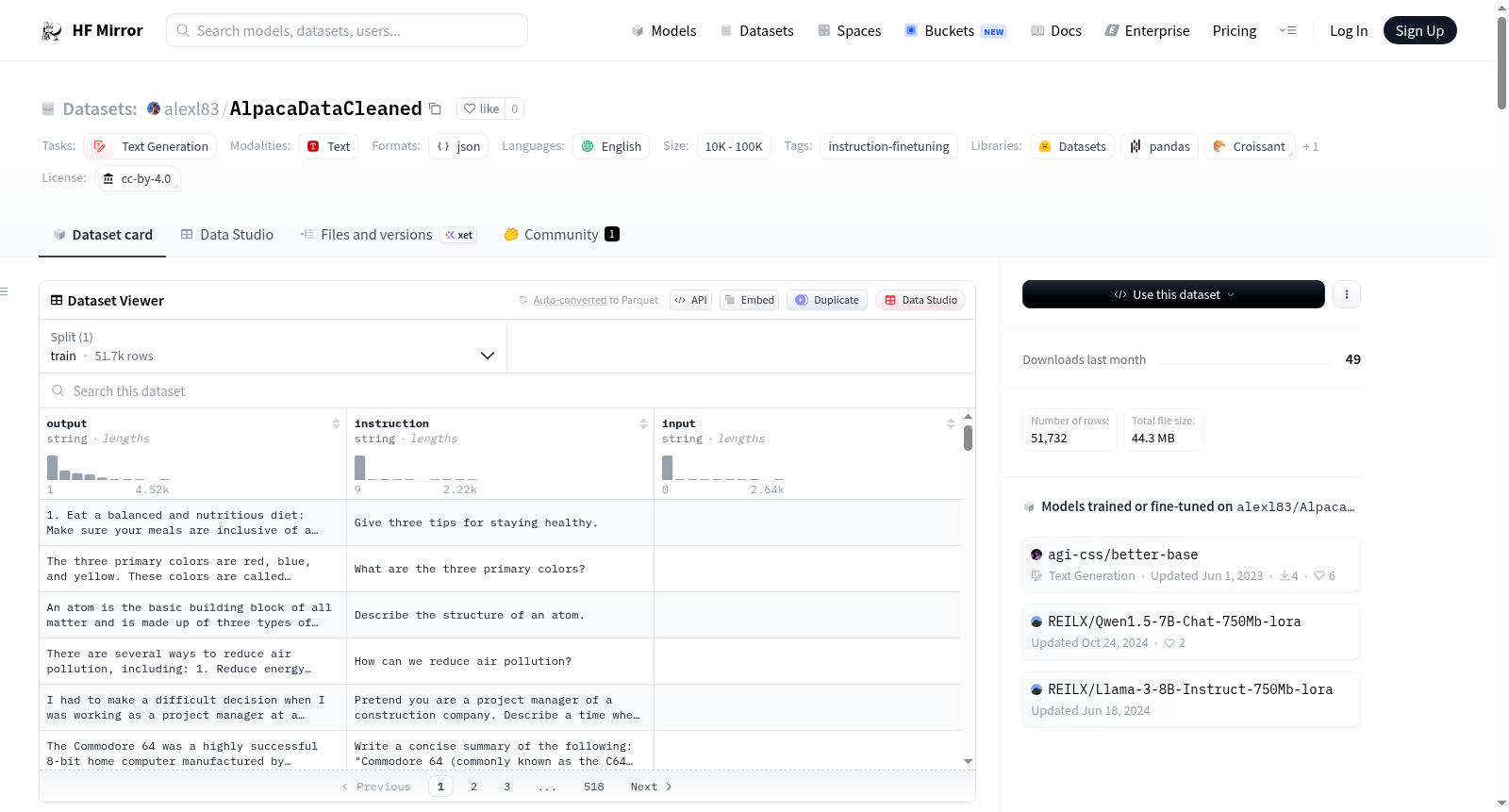
---
license: cc-by-4.0
language:
- en
tags:
- instruction-finetuning
pretty_name: Alpaca-Cleaned
task_categories:
- text-generation
size_categories:
- 10K<n<100K
---
# Dataset Card for Alpaca-Cleaned
- **Repository:** https://github.com/gururise/AlpacaDataCleaned
## Dataset Description
This is a cleaned version of the original Alpaca Dataset released by Stanford. The following issues have been identified in the original release and fixed in this dataset:
1. **Hallucinations:** Many instructions in the original dataset had instructions referencing data on the internet, which just caused GPT3 to hallucinate an answer.
```
"instruction":"Summarize the given article in 200 Words.",
"input": "https://www.bbc.com/news/world-51461830",
"output": "The recent protests in Belarus are part of a growing wave of discontent against the rule of Alexander Lukashenko, who has led the country since 1994. Demonstrations against his government have been ongoing since August, and come in the wake of an election widely seen as rigged. As police and security forces have cracked down on protesters, the movement has only grown, with hundreds of thousands of people taking to the streets to call for new leadership. Human rights activists have accused the government of using extreme violence in order prosecute protesters, leading to an international outcry and sanctions from the European Union. As the situation in Belarus continues to unfold, the international community is monitoring the situation closely - hoping for a peaceful resolution, while also standing firm against the oppressive tactics employed by the Belarusian state."
"instruction": "Classify the following shape according to simple geometry.",
"input": "<Picture Attached>",
"output": "Triangle"
"instruction": "Given a recent news article, write a headline for it.",
"input": "https://www.news.example.com/article-1",
"output": "\"NASA Launches a Mars 2020 Mission to Search for Signs of Ancient Life\""
```
2. **Merged Instructions:** There were many instructions that were merged together in the original dataset for some reason.
```
"instruction": "Should I invest in stocks?",
"input": "",
"output": "It depends on your individual situation. Investing in stocks carries a certain amount of risk but can also offer potential rewards. Make sure to research the different types of stocks, understand the risks and rewards, and develop a plan that works for you.\n##\n18. Instruction: Identify the noun in the following sentence:\n18. Input:\nThe large apple was delicious.\n18. Output:\nApple"
```
3. **Empty outputs:** Some entries in the original dataset had empty outputs.
```
"instruction": "Calculate the area of the following shape in square centimeters.",
"input": "rectangle of size 4 cm x 5 cm",
"output": ""
```
4. **Empty code examples:** Some descriptions in the original dataset were missing code examples, making it difficult to understand the intended behavior of the code.
5. **Instructions to generate images:** Some descriptions in the original dataset included instructions to generate images, something obviously not possible.
```
"instruction": "Create a graphic or logo that visually represents the word \"courage\".",
"input": "",
"output": "<No Output>"
```
6. **N/A outputs:** Some code snippets in the original dataset had N/A outputs.
7. **Inconsistent input field:** The original dataset had inconsistent usage of the input field when it was supposed to be empty.
```
"input":"<no input>"
"input":"No input"
"input":"noinput"
"input":"<noinput>"
```
8. **Wrong answers:** Some instructions/questions in the original dataset had incorrect answers. About 80% of the math problems are estimated to have incorrect answers.
```
"instruction": "Calculate the median of the following data set.",
"input": "1, 2, 4, 5, 8, 9",
"output": "5"
"instruction": "Convert 25m to km.",
"input": "",
"output": "25km"
```
9. **Non-Sensical/Unclear instructions:** Many instructions are unclear, we try to clarify (or re-write) if instructions are non-sensical. Instructions that are slightly unclear, but where one could deduce the meaning are not altered.
```
"instruction": "Freeze the following sample of yogurt for 10 minutes.",
"input": "Yogurt sample",
"output": "<noinput>"
"instruction": "Increase the font size to 12 points.",
"input": "",
"output": "The font size has been increased to 12 points."
```
10. **Extraneous escape and control characters:** The original dataset had several entries with extraneous escape and control characters.
### Original Alpaca Dataset Summary
Alpaca is a dataset of 52,000 instructions and demonstrations generated by OpenAI's `text-davinci-003` engine. This instruction data can be used to conduct instruction-tuning for language models and make the language model follow instruction better.
The authors built on the data generation pipeline from [Self-Instruct framework](https://github.com/yizhongw/self-instruct) and made the following modifications:
- The `text-davinci-003` engine to generate the instruction data instead of `davinci`.
- A [new prompt](https://github.com/tatsu-lab/stanford_alpaca/blob/main/prompt.txt) was written that explicitly gave the requirement of instruction generation to `text-davinci-003`.
- Much more aggressive batch decoding was used, i.e., generating 20 instructions at once, which significantly reduced the cost of data generation.
- The data generation pipeline was simplified by discarding the difference between classification and non-classification instructions.
- Only a single instance was generated for each instruction, instead of 2 to 3 instances as in Self-Instruct.
This produced an instruction-following dataset with 52K examples obtained at a much lower cost (less than $500).
In a preliminary study, the authors also found that the 52K generated data to be much more diverse than the data released by [Self-Instruct](https://github.com/yizhongw/self-instruct/blob/main/data/seed_tasks.jsonl).
### Supported Tasks and Leaderboards
The Alpaca dataset designed for instruction training pretrained language models.
### Languages
The data in Alpaca are in English (BCP-47 en).
## Dataset Structure
### Data Instances
An example of "train" looks as follows:
```json
{
"instruction": "Create a classification task by clustering the given list of items.",
"input": "Apples, oranges, bananas, strawberries, pineapples",
"output": "Class 1: Apples, Oranges\nClass 2: Bananas, Strawberries\nClass 3: Pineapples",
"text": "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\nCreate a classification task by clustering the given list of items.\n\n### Input:\nApples, oranges, bananas, strawberries, pineapples\n\n### Response:\nClass 1: Apples, Oranges\nClass 2: Bananas, Strawberries\nClass 3: Pineapples",
}
```
### Data Fields
The data fields are as follows:
* `instruction`: describes the task the model should perform. Each of the 52K instructions is unique.
* `input`: optional context or input for the task. For example, when the instruction is "Summarize the following article", the input is the article. Around 40% of the examples have an input.
* `output`: the answer to the instruction as generated by `text-davinci-003`.
* `text`: the `instruction`, `input` and `output` formatted with the [prompt template](https://github.com/tatsu-lab/stanford_alpaca#data-release) used by the authors for fine-tuning their models.
### Data Splits
| | train |
|---------------|------:|
| alpaca | 52002 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
Excerpt the [blog post](https://crfm.stanford.edu/2023/03/13/alpaca.html) accompanying the release of this dataset:
> We believe that releasing the above assets will enable the academic community to perform controlled scientific studies on instruction-following language models, resulting in better science and ultimately new techniques to address the existing deficiencies with these models. At the same time, any release carries some risk. First, we recognize that releasing our training recipe reveals the feasibility of certain capabilities. On one hand, this enables more people (including bad actors) to create models that could cause harm (either intentionally or not). On the other hand, this awareness might incentivize swift defensive action, especially from the academic community, now empowered by the means to perform deeper safety research on such models. Overall, we believe that the benefits for the research community outweigh the risks of this particular release. Given that we are releasing the training recipe, we believe that releasing the data, model weights, and training code incur minimal further risk, given the simplicity of the recipe. At the same time, releasing these assets has enormous benefits for reproducible science, so that the academic community can use standard datasets, models, and code to perform controlled comparisons and to explore extensions. Deploying an interactive demo for Alpaca also poses potential risks, such as more widely disseminating harmful content and lowering the barrier for spam, fraud, or disinformation. We have put into place two risk mitigation strategies. First, we have implemented a content filter using OpenAI’s content moderation API, which filters out harmful content as defined by OpenAI’s usage policies. Second, we watermark all the model outputs using the method described in Kirchenbauer et al. 2023, so that others can detect (with some probability) whether an output comes from Alpaca 7B. Finally, we have strict terms and conditions for using the demo; it is restricted to non-commercial uses and to uses that follow LLaMA’s license agreement. We understand that these mitigation measures can be circumvented once we release the model weights or if users train their own instruction-following models. However, by installing these mitigations, we hope to advance the best practices and ultimately develop community norms for the responsible deployment of foundation models.
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
The `alpaca` data is generated by a language model (`text-davinci-003`) and inevitably contains some errors or biases. We encourage users to use this data with caution and propose new methods to filter or improve the imperfections.
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
The dataset is available under the [Creative Commons NonCommercial (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/legalcode).
### Citation Information
```
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
}
```
### Contributions
[More Information Needed]