allenai/ropes
收藏Hugging Face2024-01-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/allenai/ropes
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
- found
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|wikipedia
- original
task_categories:
- question-answering
task_ids:
- extractive-qa
paperswithcode_id: ropes
pretty_name: ROPES
dataset_info:
config_name: plain_text
features:
- name: id
dtype: string
- name: background
dtype: string
- name: situation
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
splits:
- name: train
num_bytes: 12231892
num_examples: 10924
- name: test
num_bytes: 1928508
num_examples: 1710
- name: validation
num_bytes: 1643474
num_examples: 1688
download_size: 1372548
dataset_size: 15803874
configs:
- config_name: plain_text
data_files:
- split: train
path: plain_text/train-*
- split: test
path: plain_text/test-*
- split: validation
path: plain_text/validation-*
default: true
---
# Dataset Card for ROPES
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [ROPES dataset](https://allenai.org/data/ropes)
- **Paper:** [Reasoning Over Paragraph Effects in Situations](https://arxiv.org/abs/1908.05852)
- **Leaderboard:** [ROPES leaderboard](https://leaderboard.allenai.org/ropes)
### Dataset Summary
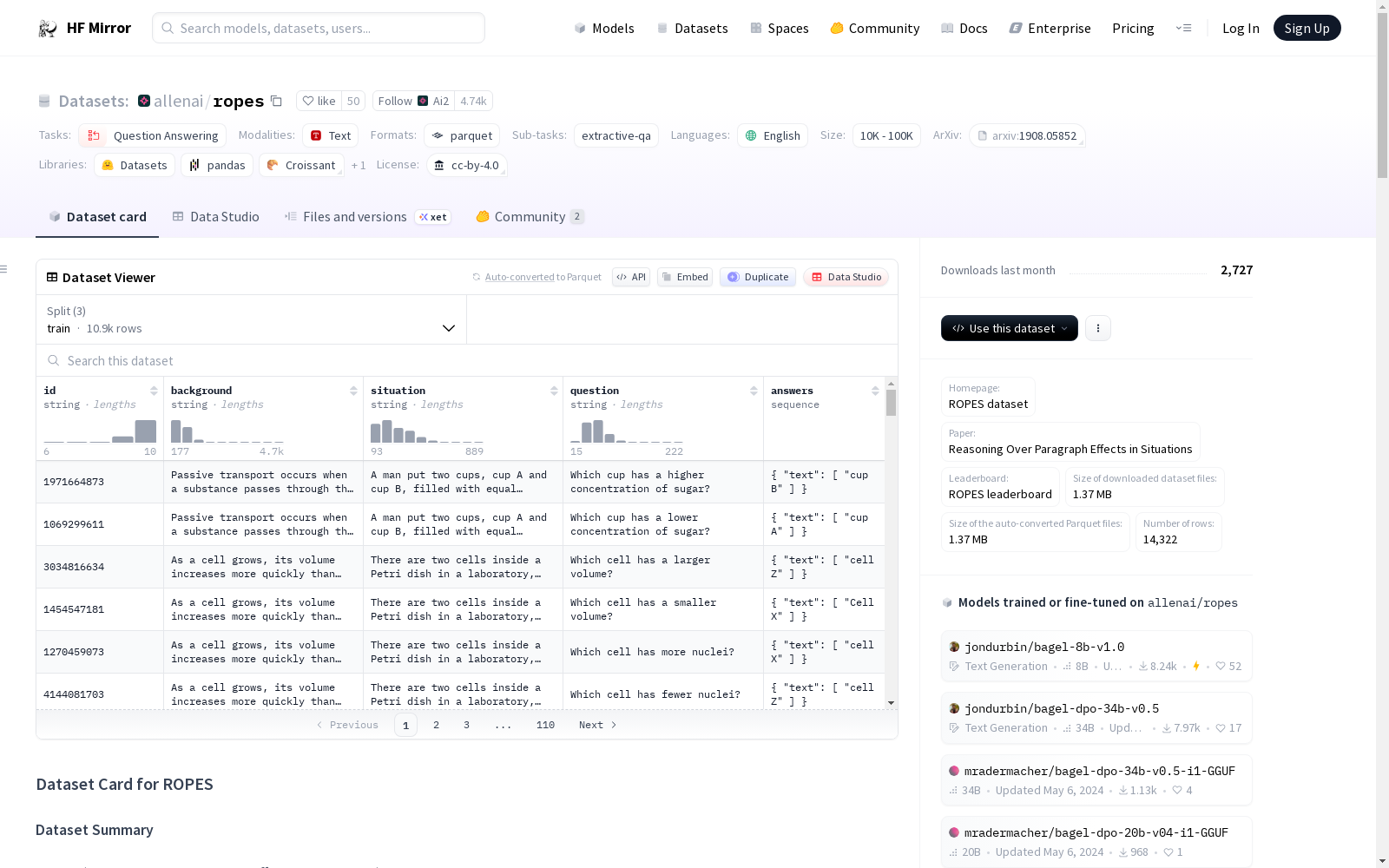
ROPES (Reasoning Over Paragraph Effects in Situations) is a QA dataset which tests a system's ability to apply knowledge from a passage of text to a new situation. A system is presented a background passage containing a causal or qualitative relation(s) (e.g., "animal pollinators increase efficiency of fertilization in flowers"), a novel situation that uses this background, and questions that require reasoning about effects of the relationships in the background passage in the context of the situation.
### Supported Tasks and Leaderboards
The reading comprehension task is framed as an extractive question answering problem.
Models are evaluated by computing word-level F1 and exact match (EM) metrics, following common practice for recent reading comprehension datasets (e.g., SQuAD).
### Languages
The text in the dataset is in English. The associated BCP-47 code is `en`.
## Dataset Structure
### Data Instances
Data closely follow the SQuAD v1.1 format. An example looks like this:
```
{
"id": "2058517998",
"background": "Cancer is a disease that causes cells to divide out of control. Normally, the body has systems that prevent cells from dividing out of control. But in the case of cancer, these systems fail. Cancer is usually caused by mutations. Mutations are random errors in genes. Mutations that lead to cancer usually happen to genes that control the cell cycle. Because of the mutations, abnormal cells divide uncontrollably. This often leads to the development of a tumor. A tumor is a mass of abnormal tissue. As a tumor grows, it may harm normal tissues around it. Anything that can cause cancer is called a carcinogen . Carcinogens may be pathogens, chemicals, or radiation.",
"situation": "Jason recently learned that he has cancer. After hearing this news, he convinced his wife, Charlotte, to get checked out. After running several tests, the doctors determined Charlotte has no cancer, but she does have high blood pressure. Relieved at this news, Jason was now focused on battling his cancer and fighting as hard as he could to survive.",
"question": "Whose cells are dividing more rapidly?",
"answers": {
"text": ["Jason"]
},
}
```
### Data Fields
- `id`: identification
- `background`: background passage
- `situation`: the grounding situation
- `question`: the question to answer
- `answers`: the answer text which is a span from either the situation or the question. The text list always contain a single element.
Note that the answers for the test set are hidden (and thus represented as an empty list). Predictions for the test set should be submitted to the leaderboard.
### Data Splits
The dataset contains 14k QA pairs over 1.7K paragraphs, split between train (10k QAs), development (1.6k QAs) and a hidden test partition (1.7k QAs).
## Dataset Creation
### Curation Rationale
From the original paper:
*ROPES challenges reading comprehension models to handle more difficult phenomena: understanding the implications of a passage of text. ROPES is also particularly related to datasets focusing on "multi-hop reasoning", as by construction answering questions in ROPES requires connecting information from multiple parts of a given passage.*
*We constructed ROPES by first collecting background passages from science textbooks and Wikipedia articles that describe causal relationships. We showed the collected paragraphs to crowd workers and asked them to write situations that involve the relationships found in the background passage, and questions that connect the situation and the background using the causal relationships. The answers are spans from either the situation or the question. The dataset consists of 14,322 questions from various domains, mostly in science and economics.*
### Source Data
From the original paper:
*We automatically scraped passages from science textbooks and Wikipedia that contained causal connectives eg. ”causes,” ”leads to,” and keywords that signal qualitative relations, e.g. ”increases,” ”decreases.”. We then manually filtered out the passages that do not have at least one relation. The passages can be categorized into physical science (49%), life science (45%), economics (5%) and other (1%). In total, we collected over 1,000 background passages.*
#### Initial Data Collection and Normalization
From the original paper:
*We used Amazon Mechanical Turk (AMT) to generate the situations, questions, and answers. The AMT workers were given background passages and asked to write situations that involved the relation(s) in the background passage. The AMT workers then authored questions about the situation that required both the background and the situation to answer. In each human intelligence task (HIT), AMT workers are given 5 background passages to select from and are asked to create a total of 10 questions. To mitigate the potential for easy lexical shortcuts in the dataset, the workers were encouraged via instructions to write questions in minimal pairs, where a very small change in the question results in a different answer.*
*Most questions are designed to have two sensible answer choices (eg. “more” vs. “less”).*
To reduce annotator bias, training and evaluation sets are writter by different annotators.
#### Who are the source language producers?
[More Information Needed]
### Annotations
[More Information Needed]
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
The data is distributed under the [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) license.
### Citation Information
```
@inproceedings{Lin2019ReasoningOP,
title={Reasoning Over Paragraph Effects in Situations},
author={Kevin Lin and Oyvind Tafjord and Peter Clark and Matt Gardner},
booktitle={MRQA@EMNLP},
year={2019}
}
```
### Contributions
Thanks to [@VictorSanh](https://github.com/VictorSanh) for adding this dataset.
annotations_creators:
- 众包(crowdsourced)
language_creators:
- 众包(crowdsourced)
- 现有资源获取(found)
language:
- 英语(en)
license:
- CC BY 4.0
multilinguality:
- 单语言(monolingual)
size_categories:
- 10K<n<100K
source_datasets:
- 扩展维基百科(extended|wikipedia)
- 原创(original)
task_categories:
- 问答(Question Answering, QA)
task_ids:
- 抽取式问答(extractive QA)
paperswithcode_id: ropes
pretty_name: ROPES
dataset_info:
config_name: 纯文本(plain_text)
features:
- name: id
dtype: 字符串(string)
- name: background
dtype: 字符串(string)
- name: situation
dtype: 字符串(string)
- name: question
dtype: 字符串(string)
- name: answers
sequence:
- name: text
dtype: 字符串(string)
splits:
- name: train
num_bytes: 12231892
num_examples: 10924
- name: test
num_bytes: 1928508
num_examples: 1710
- name: validation
num_bytes: 1643474
num_examples: 1688
download_size: 1372548
dataset_size: 15803874
configs:
- config_name: 纯文本(plain_text)
data_files:
- split: train
path: 纯文本/train-*
- split: test
path: 纯文本/test-*
- split: validation
path: 纯文本/validation-*
default: true
# ROPES数据集卡片
## 目录
- [数据集说明](#数据集说明)
- [数据集概述](#数据集概述)
- [支持任务与评测榜单](#支持任务与评测榜单)
- [语言说明](#语言说明)
- [数据集结构](#数据集结构)
- [数据样例](#数据样例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [构建初衷](#构建初衷)
- [源数据](#源数据)
- [注释](#注释)
- [个人与敏感信息](#个人与敏感信息)
- [数据集使用注意事项](#数据集使用注意事项)
- [数据集的社会影响](#数据集的社会影响)
- [偏差分析](#偏差分析)
- [已知其他限制](#已知其他限制)
- [附加信息](#附加信息)
- [数据集维护者](#数据集维护者)
- [授权信息](#授权信息)
- [引用信息](#引用信息)
- [贡献致谢](#贡献致谢)
## 数据集说明
- **主页:** [ROPES数据集](https://allenai.org/data/ropes)
- **论文:** [Reasoning Over Paragraph Effects in Situations](https://arxiv.org/abs/1908.05852)
- **评测榜单:** [ROPES评测榜单](https://leaderboard.allenai.org/ropes)
### 数据集概述
ROPES(Reasoning Over Paragraph Effects in Situations,场景下段落推理效果问答数据集)是一个问答(QA)数据集,用于测试系统将文本段落中的知识应用于新场景的能力。该数据集向系统提供包含因果或定性关系的背景段落(例如“动物授粉者可提升花卉的授粉效率”)、基于该背景构建的新颖场景,以及需要结合背景段落中的关系与场景上下文进行推理的问题。
### 支持任务与评测榜单
该阅读理解任务被框架化为抽取式问答(extractive QA)问题。模型的评测遵循近期阅读理解数据集(如SQuAD)的通用实践,通过计算词级F1值与精确匹配(Exact Match, EM)指标进行评估。
### 语言说明
数据集文本语言为英语,对应的BCP-47代码为`en`。
## 数据集结构
### 数据样例
数据格式与SQuAD v1.1高度相似,样例如下:
{
"id": "2058517998",
"background": "癌症是一种导致细胞不受控分裂的疾病。正常情况下,人体存在抑制细胞不受控分裂的机制,但在癌症病例中,这些机制失效。癌症通常由基因突变引发,基因突变是基因内的随机错误,致癌突变多发生于调控细胞周期的基因中。由于基因突变,异常细胞不受控地分裂,这通常会导致肿瘤的形成。肿瘤是一团异常组织,随着肿瘤生长,可能会损害周围的正常组织。任何可致癌的物质都被称为致癌物,致癌物可能是病原体、化学物质或辐射。",
"situation": "杰森近期被确诊患有癌症。得知消息后,他说服妻子夏洛特进行体检。经过多项检查,医生确认夏洛特未患癌症,但患有高血压。杰森松了一口气,随后专注于对抗癌症,尽全力争取生存。",
"question": "谁的细胞分裂速度更快?",
"answers": {
"text": ["杰森"]
}
}
### 数据字段
- `id`: 数据标识符
- `background`: 背景段落文本
- `situation`: 锚定场景文本
- `question`: 待解答问题
- `answers`: 答案文本,为来自场景或问题的片段,答案列表始终仅包含单个元素。
注意测试集的答案被隐藏(表现为空列表),测试集的预测结果需提交至评测榜单。
### 数据划分
该数据集包含14322个问答对,覆盖1700余个段落,划分为训练集(10924个问答对)、验证集(1688个问答对)与隐藏测试集(1710个问答对)。
## 数据集构建
### 构建初衷
来自原论文:
> ROPES旨在挑战阅读理解模型处理更复杂的文本理解现象:理解文本段落的隐含意义。ROPES同时与聚焦于“多跳推理”的数据集高度相关,因为从数据集构建逻辑来看,回答ROPES中的问题需要将给定段落中多个部分的信息关联起来。
>
> 我们构建ROPES的流程为:首先从科学教科书与维基百科文章中收集描述因果关系的背景段落,将收集到的段落展示给众包工作者,要求他们编写涉及背景段落中所述关系的新颖场景,以及需要结合场景与背景段落中的因果关系进行解答的问题。答案均为来自场景或问题的文本片段。该数据集包含来自多个领域的14322个问题,其中多数来自科学与经济学领域。
### 源数据
来自原论文:
> 我们自动从科学教科书与维基百科中爬取包含因果连接词(如“导致”“引发”)与表征定性关系的关键词(如“提升”“降低”)的段落,随后手动过滤掉不包含至少一种关系的段落。这些段落可分为物理科学(49%)、生命科学(45%)、经济学(5%)与其他领域(1%),总计收集到超过1000个背景段落。
#### 初始数据收集与规范化
来自原论文:
> 我们使用亚马逊机械 Turk(Amazon Mechanical Turk, AMT)生成场景、问题与答案。向AMT工作者提供背景段落,要求他们编写涉及背景段落中所述关系的场景,随后创作需要结合背景与场景信息才能解答的关于该场景的问题。在每个人工智能任务(Human Intelligence Task, HIT)中,AMT工作者可从5个背景段落中选择,并被要求创作总计10个问题。为了降低数据集中出现简单词汇捷径的可能性,我们通过指令鼓励工作者以最小对组(minimal pairs)的形式编写问题,即仅对问题进行极小改动即可得到不同的答案。
>
> 多数问题被设计为拥有两个合理的可选答案(例如“更多”与“更少”)。
为了降低标注者偏差,训练集与评测集由不同的标注者编写。
#### 源语言生成者信息
[需获取更多信息]
### 注释
[需获取更多信息]
#### 注释流程
[需获取更多信息]
#### 标注者信息
[需获取更多信息]
### 个人与敏感信息
[需获取更多信息]
## 数据集使用注意事项
### 数据集的社会影响
[需获取更多信息]
### 偏差分析
[需获取更多信息]
### 已知其他限制
[需获取更多信息]
## 附加信息
### 数据集维护者
[需获取更多信息]
### 授权信息
数据集采用[CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)协议进行分发。
### 引用信息
@inproceedings{Lin2019ReasoningOP,
title={Reasoning Over Paragraph Effects in Situations},
author={Kevin Lin and Oyvind Tafjord and Peter Clark and Matt Gardner},
booktitle={MRQA@EMNLP},
year={2019}
}
### 贡献致谢
感谢[@VictorSanh](https://github.com/VictorSanh)添加该数据集。
提供机构:
allenai
原始信息汇总
数据集概述
数据集名称
- 名称: ROPES
- 别名: Reasoning Over Paragraph Effects in Situations
数据集描述
- 语言: 英语 (
en) - 许可证: CC BY 4.0
- 多语言性: 单语种
- 大小: 10K<n<100K
- 源数据: 扩展自Wikipedia,原始数据
- 任务类别: 问答 (extractive-qa)
- 数据集ID: ropes
数据集结构
- 数据实例: 遵循SQuAD v1.1格式,包含ID、背景、情境、问题和答案。
- 数据字段:
id: 识别码background: 背景段落situation: 情境描述question: 问题answers: 答案文本,通常为情境或问题的片段
数据集创建
- 数据收集: 自动从科学教科书和Wikipedia收集包含因果关系的段落。
- 注释过程: 通过Amazon Mechanical Turk进行,注释者根据背景段落创建情境和问题。
数据集使用注意事项
- 许可证: 使用数据集需遵守CC BY 4.0许可。
- 引用信息: 引用时需使用提供的引用格式。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,阅读理解任务常需模型理解文本深层含义。ROPES数据集的构建始于从科学教科书与维基百科中自动抓取蕴含因果或定性关系的段落,随后进行人工筛选以确保段落包含至少一种关系。通过亚马逊众包平台,标注者基于选定背景段落创作新颖情境并提出问题,这些问题需结合背景知识与情境信息进行推理。为减少标注偏差,训练集与评估集由不同标注者完成,且鼓励设计最小配对问题以规避词汇捷径,最终形成涵盖物理科学、生命科学及经济学等多领域的优质语料。
特点
ROPES数据集的核心特点在于其强调因果与定性关系的推理能力评估。每个数据实例包含背景段落、新颖情境及对应问题,要求模型跨越文本表层信息,融合背景知识于具体情境中进行逻辑推断。答案均以文本片段形式呈现,源自情境或问题本身,增强了任务的挑战性。数据集规模适中,包含逾1.4万个问答对,覆盖多样科学主题,其结构遵循SQuAD格式,便于现有模型适配与评估,同时通过隐藏测试集答案支持公开排行榜竞争,推动模型在复杂推理任务上的进步。
使用方法
使用ROPES数据集时,研究者可将其应用于抽取式问答任务的训练与评估。数据集已划分为训练、验证与测试子集,用户可直接加载相应配置进行模型训练。在预处理阶段,需将背景、情境及问题文本输入模型,要求模型预测答案片段,并通过精确匹配与词级F1分数衡量性能。对于测试集,答案不予公开,需提交预测结果至官方排行榜以获取评估。该数据集兼容主流深度学习框架,支持端到端训练,有助于开发能够处理多步推理与知识应用的先进阅读理解系统。
背景与挑战
背景概述
在自然语言处理领域,阅读理解任务长期致力于提升模型对文本深层含义的解析能力。ROPES数据集由艾伦人工智能研究所于2019年推出,其核心研究聚焦于情境推理,旨在评估模型如何将背景段落中的因果或定性关系应用于新颖情境。该数据集通过众包方式构建,背景材料源自科学教科书与维基百科,涵盖了物理科学、生命科学及经济学等多领域知识。ROPES的创立推动了推理型问答系统的发展,为复杂逻辑推理研究提供了重要基准,显著增强了模型在现实场景中的知识迁移与因果推断能力。
当前挑战
ROPES数据集所针对的领域挑战在于解决阅读理解中的多跳推理问题,要求模型跨越背景知识与具体情境之间的语义鸿沟,精准识别因果关联并推导隐含效应。构建过程中的挑战主要包括:首先,从海量科学文本中筛选蕴含明确因果关系的段落需依赖精细的关键词与连接词标注,并辅以人工过滤以确保数据质量;其次,通过众包平台生成情境与问题时,需设计严谨的指令以引导工作者创作具有最小对立对的问答对,从而避免模型通过词汇捷径获取答案,同时还需协调不同标注者以减少偏差,确保训练集与评估集之间的独立性。
常用场景
经典使用场景
在自然语言处理领域,阅读理解任务常面临模型难以进行深度推理的挑战。ROPES数据集通过提供背景段落与情境描述,构建了需要因果推理的问答场景,其经典使用场景在于评估模型能否将背景知识应用于新情境中。该数据集要求模型不仅理解文本表面信息,还需识别因果关系并推断其在特定情境下的效应,从而推动阅读理解系统向更复杂的推理能力迈进。
衍生相关工作
自ROPES数据集发布以来,已衍生出多项经典研究工作。例如,基于Transformer的模型如BERT与RoBERTa通过在该数据集上的微调,探索了多跳推理与因果推断的改进方法。同时,研究者们开发了如链式思维提示等新技术,以增强模型在ROPES任务上的表现。这些工作不仅推动了阅读理解模型的演进,也为后续数据集如DROP与HotpotQA的构建提供了灵感与参考。
数据集最近研究
最新研究方向
在自然语言处理领域,阅读理解任务正逐步从表层信息提取转向深层因果推理。ROPES数据集以其独特的背景段落与情境结合设计,为模型理解文本中的因果关系提供了重要基准。近年来,研究焦点集中于提升模型在复杂多跳推理中的表现,尤其是在科学和经济文本中应用因果知识解决新情境问题的能力。随着大语言模型的兴起,ROPES被广泛用于评估模型在零样本或少样本设置下的推理泛化性能,相关研究也探讨了如何通过增强模型对隐含关系的捕捉来减少对词汇线索的依赖。这些进展不仅推动了可解释人工智能的发展,也为教育技术和自动问答系统的优化提供了理论支撑。
以上内容由遇见数据集搜集并总结生成


