Spider
收藏arXiv2019-02-03 更新2024-06-21 收录
下载链接:
https://yale-lily.github.io/spider
下载链接
链接失效反馈官方服务:
资源简介:
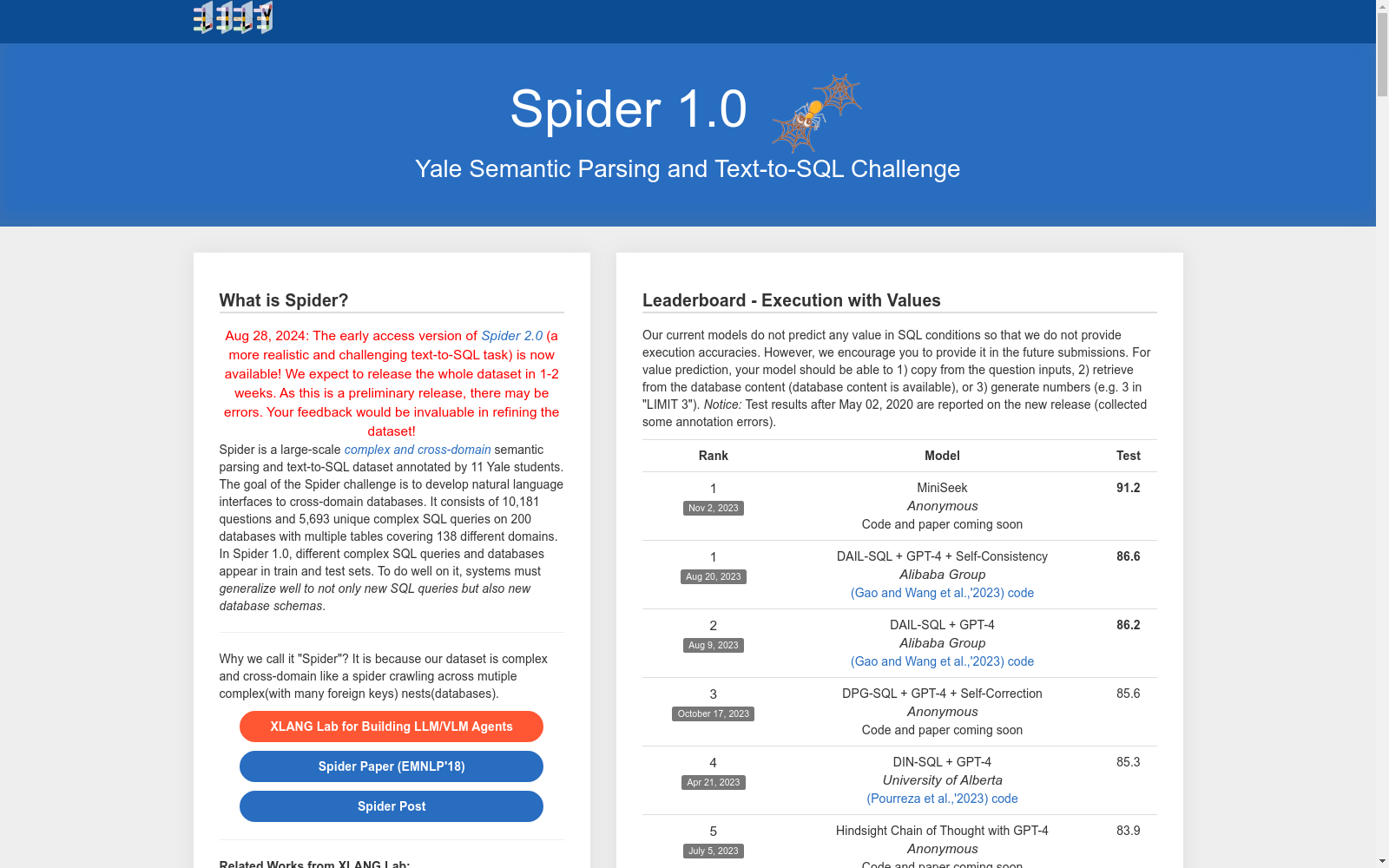
Spider是由耶鲁大学计算机科学系创建的大规模、复杂且跨领域的语义解析和文本到SQL的数据集。该数据集包含10,181个问题和5,693个独特的复杂SQL查询,涉及200个数据库,覆盖138个不同领域。数据集由11名大学生耗时1,000小时标注完成。Spider数据集旨在解决模型在面对新SQL查询和新数据库模式时的泛化能力问题,特别强调了模型需要理解自然语言问题以及数据库模式中表和列之间的关系。该数据集的应用领域广泛,主要用于测试和提升模型在复杂查询和跨领域数据库处理上的性能。
Spider is a large-scale, complex, cross-domain semantic parsing and text-to-SQL dataset created by the Department of Computer Science at Yale University. This dataset contains 10,181 questions and 5,693 unique complex SQL queries, covering 200 databases and spanning 138 distinct domains. It was annotated by 11 undergraduate students over 1,000 working hours. The Spider dataset aims to address the generalization capability challenges of models when encountering novel SQL queries and new database schemas, with particular emphasis on requiring models to comprehend natural language questions as well as the relationships between tables and columns within database schemas. This dataset has a wide range of applications, primarily used for testing and improving the performance of models in complex query processing and cross-domain database tasks.
提供机构:
耶鲁大学计算机科学系
创建时间:
2018-09-24
搜集汇总
数据集介绍
构建方式
Spider数据集的构建基于自然语言处理与数据库查询的交叉领域,通过精心设计的流程,从多个真实世界的数据库中提取结构化信息,并生成与之对应的自然语言问题。这一过程涉及数据清洗、问题生成和查询验证等多个步骤,确保了数据集的高质量和实用性。
特点
Spider数据集以其复杂性和多样性著称,涵盖了多种数据库结构和查询类型,包括嵌套查询和多表连接等高级操作。此外,该数据集还特别注重于跨领域的应用,提供了丰富的上下文信息,使得模型能够更好地理解和执行复杂的查询任务。
使用方法
Spider数据集主要用于评估和提升自然语言到SQL查询的转换能力。研究者和开发者可以通过该数据集训练和测试模型,以提高其在实际应用中的表现。使用时,用户需先加载数据集,然后根据具体需求选择合适的模型进行训练或评估,最终通过对比模型的输出与标准答案来衡量其性能。
背景与挑战
背景概述
在自然语言处理领域,特别是语义解析任务中,Spider数据集的引入标志着对复杂数据库查询理解的重要进展。该数据集由Yu et al. 在2018年提出,旨在解决现有数据集在处理复杂SQL查询时的局限性。Spider数据集包含了10,181个自然语言问句及其对应的SQL查询,涵盖了200个不同的数据库模式。这一数据集的发布,极大地推动了语义解析技术的发展,特别是在处理多表查询和嵌套查询方面,为研究人员提供了一个更为真实和复杂的测试平台。
当前挑战
Spider数据集的构建过程中面临了诸多挑战。首先,数据集需要涵盖多种数据库模式和复杂的SQL查询,这要求在数据收集和标注过程中具备高度的专业性和准确性。其次,自然语言问句与SQL查询之间的映射关系复杂,涉及多表连接、嵌套查询等高级SQL操作,这增加了语义解析模型的训练难度。此外,数据集的多样性和复杂性也使得模型的泛化能力成为一个重要挑战,如何在不同数据库模式和查询类型之间实现有效的迁移学习,是当前研究的一个关键问题。
发展历史
创建时间与更新
Spider数据集由Yu等人于2018年创建,旨在推动自然语言处理领域中的语义解析研究。该数据集自创建以来,经历了多次更新,以适应不断发展的技术需求和研究方向。
重要里程碑
Spider数据集的首次发布标志着复杂数据库查询任务在自然语言处理中的重要突破。其包含的10,181个问题和5,693个SQL查询,涵盖了200个不同的数据库,极大地丰富了语义解析任务的多样性和复杂性。此外,Spider还引入了跨域和多表查询的挑战,推动了相关研究的发展。随着时间的推移,Spider数据集不断更新,增加了更多的数据库和查询类型,进一步提升了其在学术界和工业界的影响力。
当前发展情况
当前,Spider数据集已成为自然语言处理领域中语义解析任务的标准基准之一。其广泛应用于各种研究论文和实验中,推动了语义解析技术的进步。Spider的成功不仅在于其丰富的数据量和多样性,还在于其对复杂查询任务的覆盖,这为研究人员提供了宝贵的资源。随着深度学习和预训练模型的兴起,Spider数据集也在不断适应新的技术趋势,通过引入更多复杂的查询和数据库,继续推动语义解析领域的前沿研究。
发展历程
- Spider数据集首次发表,由Yu等人提出,旨在评估自然语言到SQL查询的转换能力。
- Spider数据集首次应用于自然语言处理领域的研究,特别是在语义解析和数据库查询生成任务中。
- Spider数据集的扩展版本发布,增加了更多的数据库和查询类型,以提升数据集的多样性和挑战性。
- Spider数据集在多个国际会议和竞赛中被广泛使用,成为评估自然语言到SQL转换模型性能的标准数据集之一。
常用场景
经典使用场景
在自然语言处理领域,Spider数据集以其独特的结构化查询语言(SQL)生成任务而闻名。该数据集包含了复杂的SQL查询,涵盖了多种数据库模式和复杂的查询结构,为研究人员提供了一个评估和提升自然语言到SQL转换模型性能的理想平台。通过使用Spider数据集,研究者们能够开发和测试各种模型,以实现更准确和高效的语义解析,从而推动了该领域的技术进步。
衍生相关工作
Spider数据集的发布激发了大量相关研究工作,推动了自然语言处理和数据库领域的交叉研究。例如,基于Spider数据集,研究者们开发了多种改进的语义解析模型,如BERT-SQL和T5-SQL,这些模型在处理复杂查询时表现出色。此外,Spider数据集还促进了跨领域研究,如结合知识图谱和数据库查询的集成研究,进一步扩展了其应用范围和影响力。
数据集最近研究
最新研究方向
在自然语言处理领域,Spider数据集作为复杂文本到SQL查询任务的代表,近期研究聚焦于提升模型的跨领域适应性和查询准确性。研究者们通过引入多任务学习框架,结合预训练语言模型,旨在增强模型对不同数据库模式的理解能力。此外,针对数据集中的长尾问题,研究者们探索了基于生成对抗网络(GAN)的增强方法,以提高模型在稀有查询类型上的表现。这些前沿研究不仅推动了文本到SQL任务的技术进步,也为实际应用中的数据库交互提供了更为可靠的解决方案。
相关研究论文
- 1Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL TaskUniversity of Washington, AI2, Google Research, McGill University · 2018年
- 2RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL ParsersUniversity of Washington, AI2 · 2019年
- 3Global Reasoning over Database Structures for Text-to-SQL ParsingUniversity of Washington, AI2 · 2020年
- 4Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate RepresentationUniversity of Washington, AI2 · 2019年
- 5Improving Text-to-SQL Evaluation MethodologyUniversity of Washington, AI2 · 2018年
以上内容由遇见数据集搜集并总结生成


