UniBiomed
收藏arXiv2025-04-30 更新2025-05-13 收录
下载链接:
http://arxiv.org/abs/2504.21336v1
下载链接
链接失效反馈官方服务:
资源简介:
UniBiomed是一个通用的基础模型,用于基于图像的医学图像解释。该模型基于多模态大型语言模型(MLLM)和分割任意模型(SAM)的创新整合,能够有效地统一临床文本生成和对相应生物医学对象的分割,从而实现基于图像的解释。为了开发UniBiomed,研究人员构建了一个大规模数据集,包含超过2700万个图像、注释和文本描述的三元组,涵盖10种成像模式。该数据集是目前为止最大的、最全面的生物医学图像解释数据集。
提供机构:
香港科技大学计算机科学与工程系, 化学与生物工程系, 生命科学系, 分子神经科学国家重点实验室, 深圳香港协同创新研究院
创建时间:
2025-04-30
搜集汇总
数据集介绍
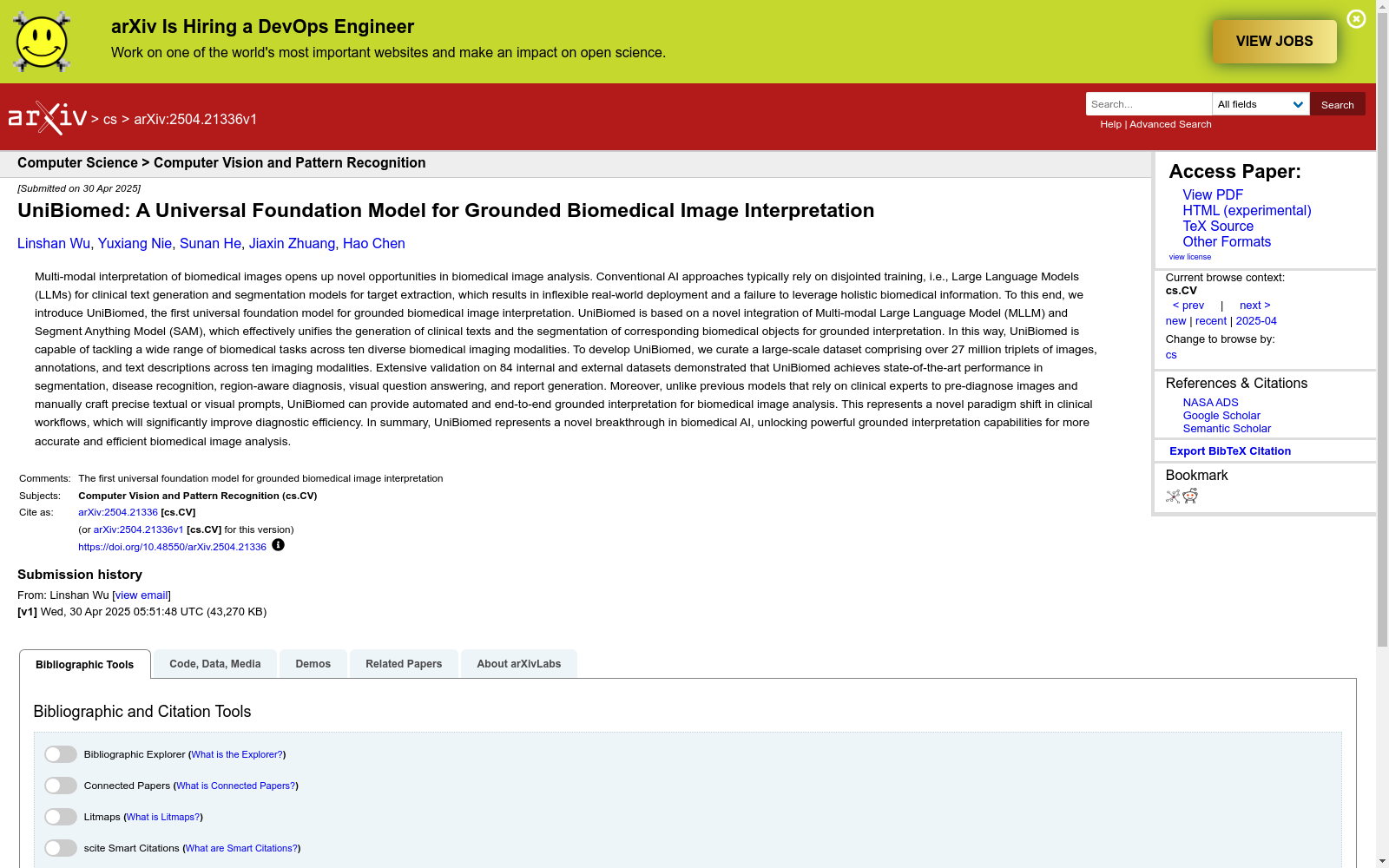
构建方式
UniBiomed数据集的构建基于多模态生物医学图像分析的前沿需求,通过整合来自84个公开数据集的27百万个图像-文本-标注三元组,覆盖10种生物医学成像模态。构建过程中,研究者精心筛选了包含分割掩膜和边界框的空间定位信息,并从临床文本中提取语义标签、诊断结论和医学知识。关键创新在于将文本描述统一转化为视觉问答(VQA)格式,例如将CT图像中的肝脏肿瘤描述结构化为“请识别此CT图像中的异常区域并返回分割掩膜”的问答对,从而实现异常识别与目标分割的联合建模。三维医学图像(如CT和MRI)被预处理为二维切片以适配模型输入,最终形成目前生物医学领域规模最大、模态覆盖最全面的基础数据集。
特点
该数据集的核心特点体现在其多模态协同与任务普适性:1)跨模态覆盖性,涵盖CT、MRI、病理切片等10种成像技术,支持从器官到细胞的多尺度分析;2)标注细粒度,每个样本包含像素级分割掩膜、边界框及专业临床文本描述,实现视觉-语言信息的精准对齐;3)任务兼容性,通过统一VQA格式支持分割、疾病识别、区域感知诊断等五大类任务;4)临床实用性,文本描述源自真实临床报告,包含医学术语、解剖学特征和病理学观察,可直接服务于医疗决策支持系统。相较于同类数据集BiomedParse,其规模扩大30倍且首次实现分割与文本生成的端到端联合标注。
使用方法
使用该数据集需遵循多任务协同范式:1)模型训练时,采用文本生成损失(Ltext)与分割损失(Lseg)的联合优化目标,其中分割损失结合像素级交叉熵和Dice损失;2)对于区域分类等无需分割的任务,可屏蔽[SEG]标记并单独优化文本生成;3)推理阶段支持灵活提示机制,用户可通过自然语言指令(如“请描述胰腺病理图像中的肿瘤区域”)触发模型同步生成诊断文本与分割结果。数据集已按8:2比例划分训练测试集,外部验证集完全独立以评估泛化性。研究者推荐使用InternVL2.5作为多模态大语言模型基座,配合SAM2的分割架构,在8×H800 GPU上完成10轮训练约需5天。
背景与挑战
背景概述
UniBiomed是由香港科技大学的研究团队于2025年推出的首个面向生物医学图像解释的通用基础模型。该模型创新性地整合了多模态大语言模型(MLLM)和Segment Anything Model(SAM),旨在解决生物医学图像分析中视觉与文本信息割裂的核心问题。研究团队构建了包含10种成像模态、2700万图像-文本-标注三元组的大规模数据集,为模型训练提供了跨器官、病变和细胞级别的多粒度信息。这一突破性工作显著提升了疾病识别、区域感知诊断等任务的性能,在84个内外验证数据集上平均Dice分数超越前最佳模型10.25%,标志着生物医学AI从单一任务向端到端解释的重要范式转变。
当前挑战
UniBiomed面临的挑战主要体现在两个方面:领域问题层面,需解决生物医学图像解释中视觉目标分割与文本描述生成的同步难题,传统方法如MedSAM仅支持视觉提示分割,而LLaVA-Med等模型缺乏空间定位能力;构建过程层面,数据标注需同时满足空间定位(分割掩码/边界框)和专家级文本描述的双重要求,研究团队通过统一视觉问答格式处理了10种模态的异构数据,并应对了3D医学图像切片处理、小病变标注精度控制等技术难点。模型还需克服多模态特征对齐、分割与生成任务损失平衡等架构设计挑战。
常用场景
经典使用场景
UniBiomed数据集在生物医学图像分析领域展现出卓越的多模态处理能力,其最经典的使用场景在于实现生物医学图像的端到端解释。通过整合多模态大型语言模型(MLLM)与Segment Anything Model(SAM),该数据集能够同时生成临床文本描述并分割对应的生物医学目标。这种能力使其在CT、MRI、X光等10种成像模态中广泛应用,特别适用于需要精确空间定位与语义解释相结合的复杂任务,如微小病灶的识别与描述。
解决学术问题
该数据集有效解决了生物医学AI领域长期存在的模态割裂问题。传统方法需分别训练文本生成模型与分割模型,导致信息利用不完整且临床部署灵活性不足。UniBiomed通过27百万图像-标注-文本三元组的大规模数据,统一了分割掩码生成与临床文本描述的联合训练范式,在84个内外数据集验证中,分割Dice分数平均提升10.25%,疾病识别准确率提高8.32%,为区域感知诊断、视觉问答等任务建立了新基准。
衍生相关工作
该数据集催生了多个生物医学基础模型的创新研究。基于其统一框架,衍生出MedRegA的区域感知诊断模型、LISA的推理分割方法等经典工作。在RadGenome数据集上的基准测试中,以53.8%的Dice分数和51.6%的ROUGE-L分数刷新性能记录,推动GLaMM等模型在像素级 grounding 任务上的改进。其构建的视觉指令调优格式已成为多模态生物医学分析的新标准。
以上内容由遇见数据集搜集并总结生成


