Mattysmittttt/qld-traffic-crashes-clean
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Mattysmittttt/qld-traffic-crashes-clean
下载链接
链接失效反馈官方服务:
资源简介:
这是一个经过清洗、适合机器学习使用的昆士兰州道路交通事故数据集,包含2011年至2024年期间每起报告事故的一行数据,具有33个事故前/事故中的特征和一个4类严重程度的目标变量。适用于训练严重程度和二元致命性分类器、道路安全描述性分析以及教授表格机器学习。数据集经过了清洗和处理,包括删除重复项、处理缺失值、转换数据类型等。数据集还提供了时间分割(训练集、验证集和测试集),并详细描述了每个特征的角色和用途。
Cleaned, ML-ready Queensland road-crash data — one row per reported crash, 2011–2024, with 33 pre-/at-crash features and a 4-class severity target. Suitable for training severity and binary-fatal classifiers, road-safety descriptive analysis, and teaching tabular ML on public-good data.
提供机构:
Mattysmittttt
搜集汇总
数据集介绍
构建方式
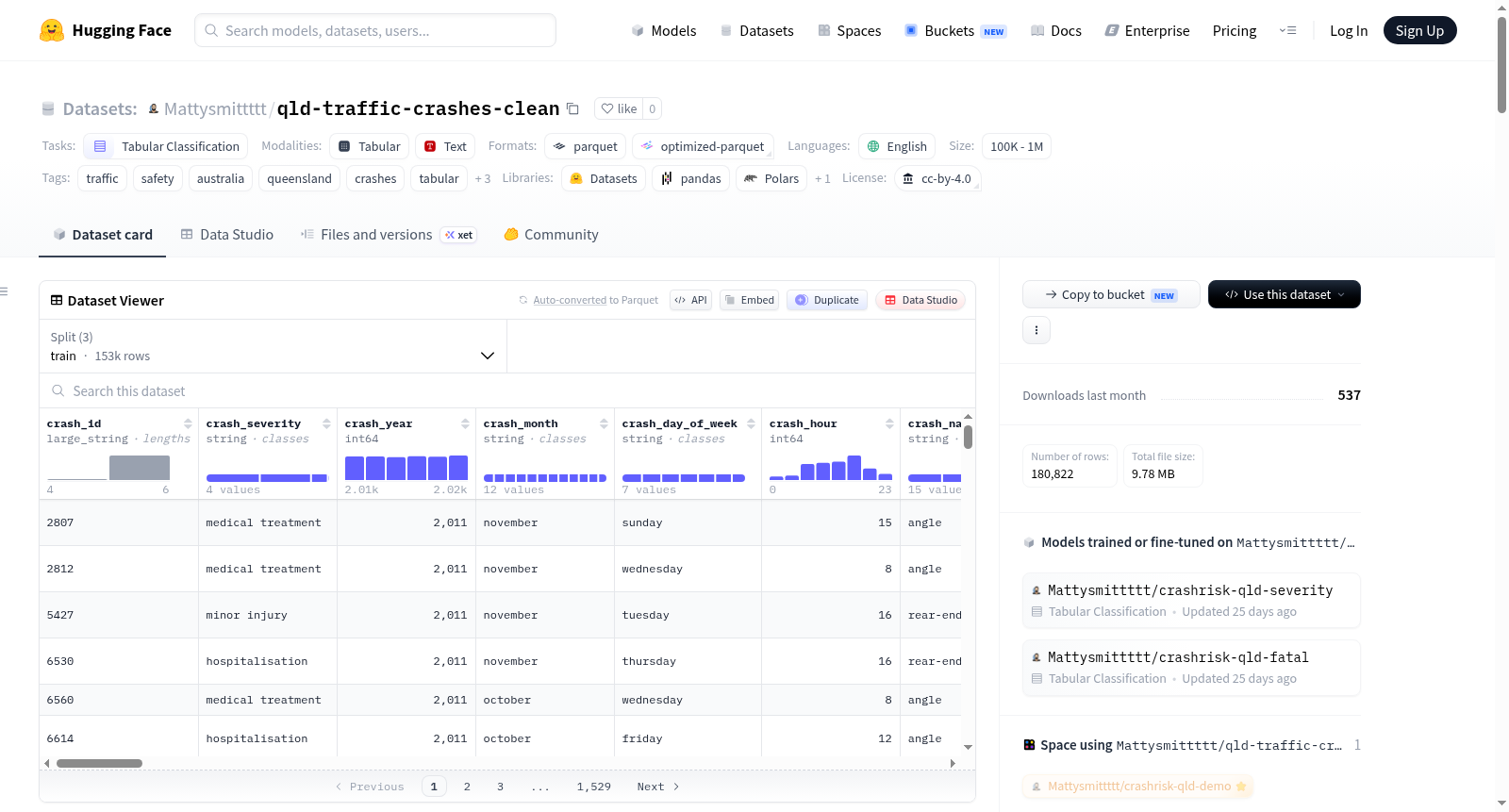
在昆士兰州道路交通碰撞数据治理实践中,本数据集源自该州交通与主干道管理局发布的官方事故记录,原始版本涵盖2011至2024年间逾四十万条报告。经过系统性清洗流程,剔除了仅涉及财产损失的事故记录、坐标缺失或超出行或范围的条目,以及存在空白或未编码分类信息的行,最终保留了约十八万条高质量样本。针对文本形式的分类变量,实施了统一小写化与空值标准化的处理策略;对速度限制等有序字段,则由字符串转换为具体的千米每小时数值。同时,从原始星期字段中派生出了是否为周末的二元特征,为后续建模提供了更丰富的输入维度。
特点
本数据集最显著的特质在于其时序感知的划分策略,为确保评估的可靠性,将最完整的最近年度作为测试集,按年份而非随机方式切分为训练(2011至2022年)、验证(2023年)与测试(2024年)三部分。每个事故实例包含33个事前或事故时的描述特征,并设置了四级严重程度作为预测目标。致命事故仅占约1.85%,呈现出极具挑战性的类别不平衡特性。数据集中明确标注了可能造成信息泄露的列,并在训练时予以排除,保障了模型评价的客观性。此外,丰富的地理空间特征与多种交通参与类型计数,使得该数据适用于多任务的机器学习探索。
使用方法
借助Hugging Face的datasets库,用户可通过一行代码快速加载已划分好的训练、验证与测试子集,并方便地转换为Pandas DataFrame进行深入分析。推荐采用LightGBM等梯度提升模型处理表格数据,针对不平衡的致命事故预测应优先使用宏平均F1分数或精确率-召回率曲线下面积作为评价指标。数据集已预置了可直接使用的分类器模型及交互式演示空间,便于快速原型验证。值得留意的是,由于时间跨度覆盖十余年,记录实践与基础设施均存在演变,对2025年及之后的预测需谨慎解读,且上报偏差可能导致轻伤案例在偏远地区被低估。
背景与挑战
背景概述
该数据集由研究者Mattysmittttt于2026年创建,源自昆士兰州交通与主干道路部发布的‘Crash data from Queensland roads’官方数据(版本rqC45037),旨在为道路安全分析提供经过清洗与特征工程处理的机器学习就绪数据。核心研究问题聚焦于利用33项碰撞前/碰撞时特征,对交通事故严重程度进行多分类预测(致命、住院、医疗处理、轻伤),并辅以致命性二元分类任务。数据集覆盖2011年至2024年间的昆士兰州道路碰撞记录,总计超过18万条样本,其时间跨度和地域覆盖为澳大利亚乃至全球的道路交通安全研究提供了宝贵的实证基础。该数据集通过开源许可(CC-BY 4.0)发布,并配套了预训练模型与交互式演示,显著降低了相关领域研究者进行可复现性研究的门槛,推动了公共数据在机器学习与公共安全交叉领域的应用。
当前挑战
该数据集所解决的领域问题核心在于交通事故严重程度预测的挑战:致命碰撞仅占约1.85%的样本,呈现出典型的类别严重不平衡现象,导致传统准确率指标产生误导,需依赖宏平均F1分数或精确率-召回率曲线下面积进行评估。此外,数据存在时间漂移问题——2011至2024年间车辆安全标准、道路基础设施及事故记录方式均发生显著变化,使得对2025年及之后的预测需保持审慎态度。构建过程中面临的挑战包括:原始数据存在约21%的缺失或无效记录(如财产损失类事故在2010年后停止记录、坐标缺失或超出昆士兰边界),需进行系统性清洗;地理位置精确度参差不齐,部分条目仅具备郊区级别定位;同时,严重程度标签与上游伤亡汇总数据在术语上存在不一致,需谨慎避免表连接时的语义错配。
常用场景
经典使用场景
在道路安全研究领域,QLD Traffic Crashes (Cleaned) 数据集为交通事故严重性分级预测提供了标准化的基准。该数据集涵盖2011年至2024年间昆士兰州超过18万起报告事故,每条记录包含33个事故前/发生时特征,并以四级伤害严重度(致命、住院、医疗处理、轻伤)作为多分类目标,同时支持二分类致命性预测。研究者可基于此数据构建梯度提升树、随机森林或深度神经网络模型,通过时间序列划分的训练-验证-测试集(2011-2022训练、2023验证、2024测试)评估模型泛化能力,避免时间泄漏风险。该数据集因其干净的预处理流程、明确的特征-标签关系以及考虑时间漂移的划分策略,已成为澳大利亚道路安全机器学习研究的典型素材。
衍生相关工作
围绕该数据集已衍生出若干标志性成果。Hugging Face 社区直接发布了配套的严重性分类器 crashrisk-qld-severity 和致命性二分类器 crashrisk-qld-fatal,两者均使用 LightGBM 作为骨干模型,并提供了 Gradio 交互演示空间,极大降低了学术复现与教育门槛。在方法创新方面,有研究者基于该数据的时间分区特性,提出时序自适应集成策略以应对年度标签漂移;另有一些工作聚焦于空间特征编码(如局域统计区、警区层次化映射)与地理位置嵌入的融合,探讨细粒度地理信息对预测精度的提升效果。该数据集还常作为表格数据教学案例,被用于数据清洗、特征工程、类别不平衡处理等课程实践,推动了公共数据科学素养的普及。
数据集最近研究
最新研究方向
该数据集聚焦于澳大利亚昆士兰州2011至2024年间的道路交通事故记录,经过精细清洗后可用于多类别严重程度预测与致命性二分类任务。当前前沿研究方向包括利用时序分割策略(以最近完整年份为测试集)解决传统随机划分带来的信息泄露问题,并融合地理、道路环境、交通控制等多维特征构建轻量级梯度提升模型(LightGBM)以应对约1.85%的极端类别不平衡。这一工作不仅为昆士兰交通安全政策制定提供了可复现的AI评估工具,更与全球范围内利用公开政府数据推动道路安全智能监控的热潮相呼应,其影响在于建立了一个兼顾时空一致性与模型鲁棒性的基准,为同类事故数据集的处理与建模树立了典范。
以上内容由遇见数据集搜集并总结生成


