Elliquiy-Role-Playing-Forums_2023-04
收藏Hugging Face2025-01-02 更新2025-01-03 收录
下载链接:
https://huggingface.co/datasets/lemonilia/Elliquiy-Role-Playing-Forums_2023-04
下载链接
链接失效反馈官方服务:
资源简介:
Elliquiy角色扮演论坛数据集包含从2005年4月到2023年4月的660万篇帖子和11.2万个论坛线程,数据量约为9GB。数据集经过基本的自动化清理,但仍保留HTML格式。数据集仅包含'Play-By-Post'部分的独奏和小组角色扮演('游戏')以及OOC线程,不包括各种'社交'部分。数据集还提供了一些元数据和替代用户名。
创建时间:
2024-12-26
原始信息汇总
Elliquiy角色扮演论坛数据集概述
数据集基本信息
- 语言: 英语 (en)
- 数据集名称: elliquiy-rp_2023-04
- 数据规模: 100K < n < 1M
- 文件格式: Parquet
- 许可证: CC-BY-4.0
数据集内容
- 数据来源: Elliquiy论坛,互联网上最大且最古老的成人角色扮演论坛之一。
- 时间范围: 2005年4月至2023年4月。
- 数据量: 包含660万条帖子和11.2万个论坛线程,未压缩文本数据约9GB。
- 数据范围: 仅包含“Play-By-Post”部分的单人、小组角色扮演(“游戏”)和OOC线程,不包括各种“社交”部分。
数据处理
- 数据格式: 消息仍保留HTML格式,但换行符已转换为
- 元数据: 提供了一些元数据,包括用户替代名称(格式为
User0,User1...UserN),这些名称在每线程内唯一,但全局不唯一。 - 清理过程: 进行了基本的自动化清理,但仍保留了HTML标签。
数据集限制与问题
- 信息丢失: 在2023年4月的抓取过程中,部分信息如文本颜色和链接丢失。
- 格式转换困难: 由于用户使用的文本格式,自动转换为Markdown格式非常困难,可能导致严重的格式问题。
- 数据性质: 大部分数据具有性内容。
数据集使用
- 加载工具: 需要使用PyArrow加载Parquet文件,FastParquet由于嵌套数据结构无法正常工作。
- 示例代码: 提供了加载Parquet文件和合并多个文件的Python代码示例。
数据集字段解释
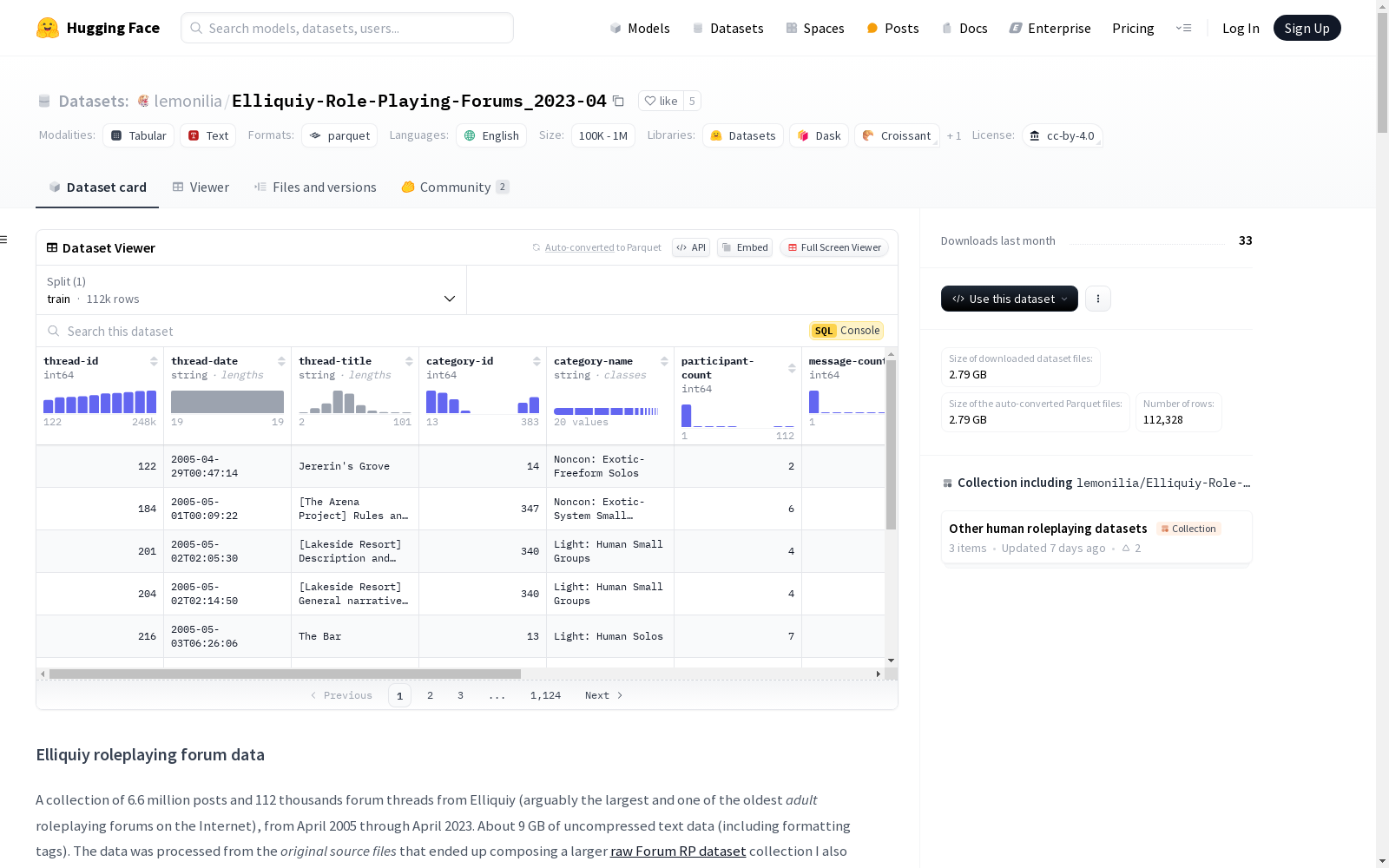
线程字段
- thread-id: 论坛软件分配的线程ID
- thread-date: 线程开帖日期
- thread-title: 用户给定的线程标题
- category-id: 线程所在子论坛的ID
- category-name: 子论坛的全名
- participant-count: 线程中的用户数量
- message-count: 线程中的消息总数
- word-count-total: 线程中所有消息的单词总数
- word-count-median: 线程中消息长度的中位数
消息字段
- index: 消息编号,从零开始
- from: 消息作者的用户名
- from-alternative: 用户的替代名称
- timestamp: 消息的ISO UTC时间戳
消息长度分析
- 趋势: 旧线程中的消息通常较短且更随意,新线程中的消息较长,可能是由于用户群体的缓慢变化或访问要求的自我选择。
清理过程详情
HTML元素级别
- 简化了blockquotes
- 移除了大多数标签的所有属性
- 将字体大小统一为三类:
<small>、正常、<big> - 移除了字体更改
- 移除了特殊CSS效果
- 将背景色文本更改为
<mark> - 将剧透标签转换为
<details><summary>块 - 移除了左右浮动的
<div> - 移除了左右/居中对齐的
<div> - 将居中对齐的
<div>更改为<center> - 将URL及其关联文本重新组合为
<a>元素 - 减少了不适当用于展示目的的
<table>
文本级别
- 将帖子日期转换为ISO格式
- 移除了非标准Unicode空格
- 更改了通用剧透文本
- 移除了部分剩余的BB标签
- 缩短了部分裸URL
- 将
elliquiy.comURL更改为example.com - 移除了部分站点内部URL
- 将所有表情符号转换为emoji
- 移除了过多的换行符和前后空格
- 修复了部分HTML元素间距问题
未完成的操作
- 替换HTML转义字符
- 将图片URL转换为
<img> - 平衡引号和其他应成对出现的字符
- 将花式标点符号更改为ASCII标点符号
- 从数据集中完全移除用户名
搜集汇总
数据集介绍
构建方式
Elliquiy-Role-Playing-Forums_2023-04数据集源自Elliquiy论坛,该论坛是互联网上最大且历史最悠久的成人角色扮演论坛之一。数据集涵盖了2005年4月至2023年4月期间的660万篇帖子和11.2万个论坛线程,数据量达9GB。数据从原始源文件中提取,经过基本自动化清理,保留了HTML格式,仅将换行符转换为`\n`。此外,数据集还提供了用户元数据和替代用户名,以便于使用。
特点
该数据集的特点在于其丰富的内容和独特的结构。数据集不仅包含大量角色扮演相关的文本,还提供了详细的元数据,如线程ID、标题、参与者数量、消息数量等。消息部分则包括发送者名称、替代用户名和时间戳等信息。数据集保留了HTML格式,使得文本的原始结构和格式得以完整呈现。此外,数据集还通过替代用户名保护了用户隐私,确保数据使用的合规性。
使用方法
使用该数据集时,需安装PyArrow库以加载Parquet文件。通过Pandas库可以轻松读取单个Parquet文件或合并多个文件为一个大型DataFrame。数据集中的每条记录包含线程的详细信息和消息列表,用户可以根据需要提取和分析特定线程或消息。此外,数据集还提供了丰富的元数据,便于用户进行深入的数据挖掘和分析。
背景与挑战
背景概述
Elliquiy-Role-Playing-Forums_2023-04数据集源自Elliquiy论坛,该论坛是互联网上规模最大且历史最悠久的成人角色扮演论坛之一。数据集涵盖了自2005年4月至2023年4月期间的660万篇帖子和11.2万个论坛线程,总计约9GB的未压缩文本数据。该数据集由原始源文件处理而成,主要聚焦于“Play-By-Post”板块中的单人及小组角色扮演(“游戏”)以及非角色扮演(OOC)线程。数据集保留了HTML格式的文本内容,并提供了部分元数据,如用户替代名称等。该数据集的发布为研究在线角色扮演社区的语言模式、社交互动及内容创作提供了宝贵的资源。
当前挑战
Elliquiy-Role-Playing-Forums_2023-04数据集在构建过程中面临多重挑战。首先,数据抓取过程中部分信息如文本颜色和链接丢失,影响了数据的完整性。其次,由于用户广泛使用复杂的文本格式,自动化转换为Markdown格式极为困难,可能导致严重的格式问题。此外,数据集中的大部分内容涉及成人主题,这为数据的使用和传播带来了伦理和法律上的限制。在数据处理方面,尽管进行了基本的清理工作,但仍存在HTML标签嵌套、未配对字符等问题,需进一步优化。这些挑战不仅影响了数据的直接可用性,也对后续研究提出了更高的技术要求。
常用场景
经典使用场景
Elliquiy-Role-Playing-Forums_2023-04数据集在角色扮演(RP)和自然语言处理(NLP)领域具有广泛的应用。该数据集包含了从2005年至2023年间Elliquiy论坛上的660万条帖子和11.2万个论坛线程,涵盖了大量的角色扮演对话。研究人员可以利用这些数据深入分析角色扮演中的语言模式、对话结构以及用户互动行为。特别是在研究长文本生成、对话系统设计以及用户行为建模方面,该数据集提供了丰富的素材。
实际应用
在实际应用中,Elliquiy-Role-Playing-Forums_2023-04数据集可以用于开发更智能的对话系统和角色扮演辅助工具。例如,基于该数据集训练的模型可以用于生成更自然、更具沉浸感的角色扮演对话,提升用户的游戏体验。此外,该数据集还可以用于开发情感分析工具,帮助理解用户在角色扮演中的情感变化,从而为在线社区的管理和用户支持提供数据支持。
衍生相关工作
基于Elliquiy-Role-Playing-Forums_2023-04数据集,研究人员已经开展了一系列相关研究。例如,有研究利用该数据集训练了长文本生成模型,用于生成连贯的角色扮演对话。此外,还有研究利用该数据集分析了角色扮演中的叙事结构和用户互动模式,为在线社区的社交行为研究提供了新的视角。这些研究不仅推动了NLP技术的发展,还为理解在线社区中的语言使用和社交互动提供了新的理论支持。
以上内容由遇见数据集搜集并总结生成


