ORIDa
收藏arXiv2025-06-11 更新2025-06-12 收录
下载链接:
https://hello-jinwoo.github.io/orida
下载链接
链接失效反馈官方服务:
资源简介:
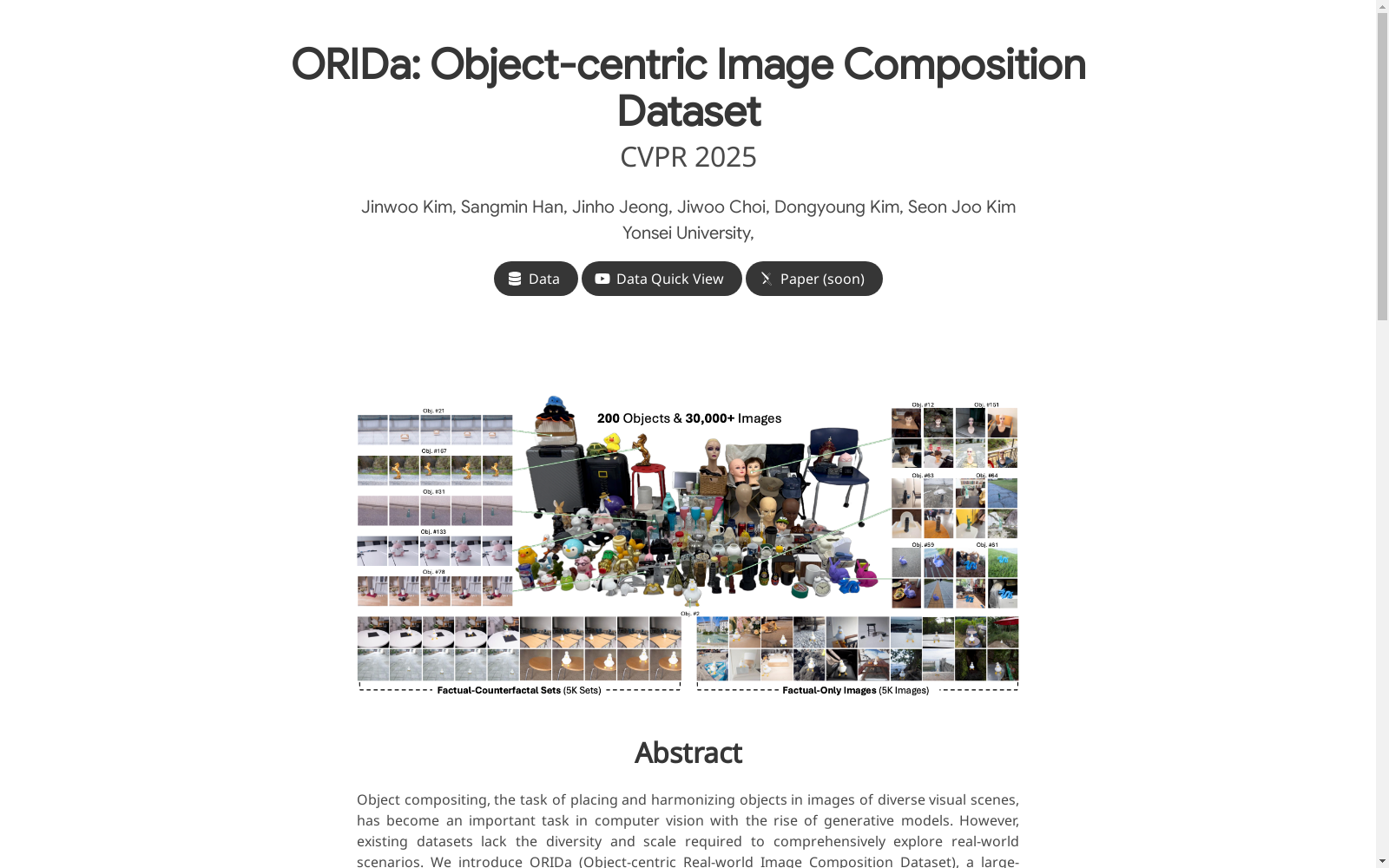
ORIDa是一个大规模的、真实拍摄的数据集,包含超过30,000张图像,涉及200个独特的物体,每个物体在50个不同的场景中展示。数据集包括事实-反事实集和仅事实场景两种类型的数据。事实-反事实集由四张事实图像和一张反事实图像组成,每张事实图像展示了物体在场景中的不同位置,反事实图像则展示了没有物体的场景。仅事实场景包括一张包含特定场景中的物体的图像。ORIDa是第一个公开可用的具有其规模和复杂性的真实世界图像合成数据集。广泛的分析和实验突出了ORIDa作为推进物体合成研究的重要资源。
ORIDa is a large-scale real-world captured dataset containing over 30,000 images, encompassing 200 distinct objects, with each object featured in 50 different scenes. The dataset comprises two data modalities: fact-counterfactual sets and fact-only scenarios. Fact-counterfactual sets are composed of four fact images and one counterfactual image: each fact image displays the object in a unique position within the scene, while the counterfactual image depicts the scene devoid of the object. Fact-only scenarios contain a single image that includes the object in a specific scene. ORIDa is the first publicly available real-world image synthesis dataset with its scale and complexity. Extensive analyses and experiments demonstrate that ORIDa serves as a pivotal resource for advancing research on object synthesis.
提供机构:
延世大学
创建时间:
2025-06-11
原始信息汇总
ORIDa: Object-centric Image Composition Dataset
基本信息
- 发表会议: CVPR 2025
- 作者: Jinwoo Kim, Sangmin Han, Jinho Jeong, Jiwoo Choi, Dongyoung Kim, Seon Joo Kim
- 机构: Yonsei University
数据集概述
- 名称: ORIDa (Object-centric Real-world Image Composition Dataset)
- 规模: 超过30,000张图像
- 对象数量: 200个独特对象
- 特点: 每个对象在不同位置和场景中呈现
数据类型
-
Factual-Counterfactual (F-CF) Sets
- 包含4张事实图像(对象在不同位置)和1张反事实图像(无对象的背景)
- 每个场景共5张图像
-
Factual-Only (F-Only) Images
- 单张图像,包含特定上下文中的对象
- 无对应的背景图像
数据集价值
- 首个公开的大规模、复杂度的真实世界图像合成数据集
- 为对象合成研究提供丰富资源
数据集示例
- F-CF Sets: 左侧展示一组F-CF图像(1张背景 + 4张不同位置的对象图像)
- F-Only Images: 右侧展示F-Only图像(对象在不同场景中的单张图像)
数据集统计
- 按对象统计: 展示事实-only和事实-反事实集合中每个对象的图像数量
- 按属性统计: 展示基于关键属性的对象百分比分布(颜色数量、透明度、反射率、粗糙度、语义类别)
搜集汇总
数据集介绍
构建方式
ORIDa数据集的构建采用了多相机协同拍摄的策略,通过五款三星Galaxy系列手机在PRO模式下获取原始DNG格式图像。数据采集过程严格遵循科学实验设计原则,针对每个场景固定相机参数(包括快门速度、ISO、白平衡和焦距),使用三脚架稳定设备并通过遥控器触发拍摄,确保背景一致性。数据集包含两种结构:事实-反事实集合(F-CF sets)每组包含1张无物体背景图和4张不同位置物体图,事实场景(F-Only)则为单张包含物体的多样化场景图像。经过严格的质量筛选,从初始7000组F-CF和5500张F-Only中分别保留5699组和5035张合格数据。
特点
该数据集的核心特征体现在三个方面:规模上包含200类独特物体的30,000+真实场景图像,每类物体平均覆盖50个不同场景;多样性方面同时具备室内(59%)和室外(41%)环境,物体属性涵盖1-8种颜色梯度及不同透明度、反射率和粗糙度;科学性创新点在于完整捕获物体对场景的光影影响(如阴影、反光)和场景对物体的外观影响双重效应。特别提供原始DNG文件支持ISP增强,并配备GPT-4o生成的物体描述、SAM2分割掩码等多维标注。
使用方法
数据集支持两种典型应用范式:物体移除任务可利用F-CF集合中的背景图作为真值,训练模型消除物体及其衍生光影效果;物体插入任务则通过F-Only图像的场景多样性学习自然合成。实验表明,基于该数据微调的Stable Diffusion模型在用户研究中获得66%-79%的偏好率。研究者可加载原始DNG文件进行ISP参数调整,或利用提供的边界框、分割掩码开发定位敏感模型。数据集按8:2划分训练测试集,建议配合COCO等辅助数据增强泛化能力,但需注意避免合成数据引入的域偏移问题。
背景与挑战
背景概述
ORIDa(Object-centric Real-world Image Composition Dataset)是由延世大学的研究团队于2025年推出的首个大规模真实场景图像合成数据集,旨在解决生成式模型在物体合成任务中面临的数据多样性与规模不足的问题。该数据集包含200个独特物体和超过30,000张真实拍摄图像,涵盖事实-反事实集合(F-CF sets)和事实场景(F-Only images)两种数据类型,为物体重定位、阴影生成等任务提供了丰富的真实世界场景支持。ORIDa通过多角度物体位置变化和多样化背景设计,显著提升了图像合成研究的实验基础,成为计算机视觉领域物体合成任务的重要资源。
当前挑战
ORIDa面临的挑战主要体现在两个方面:领域问题方面,物体合成需解决物体身份保持、光照阴影协调、几何对齐等复杂问题,现有方法在真实感合成与细节处理上仍有不足;数据构建方面,大规模真实场景采集需控制相机参数、光照一致性等变量,过滤背景干扰和焦点偏移等噪声,同时标注物体关键点、分割掩码等多元信息,这些因素显著增加了数据集的构建难度与质量控制复杂度。
常用场景
经典使用场景
ORIDa数据集在计算机视觉领域被广泛应用于对象合成任务的研究,特别是在生成模型的背景下。该数据集通过提供超过30,000张真实拍摄的图像,涵盖了200个独特对象在不同位置和场景中的表现,为对象合成任务提供了丰富的多样性。其独特的Factual-Counterfactual (F-CF) sets和Factual-Only (F-Only) images结构,使得研究者能够深入探索对象在不同环境中的自然融合和位置调整问题。
实际应用
ORIDa数据集在实际应用中具有广泛的潜力,特别是在图像编辑、增强现实和场景理解等领域。通过提供真实世界中的对象和场景数据,该数据集能够帮助开发更自然、更逼真的图像合成工具。例如,在增强现实中,ORIDa可以用于训练模型,使得虚拟对象能够更自然地融入真实场景中,提升用户体验。
衍生相关工作
ORIDa数据集衍生了一系列相关研究工作,特别是在对象合成和图像编辑领域。例如,基于该数据集的研究可以探索对象身份保持、颜色协调和阴影生成等问题。此外,ORIDa还为训练基于扩散模型的图像合成方法提供了高质量的真实数据,推动了对象合成技术的进一步发展。这些工作不仅扩展了数据集的应用范围,也为未来的研究提供了新的方向。
以上内容由遇见数据集搜集并总结生成


