Marcus AI Claims Dataset
收藏github2026-03-04 更新2026-03-06 收录
下载链接:
https://github.com/davegoldblatt/marcus-claims-dataset
下载链接
链接失效反馈官方服务:
资源简介:
Gary Marcus是互联网上最多产的AI怀疑论者。自2022年5月以来,他在Substack上发表了474篇帖子,提出了关于AI的局限性、开发AI的公司以及行业走向的主张。我们提取了每一个可测试的主张,共2218条,并根据截至2026年3月2日的证据对每一条进行了评分。
Gary Marcus is one of the most prolific AI skeptics online. Since May 2022, he has published 474 posts on Substack, putting forth claims concerning the limitations of artificial intelligence, the companies engaged in AI development, and the trajectory of the AI industry. We extracted all testable claims, amounting to a total of 2218 entries, and scored each one based on the evidence available as of March 2, 2026.
创建时间:
2026-03-03
原始信息汇总
Marcus AI Claims Dataset 数据集概述
数据集简介
该数据集系统性地收集并评估了AI评论家Gary Marcus自2022年5月以来在其Substack上发表的关于AI局限性、相关公司及行业发展的可验证主张。数据集共包含2,218项可测试的主张,并依据截至2026年3月2日的证据对每项主张进行了评估。
核心评估结果
在证据可核查的主张中,评估结果分布如下:
- 59.9% 的主张获得证据支持。
- 33.7% 的主张证据混杂。
- 6.4% 的主张被证据反驳。
主张分类与准确性
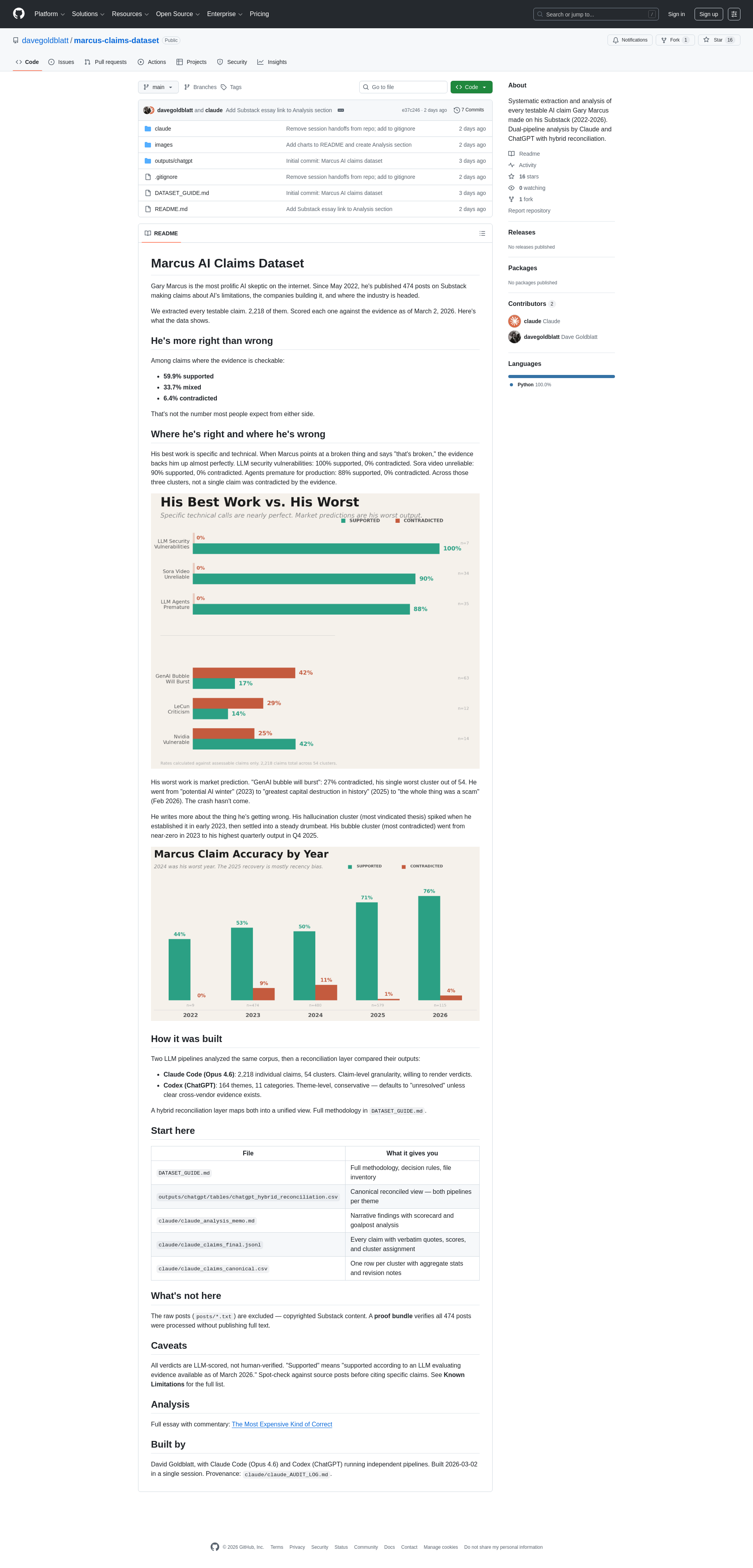
- 准确性高的领域:涉及具体技术问题的主张准确性极高。例如,关于LLM安全漏洞的主张100%获得支持;关于Sora视频不可靠性的主张90%获得支持;关于智能体尚不适用于生产环境的主张88%获得支持。在这些类别中,没有一项主张被证据反驳。
- 准确性低的领域:市场预测类主张的准确性较低。例如,关于“生成式AI泡沫将破裂”的主张集群是其54个集群中反驳率最高的,达到27%。相关预测随时间推移不断变化,但预期的市场崩溃并未发生。
数据集构建方法
数据集通过两个独立的LLM流程分析同一语料库构建,并设有协调层对比输出结果:
- Claude Code (Opus 4.6)流程:识别出2,218项独立主张,归类为54个集群,并在主张层面给出判定。
- Codex (ChatGPT)流程:识别出164个主题,归类为11个类别,在主题层面采取保守策略,除非存在明确的跨供应商证据,否则默认判定为“未解决”。
- 混合协调层:将两个流程的输出映射到一个统一的视图中。完整的方法论记录在
DATASET_GUIDE.md文件中。
数据集文件与内容
| 文件路径 | 内容描述 |
|---|---|
DATASET_GUIDE.md |
完整的方法论、决策规则和文件清单。 |
outputs/chatgpt/tables/chatgpt_hybrid_reconciliation.csv |
规范的协调视图,包含每个主题的两个流程分析结果。 |
claude/claude_analysis_memo.md |
包含记分卡和目标分析的叙述性发现。 |
claude/claude_claims_final.jsonl |
包含每项主张的原文引用、评分和集群归属。 |
claude/claude_claims_canonical.csv |
每个集群的汇总统计数据及修订说明(每集群一行)。 |
数据范围与限制
- 未包含的内容:原始的Substack帖子(
posts/*.txt)因版权原因被排除。一个证明包用于验证所有474篇帖子已被处理,但未发布全文。 - 主要注意事项:所有判定均由LLM评分,未经人工验证。“支持”意味着“根据LLM对截至2026年3月2日可用证据的评估,该主张获得支持”。在引用具体主张前,建议对照源帖子进行抽查。完整限制列表请参见已知限制部分。
背景信息
- 创建者:David Goldblatt。
- 构建工具:使用Claude Code (Opus 4.6) 和 Codex (ChatGPT) 运行独立流程。
- 构建日期:2026年3月2日,单次会话完成。
- 相关分析:完整的评论文章发布于 https://davesquickhits.substack.com/p/the-most-expensive-kind-of-correct。
搜集汇总
数据集介绍
构建方式
在人工智能伦理与批判性研究领域,Marcus AI Claims Dataset的构建体现了对大规模文本数据系统性分析的严谨方法。该数据集通过两条独立的LLM处理流水线对Gary Marcus在Substack平台发布的474篇帖子进行深度解析,其中Claude Code流水线提取了2,218条可验证的具体主张并将其归纳为54个主题簇,而Codex流水线则采用更为保守的策略识别出164个主题和11个类别。最终通过混合协调层将两条流水线的输出映射为统一视图,并依据截至2026年3月2日的证据对每条主张进行支持、混合或矛盾的分类标注,整个过程在严格的数据溯源记录下完成。
特点
该数据集的核心特征在于其多维度的结构化标注体系与动态证据评估机制。每条主张不仅包含原始文本的逐字引用和主题簇归属,更配备了基于时间截点的证据支持度评分,形成了从微观主张到宏观主题的完整分析链条。数据集中特别突出了主张验证的时间敏感性,例如在人工智能安全漏洞、视频生成可靠性等具体技术领域呈现出高度支持率,而在市场预测等宏观判断领域则显示出显著分歧。这种设计使得数据集能够清晰展现批判性主张在不同技术维度与时间维度上的证据演化轨迹。
使用方法
研究者可通过数据集提供的分层文件系统开展多粒度分析,从宏观趋势把握到微观主张验证均具备完整路径。核心分析建议从协调视图文件入手,该文件整合了两条流水线的分析结果;对于深度主题研究则可查阅按簇聚合的统计文件,其中包含各主题的支持度分布与修订注释。使用过程中需特别注意所有判断均基于LLM对特定时间点证据的评估,建议结合原始帖子进行关键主张的交叉验证,同时可利用数据集附带的审计日志确保分析过程的可复现性。
背景与挑战
背景概述
Marcus AI Claims Dataset 诞生于2026年,由研究员David Goldblatt主导构建,旨在系统性地评估人工智能领域知名评论家Gary Marcus在Substack平台上发表的数百篇论述。该数据集的核心研究问题聚焦于对Marcus所提出的两千余项可验证主张进行证据支持度的量化分析,从而客观审视其关于人工智能技术局限性、产业发展及安全风险等方面观点的准确性。这一工作不仅为AI领域的学术讨论提供了实证基础,也推动了关于技术批判与证据评估之间关系的深入思考,对促进AI研究的理性对话具有显著意义。
当前挑战
该数据集所应对的领域挑战在于如何对复杂、动态且常具争议性的人工智能技术论断进行标准化、可复现的验证,这涉及跨技术安全、市场预测与伦理风险等多维议题的交叉评估。在构建过程中,研究团队面临双重挑战:一是处理大规模非结构化文本并从中精准提取可检验的主张,需克服自然语言理解中的语义模糊性与上下文依赖性;二是依赖大型语言模型进行自动化证据评分,其方法本身存在局限性,如模型可能受训练数据偏见影响,且缺乏人类专家的最终校验,这要求构建过程必须设计严谨的复核流程以确保评估的可靠性。
常用场景
经典使用场景
在人工智能伦理与可信性评估领域,Marcus AI Claims Dataset为研究者提供了一个系统化分析AI领域公共言论与实证证据对齐度的基准工具。该数据集通过结构化提取Gary Marcus在Substack平台上发表的474篇文章中的2218条可验证主张,并依据截至2026年3月的证据进行评分,典型应用于量化评估AI批评性论述的准确性分布。研究者可借助该数据集深入探究AI技术局限性、安全漏洞及市场预测等主题的论断与实证一致性,从而在自然语言处理与社会计算交叉领域构建可重复的言论可信度分析框架。
衍生相关工作
该数据集的创新方法论已催生多领域衍生研究。其双LLM管道验证架构(Claude Opus与Codex并行分析)为言论可信度自动评估提供了可扩展的技术范式,后续研究将其扩展至气候变化、公共卫生等领域的争议性论述分析。基于主题聚类的时序准确性图谱(如幻觉主题与泡沫主题的发表动态)进一步激发了计算社会科学中技术叙事演变规律的建模工作,推动了动态知识图谱与证据追溯系统的交叉创新。
数据集最近研究
最新研究方向
在人工智能伦理与可信评估领域,Marcus AI Claims Dataset 的构建标志着一种新兴的研究范式,即通过系统化采集与验证领域内关键意见领袖的公开论断,以量化方式追踪技术演进与舆论预测之间的动态关系。该数据集聚焦于对AI局限性与行业趋势的前瞻性主张进行证据回溯分析,揭示了在模型安全漏洞、多模态生成可靠性等具体技术议题上,实证支持率显著高于市场预测类宏观判断。这一发现促使学界更加关注如何将主观性较强的行业评论转化为可检验的假设,进而推动建立基于证据链的AI发展评估框架。当前研究热点集中于利用此类标注数据训练细粒度主张验证模型,并探索跨时间维度的预测准确性演化规律,为理解技术炒作周期与实证进展之间的张力提供了宝贵的数据基础。
以上内容由遇见数据集搜集并总结生成


