Chinese-SimpleQA
收藏Hugging Face2024-11-17 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/OpenStellarTeam/Chinese-SimpleQA
下载链接
链接失效反馈官方服务:
资源简介:
Chinese SimpleQA是一个全面的中文基准,用于评估语言模型回答简短问题的事实性能力。它主要具有五个特性:中文、多样性、高质量、静态和易于评估。数据集涵盖了6个主要主题,包括99个细分的子主题,从人文到科学和工程。数据集包含3000个高质量问题,旨在帮助开发者更深入地理解其模型在中文领域的事实正确性,并为算法研究提供重要基础。
Chinese SimpleQA is a comprehensive Chinese benchmark for evaluating the factual capability of language models when answering short questions. It has five core characteristics: Chinese-language support, diversity, high quality, static nature, and ease of evaluation. The dataset covers 6 major themes, including 99 subdivided subtopics ranging from humanities to science and engineering. It contains 3,000 high-quality questions, designed to help developers gain a deeper understanding of their models' factual correctness in the Chinese language domain, and provide a crucial foundation for algorithmic research.
创建时间:
2024-11-12
原始信息汇总
Chinese SimpleQA 数据集概述
基本信息
- 许可证: cc-by-nc-sa-4.0
- 任务类别: 问答
- 语言: 中文
- 数据集名称: Chinese SimpleQA
- 数据规模: 10K<n<100K
数据集简介
- 目标: 评估语言模型回答简短问题的真实性能力。
- 主要特点:
- 中文: 专注于中文语言,全面评估现有大型语言模型(LLMs)在中文方面的真实性能力。
- 多样性: 涵盖6个主要主题,包括“中国文化”、“人文”、“工程、技术与应用科学”、“生活、艺术与文化”、“社会”和“自然科学”,共计99个细粒度子主题。
- 高质量: 通过全面严格的质量控制流程,确保数据集的质量和准确性。
- 静态: 所有参考答案不会随时间变化,保持数据集的常青特性。
- 易于评估: 问题和答案非常简短,可以通过现有的LLMs(如OpenAI API)快速运行评分程序。
数据集内容
- 主题覆盖: 6个主要主题,99个细粒度子主题。
- 问题数量: 3000个高质量问题。
引用
@misc{he2024chinesesimpleqachinesefactuality, title={Chinese SimpleQA: A Chinese Factuality Evaluation for Large Language Models}, author={Yancheng He and Shilong Li and Jiaheng Liu and Yingshui Tan and Weixun Wang and Hui Huang and Xingyuan Bu and Hangyu Guo and Chengwei Hu and Boren Zheng and Zhuoran Lin and Xuepeng Liu and Dekai Sun and Shirong Lin and Zhicheng Zheng and Xiaoyong Zhu and Wenbo Su and Bo Zheng}, year={2024}, eprint={2411.07140}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2411.07140}, }
搜集汇总
数据集介绍
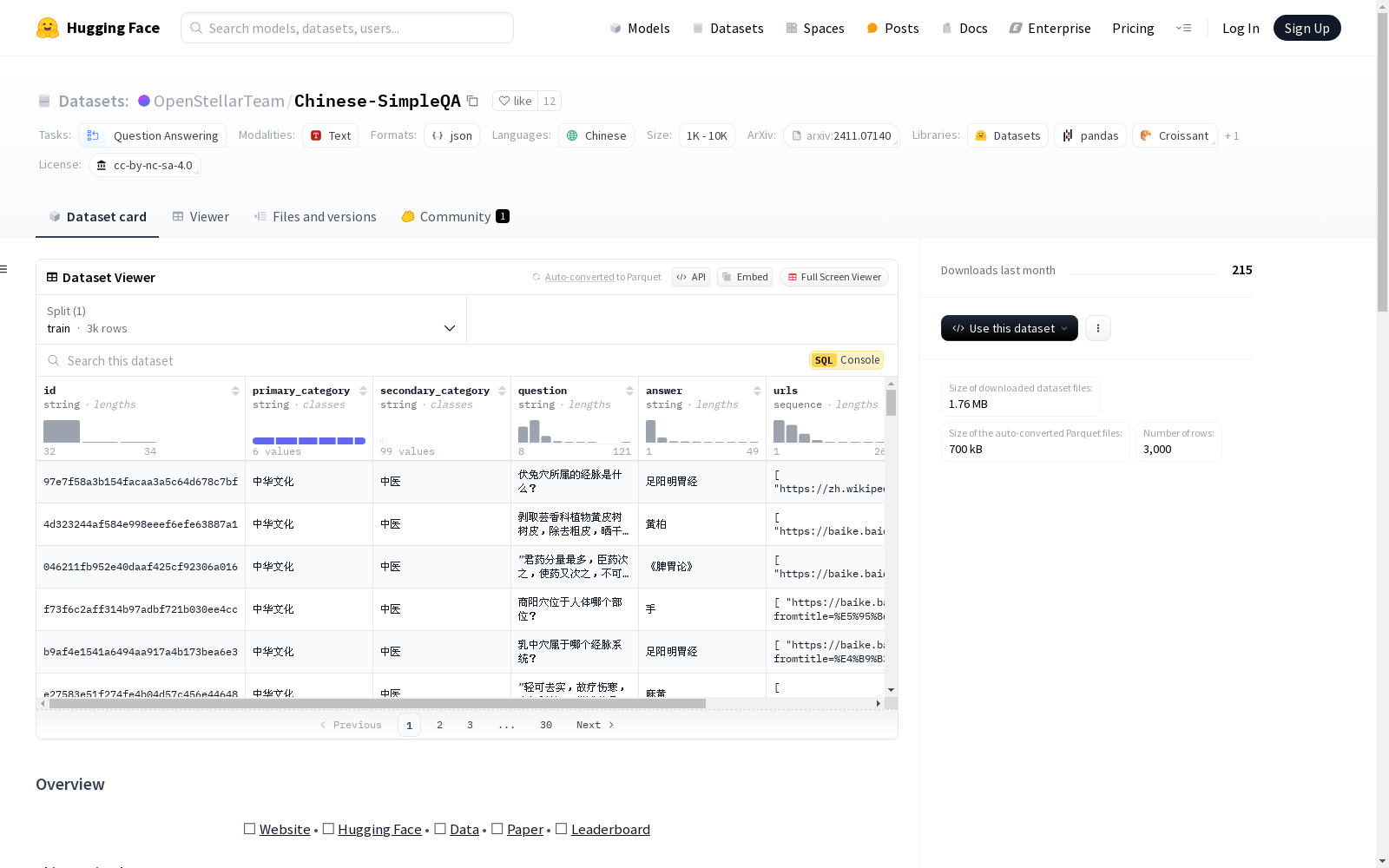
构建方式
Chinese-SimpleQA数据集的构建旨在解决生成模型在中文领域中的事实性评估问题。该数据集由3000个高质量问题组成,涵盖6个主要主题和99个细分主题,从人文到科学与工程领域均有涉及。为确保数据质量,研究团队实施了全面且严格的质量控制流程,确保每个问题的准确性和可靠性。此外,所有参考答案均保持静态,以确保评估的长期有效性。
使用方法
Chinese-SimpleQA数据集的使用方法较为直观,用户可通过Hugging Face平台直接访问并下载数据集。该数据集主要用于评估大语言模型在中文领域的事实性能力,用户可通过其提供的3000个问题对模型进行测试。评估结果可通过现有的语言模型API快速生成,且研究团队还维护了一个全面的排行榜,供用户参考。此外,用户可通过访问相关网站和论文获取更多详细信息,并引用相关文献以支持其研究工作。
背景与挑战
背景概述
Chinese-SimpleQA数据集由OpenStellarTeam于2024年推出,旨在评估大语言模型在中文短问答任务中的事实性能力。该数据集涵盖了6大主题和99个细分主题,内容从人文到理工科,具有多样性、高质量、静态性和易评估性等特点。作为首个专注于中文事实性评估的基准数据集,Chinese-SimpleQA填补了现有知识评估集在数据时效性、评估准确性和覆盖范围上的不足,为中文社区在模型事实性研究领域提供了重要工具。该数据集的推出不仅促进了中文大模型的发展,也为相关算法的研究提供了坚实的基础。
当前挑战
Chinese-SimpleQA数据集在构建和应用过程中面临多重挑战。首先,如何确保数据集的高质量和准确性是一个关键问题,尤其是在涵盖广泛主题和细分领域的情况下。其次,数据集的静态性要求所有参考答案在时间上保持不变,这在一定程度上限制了数据集的动态更新能力。此外,尽管数据集设计为易于评估,但在实际应用中,如何通过现有大语言模型快速、准确地评估模型的事实性能力仍是一个技术难题。最后,数据集的多样性和广泛覆盖性也带来了数据收集和标注的复杂性,这对数据集的构建过程提出了更高的要求。
常用场景
经典使用场景
Chinese-SimpleQA数据集在自然语言处理领域中被广泛用于评估语言模型在中文环境下的问答能力。该数据集通过涵盖人文、社会科学、自然科学等多个领域的3000个高质量问题,为研究者提供了一个全面的测试平台,用以检验模型在中文语境中的事实准确性。
解决学术问题
Chinese-SimpleQA数据集解决了当前中文语言模型在事实性评估方面的不足。通过提供多样化的主题和子主题,该数据集帮助研究者更准确地评估模型在中文环境下的表现,填补了现有评估工具如CommonSenseQA、CMMLU和C-Eval等多选题评估集的空白,推动了中文语言模型事实性研究的发展。
实际应用
在实际应用中,Chinese-SimpleQA数据集被用于开发和优化中文语言模型,特别是在需要高事实准确性的场景中,如智能客服、教育辅助系统和信息检索系统。通过该数据集的评估,开发者能够更好地理解模型在中文环境下的表现,从而进行针对性的改进和优化。
数据集最近研究
最新研究方向
在自然语言处理领域,生成模型的幻觉问题一直是研究的难点之一。Chinese-SimpleQA作为首个专注于中文事实性评估的基准数据集,为衡量语言模型在中文语境下的准确性提供了重要工具。该数据集涵盖了六大主题及99个细分领域,确保了其多样性和广泛性。近期研究聚焦于利用Chinese-SimpleQA评估现有大型语言模型的事实性能力,特别是在中文文化、人文、工程技术、生活艺术、社会和自然科学等领域的表现。通过这一数据集,研究者能够更深入地理解模型在中文语境下的准确性,并推动中文基础模型的进一步发展。此外,Chinese-SimpleQA的静态特性确保了评估的长期有效性,为算法研究提供了坚实的基础。
以上内容由遇见数据集搜集并总结生成


