ASL STEM Wiki
收藏arXiv2024-11-09 更新2024-11-12 收录
下载链接:
https://www.microsoft.com/en-us/research/project/asl-stem-wiki
下载链接
链接失效反馈官方服务:
资源简介:
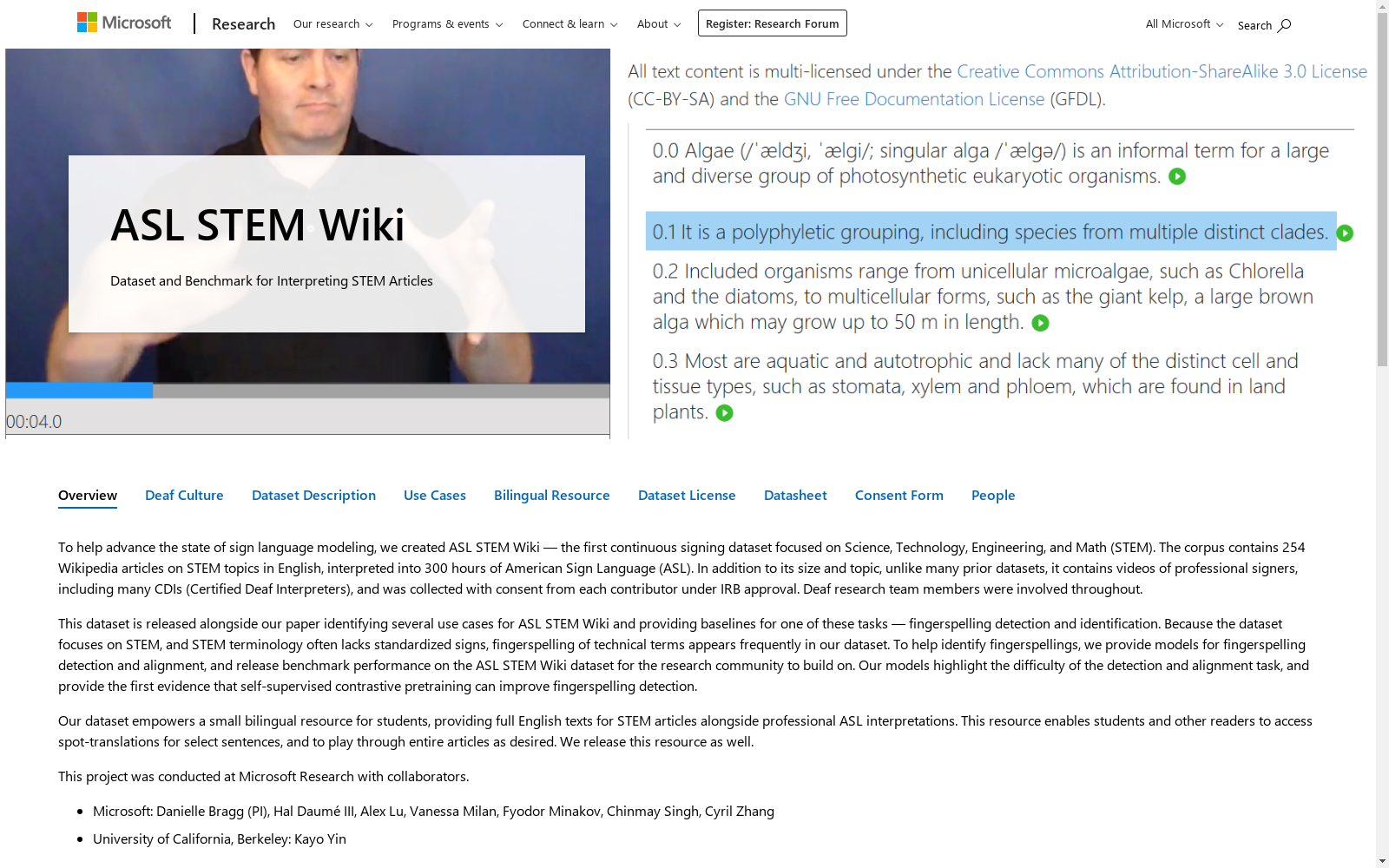
ASL STEM Wiki是由加州大学伯克利分校和微软研究院合作创建的一个平行语料库,包含254篇STEM主题的英文维基百科文章及其对应的美国手语(ASL)翻译。该数据集由37名认证手语翻译员录制,总时长超过300小时,包含64,266个句子。数据集的创建旨在解决聋哑和听力障碍学生在STEM教育中面临的资源匮乏问题,特别是STEM术语在ASL中的标准化缺失。ASL STEM Wiki不仅为AI模型提供了丰富的训练数据,还为自动手语建议系统的发展提供了基础,旨在提高STEM教育内容的可访问性和质量。
ASL STEM Wiki is a parallel corpus co-developed by the University of California, Berkeley and Microsoft Research. It encompasses 254 STEM-themed English Wikipedia articles and their corresponding American Sign Language (ASL) translations. Recorded by 37 certified sign language interpreters, this dataset has a total duration of over 300 hours and contains 64,266 sentences. The dataset was created to address the resource scarcity faced by deaf and hard-of-hearing students in STEM education, particularly the lack of standardization for STEM terminology in ASL. ASL STEM Wiki not only provides rich training data for AI models but also lays a foundation for the development of automatic sign language recommendation systems, aiming to improve the accessibility and quality of STEM educational content.
提供机构:
加州大学伯克利分校、微软研究院、马里兰大学
创建时间:
2024-11-09
搜集汇总
数据集介绍
构建方式
ASL STEM Wiki数据集通过精心策划和专业录制构建而成。首先,从Wikipedia中筛选出254篇与STEM主题相关的文章,并由37名经过认证的ASL(美国手语)口译员进行翻译,形成了一个包含64,266个句子和超过300小时ASL视频的平行语料库。这一过程确保了数据集的高质量和专业性,为后续的AI模型开发提供了坚实的基础。
特点
ASL STEM Wiki数据集的显著特点在于其专注于STEM领域的连续手语数据,这是首个此类数据集。此外,数据集中的视频均由专业口译员录制,确保了手语表达的准确性和一致性。数据集还特别关注了手指拼写(fingerspelling)的使用,这在STEM内容的翻译中尤为常见,为研究手指拼写检测和建议提供了丰富的素材。
使用方法
ASL STEM Wiki数据集可用于多种自然语言处理任务,特别是与手语理解和翻译相关的研究。例如,可以用于开发自动手语建议系统,检测手指拼写并建议合适的ASL手语。此外,数据集还可用于研究翻译效应(translationese)和口译效应(interpretese),以及探索不同口译员对同一英语句子的手语变异。这些应用有助于提升STEM教育对聋哑学生的可访问性和质量。
背景与挑战
背景概述
ASL STEM Wiki数据集由加州大学伯克利分校和微软研究院共同创建,旨在解决聋哑和听力障碍学生在科学、技术、工程和数学(STEM)教育中面临的资源匮乏问题。该数据集包含了254篇STEM主题的维基百科文章,这些文章被翻译成超过300小时的美国手语(ASL)视频。ASL STEM Wiki是首个专注于STEM内容的连续手语数据集,为开发ASL教育资源的AI模型提供了基础。该数据集的创建不仅填补了ASL在STEM领域的资源空白,还为研究者提供了宝贵的数据资源,以推动手语理解和教育技术的发展。
当前挑战
ASL STEM Wiki数据集在构建过程中面临多项挑战。首先,STEM领域的专业术语在ASL中缺乏标准化,导致翻译过程中频繁使用手指拼写,这限制了聋哑学生的学习效果。其次,数据集的构建需要专业手语翻译人员的参与,确保翻译的准确性和专业性。此外,数据集的标注工作复杂,需要识别和标注手指拼写部分,这对模型的训练提出了高要求。最后,数据集的使用需注意其内容受英语影响,可能不完全代表自然手语,因此在模型训练和应用中需结合其他自然手语数据集以提高模型的泛化能力。
常用场景
经典使用场景
ASL STEM Wiki数据集的经典使用场景在于其为科学、技术、工程和数学(STEM)领域的文章提供了英语与美国手语(ASL)之间的平行语料库。该数据集通过254篇维基百科文章及其对应的超过300小时的ASL视频,为研究者提供了丰富的资源,以开发和评估AI模型在STEM教育中的应用,特别是针对聋哑和听力障碍学生的教育需求。
解决学术问题
ASL STEM Wiki数据集解决了聋哑和听力障碍学生在STEM教育中面临的主要障碍,即缺乏以手语表达的STEM资源。通过提供大量的STEM内容的手语解释,该数据集促进了AI工具的开发,这些工具能够识别手指拼写并建议适当的手语表达,从而提高教育材料的可用性和聋哑学生的学习效果。
衍生相关工作
ASL STEM Wiki数据集的发布催生了一系列相关研究工作,包括对手指拼写检测和手语对齐模型的开发。这些模型利用数据集中的大量未标记视频进行对比学习,显著提高了手指拼写检测的准确性。此外,该数据集还启发了对手语变异和手语链接/检索的研究,以及对手语翻译中翻译效应的检测和修复研究。
以上内容由遇见数据集搜集并总结生成


