NortheasternUniversity/big_patent
收藏Hugging Face2025-09-25 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/NortheasternUniversity/big_patent
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
- 10K<n<100K
- 1M<n<10M
source_datasets:
- original
task_categories:
- summarization
task_ids: []
paperswithcode_id: bigpatent
pretty_name: Big Patent
tags:
- patent-summarization
dataset_info:
- config_name: a
features:
- name: description
dtype: string
- name: abstract
dtype: string
splits:
- name: train
num_bytes: 5683460620
num_examples: 174134
- name: validation
num_bytes: 313324505
num_examples: 9674
- name: test
num_bytes: 316633277
num_examples: 9675
download_size: 2622492121
dataset_size: 6313418402
- config_name: all
default: true
features:
- name: description
dtype: string
- name: abstract
dtype: string
splits:
- name: train
num_bytes: 38367048389
num_examples: 1207222
- name: validation
num_bytes: 2115827002
num_examples: 67068
- name: test
num_bytes: 2129505280
num_examples: 67072
download_size: 17096051620
dataset_size: 42612380671
- config_name: b
features:
- name: description
dtype: string
- name: abstract
dtype: string
splits:
- name: train
num_bytes: 4236070976
num_examples: 161520
- name: validation
num_bytes: 234425138
num_examples: 8973
- name: test
num_bytes: 231538734
num_examples: 8974
download_size: 1955712179
dataset_size: 4702034848
- config_name: c
features:
- name: description
dtype: string
- name: abstract
dtype: string
splits:
- name: train
num_bytes: 4506249306
num_examples: 101042
- name: validation
num_bytes: 244684775
num_examples: 5613
- name: test
num_bytes: 252566793
num_examples: 5614
download_size: 1919166981
dataset_size: 5003500874
- config_name: d
features:
- name: description
dtype: string
- name: abstract
dtype: string
splits:
- name: train
num_bytes: 264717412
num_examples: 10164
- name: validation
num_bytes: 14560482
num_examples: 565
- name: test
num_bytes: 14403430
num_examples: 565
download_size: 123268328
dataset_size: 293681324
- config_name: e
features:
- name: description
dtype: string
- name: abstract
dtype: string
splits:
- name: train
num_bytes: 881101433
num_examples: 34443
- name: validation
num_bytes: 48646158
num_examples: 1914
- name: test
num_bytes: 48586429
num_examples: 1914
download_size: 412277995
dataset_size: 978334020
- config_name: f
features:
- name: description
dtype: string
- name: abstract
dtype: string
splits:
- name: train
num_bytes: 2146383473
num_examples: 85568
- name: validation
num_bytes: 119632631
num_examples: 4754
- name: test
num_bytes: 119596303
num_examples: 4754
download_size: 974406682
dataset_size: 2385612407
- config_name: g
features:
- name: description
dtype: string
- name: abstract
dtype: string
splits:
- name: train
num_bytes: 8877854206
num_examples: 258935
- name: validation
num_bytes: 492581177
num_examples: 14385
- name: test
num_bytes: 496324853
num_examples: 14386
download_size: 3923986648
dataset_size: 9866760236
- config_name: h
features:
- name: description
dtype: string
- name: abstract
dtype: string
splits:
- name: train
num_bytes: 8075621958
num_examples: 257019
- name: validation
num_bytes: 447602356
num_examples: 14279
- name: test
num_bytes: 445460513
num_examples: 14279
download_size: 3471504387
dataset_size: 8968684827
- config_name: y
features:
- name: description
dtype: string
- name: abstract
dtype: string
splits:
- name: train
num_bytes: 3695589005
num_examples: 124397
- name: validation
num_bytes: 200369780
num_examples: 6911
- name: test
num_bytes: 204394948
num_examples: 6911
download_size: 1693564116
dataset_size: 4100353733
configs:
- config_name: a
data_files:
- split: train
path: a/train-*
- split: validation
path: a/validation-*
- split: test
path: a/test-*
- config_name: all
data_files:
- split: train
path: all/train-*
- split: validation
path: all/validation-*
- split: test
path: all/test-*
default: true
- config_name: b
data_files:
- split: train
path: b/train-*
- split: validation
path: b/validation-*
- split: test
path: b/test-*
- config_name: c
data_files:
- split: train
path: c/train-*
- split: validation
path: c/validation-*
- split: test
path: c/test-*
- config_name: d
data_files:
- split: train
path: d/train-*
- split: validation
path: d/validation-*
- split: test
path: d/test-*
- config_name: e
data_files:
- split: train
path: e/train-*
- split: validation
path: e/validation-*
- split: test
path: e/test-*
- config_name: f
data_files:
- split: train
path: f/train-*
- split: validation
path: f/validation-*
- split: test
path: f/test-*
- config_name: g
data_files:
- split: train
path: g/train-*
- split: validation
path: g/validation-*
- split: test
path: g/test-*
- config_name: h
data_files:
- split: train
path: h/train-*
- split: validation
path: h/validation-*
- split: test
path: h/test-*
- config_name: y
data_files:
- split: train
path: y/train-*
- split: validation
path: y/validation-*
- split: test
path: y/test-*
---
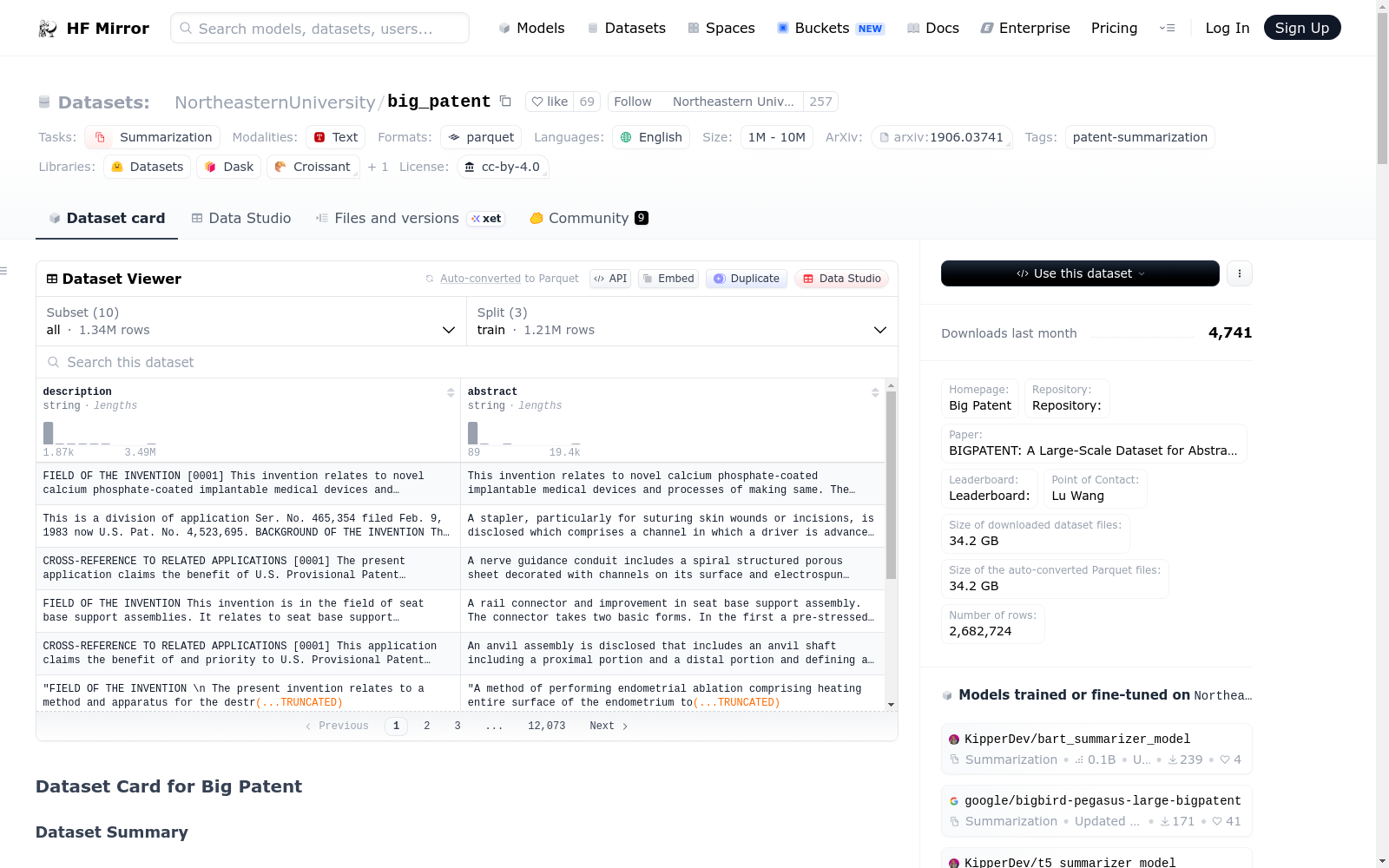
# Dataset Card for Big Patent
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Big Patent](https://evasharma.github.io/bigpatent/)
- **Repository:**
- **Paper:** [BIGPATENT: A Large-Scale Dataset for Abstractive and Coherent Summarization](https://arxiv.org/abs/1906.03741)
- **Leaderboard:**
- **Point of Contact:** [Lu Wang](mailto:wangluxy@umich.edu)
### Dataset Summary
BIGPATENT, consisting of 1.3 million records of U.S. patent documents along with human written abstractive summaries.
Each US patent application is filed under a Cooperative Patent Classification (CPC) code.
There are nine such classification categories:
- a: Human Necessities
- b: Performing Operations; Transporting
- c: Chemistry; Metallurgy
- d: Textiles; Paper
- e: Fixed Constructions
- f: Mechanical Engineering; Lightning; Heating; Weapons; Blasting
- g: Physics
- h: Electricity
- y: General tagging of new or cross-sectional technology
Current defaults are 2.1.2 version (fix update to cased raw strings) and 'all' CPC codes:
```python
from datasets import load_dataset
ds = load_dataset("big_patent") # default is 'all' CPC codes
ds = load_dataset("big_patent", "all") # the same as above
ds = load_dataset("big_patent", "a") # only 'a' CPC codes
from datasets import concatenate_datasets
# Concatenate multiple codes
ds = concatenate_datasets([
load_dataset("big_patent", "a", split="train"),
load_dataset("big_patent", "b", split="train"),
])
```
To use 1.0.0 version (lower cased tokenized words), use an older revision of this dataset and pass both parameters `codes` and `version`:
```python
revision = "e807b1d5492aa5f4fac08f3f6c7c85c72887ca12"
ds = load_dataset("big_patent", codes="all", version="1.0.0", revision=revision)
ds = load_dataset("big_patent", codes="a", version="1.0.0", revision=revision)
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
English
## Dataset Structure
### Data Instances
Each instance contains a pair of `description` and `abstract`. `description` is extracted from the Description section of the Patent while `abstract` is extracted from the Abstract section.
```
{
'description': 'FIELD OF THE INVENTION \n [0001] This invention relates to novel calcium phosphate-coated implantable medical devices and processes of making same. The unique calcium-phosphate coated implantable medical devices minimize...',
'abstract': 'This invention relates to novel calcium phosphate-coated implantable medical devices...'
}
```
### Data Fields
- `description`: detailed description of patent.
- `abstract`: Patent abastract.
### Data Splits
| | train | validation | test |
|:----|------------------:|-------------:|-------:|
| all | 1207222 | 67068 | 67072 |
| a | 174134 | 9674 | 9675 |
| b | 161520 | 8973 | 8974 |
| c | 101042 | 5613 | 5614 |
| d | 10164 | 565 | 565 |
| e | 34443 | 1914 | 1914 |
| f | 85568 | 4754 | 4754 |
| g | 258935 | 14385 | 14386 |
| h | 257019 | 14279 | 14279 |
| y | 124397 | 6911 | 6911 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
```bibtex
@article{DBLP:journals/corr/abs-1906-03741,
author = {Eva Sharma and
Chen Li and
Lu Wang},
title = {{BIGPATENT:} {A} Large-Scale Dataset for Abstractive and Coherent
Summarization},
journal = {CoRR},
volume = {abs/1906.03741},
year = {2019},
url = {http://arxiv.org/abs/1906.03741},
eprinttype = {arXiv},
eprint = {1906.03741},
timestamp = {Wed, 26 Jun 2019 07:14:58 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1906-03741.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
### Contributions
Thanks to [@mattbui](https://github.com/mattbui) for adding this dataset.
提供机构:
NortheasternUniversity
原始信息汇总
数据集概述
- 名称: Big Patent
- 语言: 英语
- 许可证: CC-BY-4.0
- 多语言性: 单语
- 大小:
- 100K<n<1M
- 10K<n<100K
- 1M<n<10M
- 源数据: 原始
- 任务类别: 摘要生成
- 标签: 专利摘要
数据集结构
数据实例
- 描述: 从专利的描述部分提取的详细描述。
- 摘要: 从专利的摘要部分提取的摘要。
数据字段
- description: 专利的详细描述。
- abstract: 专利的摘要。
数据分割
| 配置名称 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| all | 1207222 | 67068 | 67072 |
| a | 174134 | 9674 | 9675 |
| b | 161520 | 8973 | 8974 |
| c | 101042 | 5613 | 5614 |
| d | 10164 | 565 | 565 |
| e | 34443 | 1914 | 1914 |
| f | 85568 | 4754 | 4754 |
| g | 258935 | 14385 | 14386 |
| h | 257019 | 14279 | 14279 |
| y | 124397 | 6911 | 6911 |
数据集配置
- 配置名称: a, all, b, c, d, e, f, g, h, y
- 特征:
- description: 字符串类型
- abstract: 字符串类型
- 下载大小: 10142923776字节
- 数据集大小: 根据配置不同,大小在293681324字节至9866760236字节之间变化。
搜集汇总
数据集介绍
背景与挑战
背景概述
The BIGPATENT dataset comprises 1.3 million U.S. patent documents with abstractive summaries, categorized into nine technical fields. It is designed for tasks such as summarization, offering a rich resource for natural language processing research and applications in patent analysis.
以上内容由遇见数据集搜集并总结生成


