ENIGMAEVAL
收藏arXiv2025-02-15 更新2025-02-15 收录
下载链接:
https://scale.com/leaderboard/enigma_eval
下载链接
链接失效反馈官方服务:
资源简介:
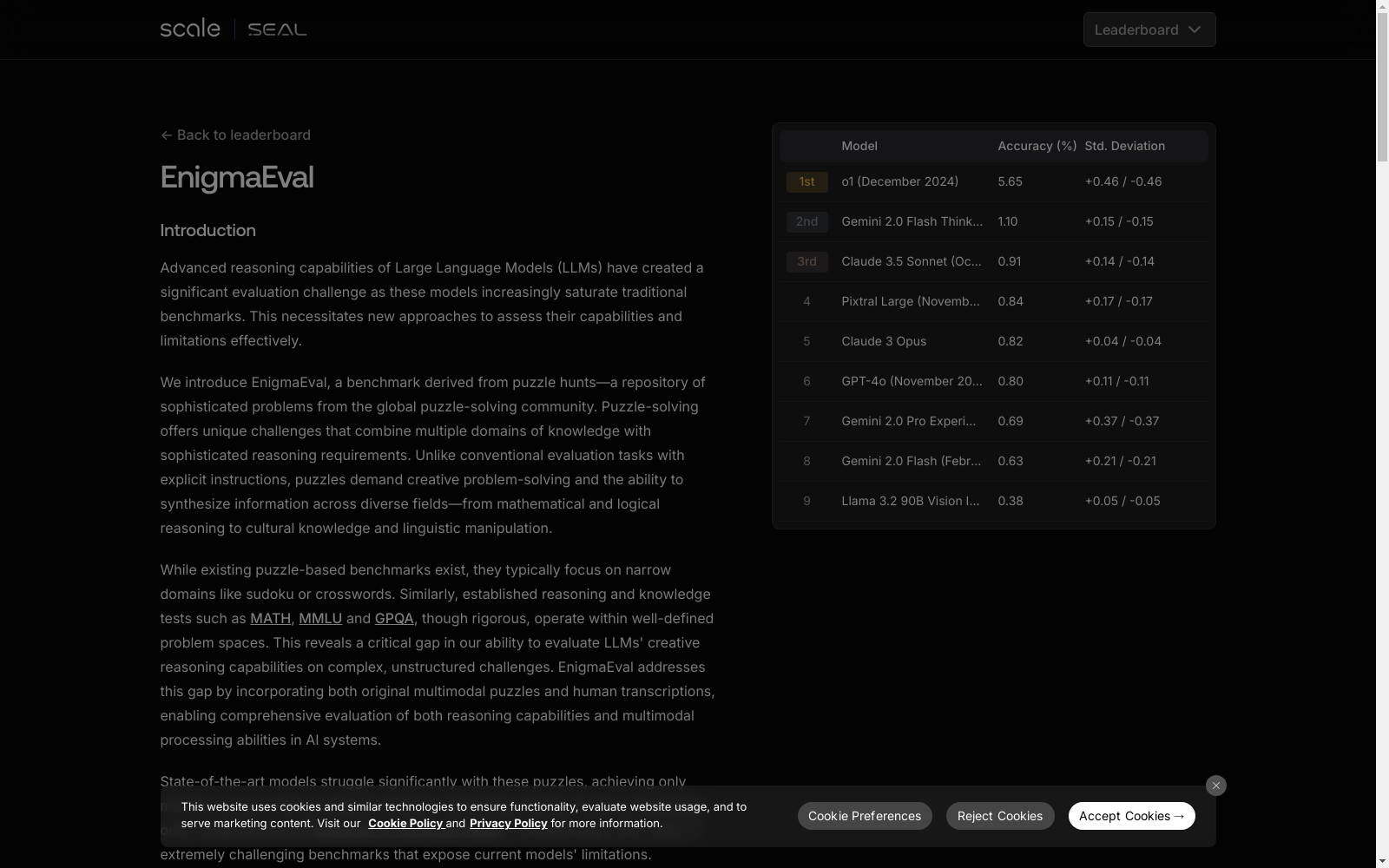
ENIGMAEVAL是一个由Scale AI发布的难题数据集,包含1184个来自拼图竞赛和事件的难题及其解决方案,旨在测试模型隐式知识综合和多步演绎推理的能力。这些难题通常需要技能娴熟的解题团队花费数小时至数天时间完成,具有明确且可验证的解决方案,便于高效评估。该数据集涵盖了文本和图像的多种非结构化格式,由全球拼图解题社区创建和分享的丰富、未充分开发的拼图库中选取。
ENIGMAEVAL is a challenging dataset released by Scale AI. It contains 1,184 puzzles and their corresponding solutions sourced from puzzle competitions and real-world incidents, and is designed to test a model's capacity for synthesizing implicit knowledge and performing multi-step deductive reasoning. These puzzles typically take skilled solving teams hours to days to complete, and feature clear and verifiable solutions that enable efficient evaluation. This dataset covers a variety of unstructured formats including text and images, and is curated from a rich, underutilized library of puzzles created and shared by the global puzzle-solving community.
提供机构:
Scale AI, Center for AI Safety, MIT
创建时间:
2025-02-13
搜集汇总
数据集介绍
构建方式
ENIGMAEVAL 数据集的构建方式是将来自各种谜题竞赛和事件的问题及其解决方案进行汇编,这些谜题挑战了模型执行隐式知识综合和多步演绎推理的能力。数据集包含了1184个不同复杂度的谜题,这些谜题通常需要熟练的解题团队花费数小时到数天的时间来完成。每个谜题都有明确且可验证的解决方案,以便进行高效的评估。数据集的构建过程中,首先从在线档案中抓取原始格式的谜题,然后由人工将每个谜题转录成标准化的文本-图像格式,以创建两种评估路径:一种使用原始未转录的谜题,另一种使用标准化格式。这种双重方法使得我们能够将模型的推理能力与其解析复杂文档的能力区分开来。
特点
ENIGMAEVAL 数据集的特点在于其多样性、复杂性和挑战性。它包含了多种格式的无结构化谜题,涵盖了文本和图像,这些谜题要求模型能够发现看似不相关的信息之间的隐藏联系,以揭示解决方案路径。数据集的谜题难度各异,从入门级到高级都有,通常需要多个非平凡步骤,并且中间答案可能只通过主题文本暗示。所有谜题都结合了文本和视觉元素,包括网格、图片、图表及其有意义的排列。ENIGMAEVAL 的一个显著特点是,即使是最先进的语言模型在这些谜题上的准确率也非常低,这揭示了模型在面对需要非结构化和横向推理的问题时的不足。
使用方法
ENIGMAEVAL 数据集的使用方法包括两种格式:原始的PNG格式的PDF图片(或网页谜题的全页截图),用于测试模型的端到端性能;以及结构化的文本-图像表示,用于针对多模态推理进行评估,同时减少干扰和预处理负载。每个谜题的解决方案通常是一个词或短语。评估模型时,通过将模型的答案与地面真实解决方案进行字符串匹配来衡量模型的性能。数据集还包括了为模型生成答案而设计的特定格式的系统提示模板,这些模板要求模型提供一个逐步解决方案和最终答案的标准格式。
背景与挑战
背景概述
ENIGMAEVAL数据集是一个旨在评估语言模型的高级推理能力的基准数据集。该数据集由Scale AI、Center for AI Safety和MIT的研究人员于2025年创建,旨在填补现有推理和知识基准的空白。ENIGMAEVAL数据集包含从拼图竞赛和活动中衍生出的问题和解决方案,这些问题挑战了模型执行隐式知识合成和多步演绎推理的能力。该数据集由1184个不同复杂性的拼图组成,通常需要团队花费数小时到数天的时间才能完成,具有明确、可验证的解决方案,便于高效评估。ENIGMAEVAL数据集的引入,不仅为语言模型的评估提供了新的挑战,也为相关领域的研究提供了新的方向。
当前挑战
ENIGMAEVAL数据集的挑战主要在于两个方面。首先,它所解决的领域问题是在多模态推理方面,特别是对于需要非结构化和横向推理的问题。现有的大语言模型在ENIGMAEVAL数据集上的表现极低,甚至低于其他困难基准,如Humanity’s Last Exam,揭示了模型在面对这类问题时存在的不足。其次,在构建过程中,ENIGMAEVAL数据集也面临了一些挑战。例如,如何从拼图竞赛和活动中筛选出适合的数据,如何将拼图转录成标准化的文本-图像格式,以及如何评估模型在处理原始PDF版本和转录版本时的推理能力。这些挑战对于ENIGMAEVAL数据集的成功构建和评估具有重要意义。
常用场景
经典使用场景
ENIGMAEVAL 数据集被广泛应用于评估大型语言模型(LLM)的推理能力和知识整合能力。它包含了来自谜题竞赛和活动的复杂问题,这些问题需要模型进行隐式知识综合和多步演绎推理。数据集提供了两种格式的谜题:原始的 PNG 格式和结构化的文本-图像表示,以便对模型的推理能力和文档解析能力进行区分评估。
衍生相关工作
ENIGMAEVAL 数据集的发布促进了相关领域的研究工作。它衍生了多个经典工作,例如对 LLM 在解决不同类型谜题时的表现进行分析,以及研究如何通过数据集的评估结果来改进模型的推理能力。此外,ENIGMAEVAL 还为其他类似的数据集提供了参考和启发,推动了多模态推理和知识整合领域的发展。
数据集最近研究
最新研究方向
ENIGMAEVAL数据集的引入,标志着对大型语言模型(LLMs)认知边界评价的新挑战。该数据集从谜题竞赛和活动中汲取灵感,旨在测试模型进行隐含知识综合和多步演绎推理的能力。ENIGMAEVAL的独特之处在于,它挑战模型发现看似不相关信息之间的隐藏联系,以揭示解决方案路径。该数据集包含1184个不同复杂性的谜题,每个谜题通常需要经验丰富的解谜者花费数小时甚至数天时间才能完成,且具有明确的、可验证的解决方案,这为高效评估提供了可能。尽管目前最先进的语言模型在其他推理和知识基准上取得了极高的准确率,但在ENIGMAEVAL上的表现却极低,甚至在某些难题上的准确率降到了0%,这揭示了模型在处理非结构化和横向推理问题时的不足。ENIGMAEVAL的引入,为评估LLMs在解决复杂、非结构化多模态挑战方面的能力提供了新的视角,也为未来LLMs的发展方向提供了重要的参考。
相关研究论文
- 1EnigmaEval: A Benchmark of Long Multimodal Reasoning ChallengesScale AI, Center for AI Safety, MIT · 2025年
以上内容由遇见数据集搜集并总结生成


