vcr-org/VCR-wiki-zh-easy-test
收藏Hugging Face2024-07-28 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/vcr-org/VCR-wiki-zh-easy-test
下载链接
链接失效反馈官方服务:
资源简介:
VCR-Wiki数据集是一个用于视觉字幕恢复(VCR)任务的数据集,旨在评估视觉语言模型在图像中恢复部分遮挡文本的能力。数据集包含图像、堆叠图像、仅包含文本的图像、字幕和交叉文本等字段。数据集的构建过程包括数据收集、初始过滤、N-gram选择、创建文本嵌入图像、图像拼接和第二轮过滤。数据集还提供了详细的评估方法和模型性能比较。
The VCR-Wiki dataset is designed for the Visual Caption Restoration (VCR) task, aiming to evaluate the capability of vision-language models to restore partially obscured texts within images. The dataset includes fields such as images, stacked images, only text images, captions, and crossed text. The dataset construction process involves data collection, initial filtering, N-gram selection, creating text embedded in images, image concatenation, and second-round filtering. The dataset also provides detailed evaluation methods and model performance comparisons.
提供机构:
vcr-org
原始信息汇总
VCR-Wiki 数据集概述
数据集描述
数据集名称
- VCR-Wiki
数据集任务
- 视觉字幕恢复(Visual Caption Restoration, VCR)
数据集语言
- 中文(zh)
数据集大小
- 下载大小:1031889519 字节
- 数据集大小:1032693834 字节
数据集分割
- 测试集(test):包含 5000 个样本,大小为 1032693834 字节
数据集特征
question_id:样本ID,类型为int64image:原始视觉图像,类型为imagecaption:未遮蔽的原始文本,类型为stringstacked_image:包含原始视觉图像和遮蔽文本嵌入图像的堆叠图像,类型为imageonly_it_image:遮蔽的文本嵌入图像,类型为imageonly_it_image_small:遮蔽的文本嵌入图像(小尺寸),类型为imagecrossed_text:当前实例中遮蔽的n-grams,类型为sequence
数据集构建
- 数据收集和初始过滤:原始数据来自 wikimedia/wit_base,过滤掉包含敏感内容的实例。
- N-gram选择:截断描述并使用spaCy进行分词,随机遮蔽5-grams。
- 创建文本嵌入图像:将描述嵌入图像并遮蔽选定的5-grams。
- 拼接图像:将文本嵌入图像与原始视觉图像拼接。
- 第二轮过滤:过滤掉没有遮蔽n-grams或高度超过900像素的实例。
数据集许可证
- Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)
数据集引用
bibtex @article{zhang2024vcr, title = {VCR: Visual Caption Restoration}, author = {Tianyu Zhang and Suyuchen Wang and Lu Li and Ge Zhang and Perouz Taslakian and Sai Rajeswar and Jie Fu and Bang Liu and Yoshua Bengio}, year = {2024}, journal = {arXiv preprint arXiv: 2406.06462} }
搜集汇总
数据集介绍
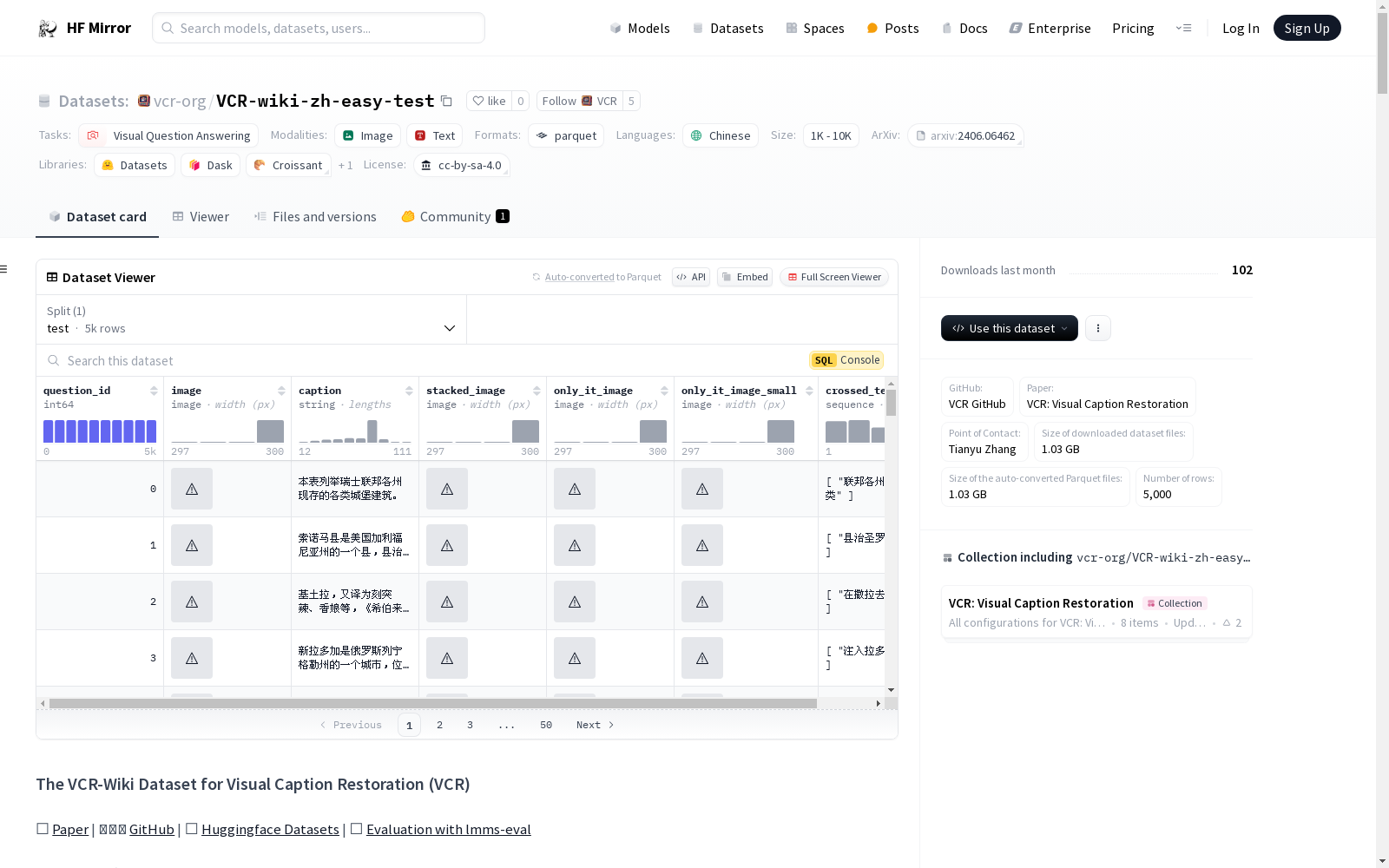
构建方式
VCR-Wiki-zh-easy-test数据集的构建过程始于从wikimedia/wit_base数据集中筛选出符合要求的内容,随后通过一系列精细的过滤步骤,剔除包含敏感内容(如NSFW和犯罪相关词汇)的实例,以减少AI模型的潜在风险和偏见。接着,数据集通过N-gram选择技术,对描述文本进行分词并随机遮蔽5-gram,确保遮蔽内容不涉及敏感信息。随后,生成嵌入文本的图像(TEI),并通过调整图像宽度和遮蔽矩形的大小来控制任务难度。最后,将TEI与原始视觉图像(VI)拼接,形成堆叠图像,并进行第二轮过滤,确保数据集的质量和适用性。
特点
VCR-Wiki-zh-easy-test数据集的主要特点在于其专注于视觉字幕恢复任务,通过图像与文本的结合,测试模型在部分文本被遮蔽的情况下恢复完整文本的能力。数据集提供了多种图像格式,包括原始图像、堆叠图像和仅包含遮蔽文本的图像,以及对应的未遮蔽文本和遮蔽的n-gram列表。此外,数据集通过调整遮蔽矩形的大小,提供了不同难度的任务版本,既包括适合母语者的简单版本,也包括对现有视觉语言模型极具挑战性的困难版本。
使用方法
VCR-Wiki-zh-easy-test数据集的使用方法多样,用户可以通过Hugging Face的datasets库直接加载数据集,并利用提供的评估脚本进行模型评估。对于开源模型,用户可以使用evaluation_pipeline.py脚本进行评估,指定模型ID和设备类型,并将评估结果保存为JSON文件。对于闭源模型,用户需使用API密钥进行评估,并通过closed_source_eval.py脚本进行结果分析。此外,用户还可以利用VLMEvalKit框架或lmms-eval框架进行模型评估,这些框架支持多种语言和难度设置,便于用户根据需求选择合适的评估方式。
背景与挑战
背景概述
视觉字幕恢复(VCR)任务旨在评估视觉语言模型在图像中恢复部分遮挡文本的能力。VCR-Wiki-zh-easy-test数据集由Tianyu Zhang等人于2024年创建,基于Wikimedia的图像字幕对,通过调整字幕可见性来控制任务难度。该数据集的核心研究问题是如何利用图像中的像素级提示来准确恢复被遮挡的文本,这一任务对当前的视觉语言模型提出了挑战,尤其是在处理中文等复杂语言时。VCR-Wiki数据集的构建不仅推动了视觉语言模型的发展,还为跨模态理解提供了新的研究方向。
当前挑战
VCR-Wiki-zh-easy-test数据集的主要挑战在于如何从图像中提取微小的文本线索并准确恢复被遮挡的文本。构建过程中,研究人员面临的主要挑战包括:1)如何生成具有不同难度级别的合成图像,以确保任务对人类而言相对简单,但对模型而言具有挑战性;2)如何有效过滤敏感内容,确保数据集的伦理使用。此外,当前的视觉语言模型在中文恢复任务上的表现远低于人类水平,表明该领域仍存在显著的技术瓶颈。
常用场景
经典使用场景
VCR-org/VCR-wiki-zh-easy-test数据集的经典使用场景主要集中在视觉字幕恢复任务中,旨在评估视觉-语言模型在图像中恢复被遮挡文本的能力。通过提供包含部分遮挡文本的图像,模型需要结合图像中的视觉线索和上下文信息,准确还原被遮挡的文本内容。这一任务不仅测试了模型对图像细节的感知能力,还考察了其对语言上下文的理解与推理能力。
实际应用
在实际应用中,VCR-org/VCR-wiki-zh-easy-test数据集的应用场景广泛,包括但不限于图像修复、文档扫描、自动驾驶中的路标识别等。在这些场景中,图像中的文本信息往往被遮挡或模糊,通过该数据集训练的模型能够有效恢复这些信息,提升系统的整体性能。此外,该数据集还可用于开发更智能的图像处理工具,帮助用户在复杂环境中快速获取准确的文本信息。
衍生相关工作
基于VCR-org/VCR-wiki-zh-easy-test数据集,研究者们开发了多种相关的经典工作,包括改进的视觉-语言模型、多模态学习算法以及跨语言的文本恢复技术。这些工作不仅提升了模型在视觉字幕恢复任务中的表现,还推动了多模态数据处理技术的发展。例如,一些研究通过引入更复杂的图像处理技术,增强了模型对遮挡文本的识别能力;另一些研究则探索了跨语言的文本恢复方法,使得模型能够在不同语言环境下表现出色。
以上内容由遇见数据集搜集并总结生成


