persuasion-gemini-1.5-pro
收藏Hugging Face2025-08-08 更新2025-08-09 收录
下载链接:
https://huggingface.co/datasets/eoplumbum/persuasion-gemini-1.5-pro
下载链接
链接失效反馈官方服务:
资源简介:
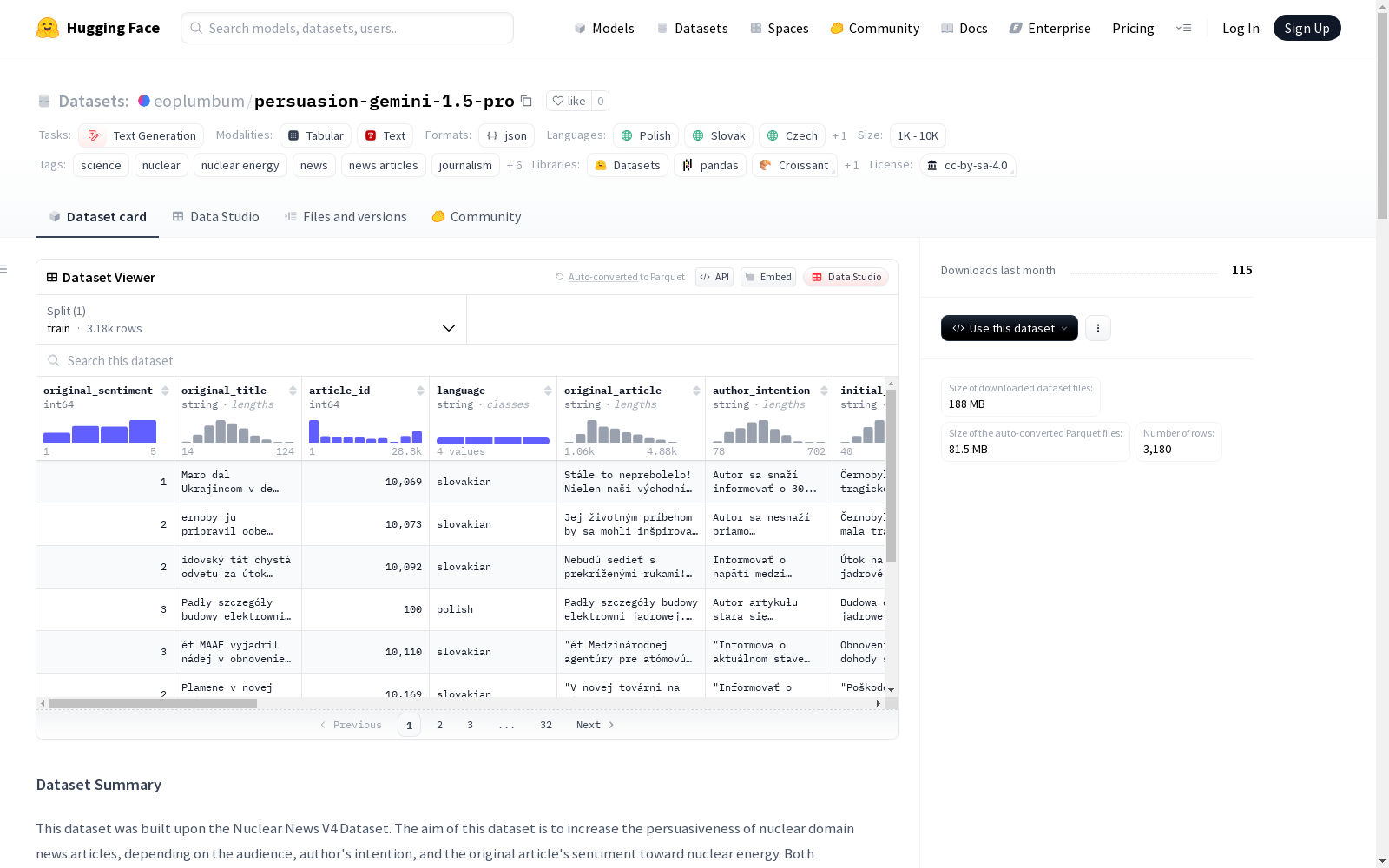
该数据集基于核新闻V4数据集构建,旨在根据受众、作者的意图以及原文对核能的态度,提高核领域新闻文章的说服力。数据集通过多智能体系统在对话环境中进行构造,并经过五轮递归改进。它包含了原始文章的情感倾向、标题、ID、语言、原文、作者意图、初始核能声明、最终核能声明、是否经过争议增强、受众类型、对话轮次、最终改进的文章、最终协议分数、初始协议分数、提取的语言学变化、提取的领域变化、解决的缺失信息、解决的改进建议、累积的缺失信息和累积的改进建议等字段。
创建时间:
2025-08-08
搜集汇总
数据集介绍
构建方式
在核能新闻传播研究领域,该数据集基于Nuclear News V4数据集构建,采用多智能体对话框架与递归优化机制。通过Gemini 1.5 Pro模型驱动的理论心智代理和争议增强代理,对原始新闻进行五轮迭代优化,动态生成适应不同读者群体和作者意图的 persuasive 内容。构建过程涵盖情感标注、意图提取、争议强化等环节,最终形成包含多维度交互记录的结构化数据。
特点
数据集涵盖中东欧四国语言(波兰语、斯洛伐克语、捷克语、匈牙利语)的核能领域新闻,包含3180篇经过深度优化的文本。其核心特征体现在三方面:一是通过初始与最终协议分数的量化对比,揭示说服策略的有效性;二是记录每轮对话中的读者反馈与改进策略,形成动态优化轨迹;三是包含情感分布、读者类型(专家/普通受众)、争议增强标记等多维元数据,为跨语言说服机制研究提供立体化分析基础。
使用方法
研究者可通过Hugging Face数据集库直接加载该资源,利用Python接口快速访问结构化字段。典型分析路径包括:追踪协议分数的变化轨迹以评估说服效果;对比不同读者类型下的策略使用模式;结合语言特征与领域知识变化进行跨文化传播研究。需注意自动生成字段可能存在冗余,建议根据研究目标对语言策略和领域变更字段进行过滤,以确保分析结果的精确度。
背景与挑战
背景概述
在数字媒体时代,新闻传播的效力日益依赖于内容的说服力,特别是在核能这类具有高度专业性和争议性的话题上。persuasion-gemini-1.5-pro数据集由研究团队基于Nuclear News V4 Dataset构建,旨在探索如何根据受众类型、作者意图和原始文章情感来增强核能领域新闻的说服力。该数据集采用多智能体对话系统和五轮递归改进机制,依托Gemini 1.5 Pro模型生成,涵盖了波兰语、斯洛伐克语、捷克语和匈牙利语四种中东欧语言,共包含3180篇新闻文章,其创建反映了计算传播学与自然语言处理交叉领域的前沿进展。
当前挑战
该数据集核心挑战在于解决核能新闻领域的内容适应性问题,即如何动态调整文章以提升不同受众(专家与普通读者)的认同度,这涉及情感分析、意图提取和争议增强等复杂任务。构建过程中的挑战主要包括:多轮对话机制的稳定性控制,以确保反馈与改进的逻辑一致性;多语言处理的均匀性,尽管语言分布平衡,但核能事件频率的不均衡可能导致内容偏差;以及自动化标注的可靠性,由于仅依赖大语言模型生成,未基于传播理论框架,部分提取策略可能存在冗余或噪声,需进一步人工验证与过滤。
常用场景
经典使用场景
在核能传播研究领域,该数据集为分析说服策略的动态演变提供了独特视角。研究者通过多轮对话机制追踪专家与普通受众对核新闻的反馈差异,观察语言调整如何影响受众认同度变化。这种设计特别适合探究不同文化背景(维谢格拉德集团四国)下核能信息的接受度差异,为跨文化传播研究提供实证基础。
解决学术问题
该数据集有效解决了核能传播中受众分化的量化难题,通过协议分数轨迹分析揭示说服策略的有效性。它使研究者能系统性考察初始情感倾向、作者意图与争议强化之间的相互作用,为构建核能传播理论模型提供数据支撑。这种多维标注体系突破了传统内容分析的局限性,为计算传播学提供了新范式。
衍生相关工作
该数据集催生了多项关于LLM辅助传播优化的研究,包括基于协议轨迹变化的策略有效性分析、多语言说服模式对比研究等。相关工作进一步拓展到能源政策传播、科学新闻写作辅助系统开发等领域,为自动化内容优化提供了重要基准。这些研究显著推动了计算传播学与能源政策的跨学科融合。
以上内容由遇见数据集搜集并总结生成


