Hungarian Preverb Corpus
收藏github2022-01-25 更新2024-05-31 收录
下载链接:
https://github.com/ril-lexknowrep/hungarian-preverb-corpus
下载链接
链接失效反馈官方服务:
资源简介:
一个手动标注了匈牙利语动词与前缀连接关系的金标准语料库。包含四个文件,分别用于验证和测试,其中`difficult`数据集特别设计,排除了最常见和最易处理的模式,以测试更复杂的连接情况。
A gold-standard corpus manually annotated for the connection relationships between Hungarian verbs and prefixes. It includes four files designated for validation and testing purposes, with the `difficult` dataset specifically designed to exclude the most common and easily processed patterns, thereby testing more complex connection scenarios.
创建时间:
2022-01-10
原始信息汇总
数据集概述
数据集名称
Hungarian Preverb Corpus
数据集描述
该数据集是一个手动标注的匈牙利语动词与前缀连接的黄金标准语料库。
数据集组成
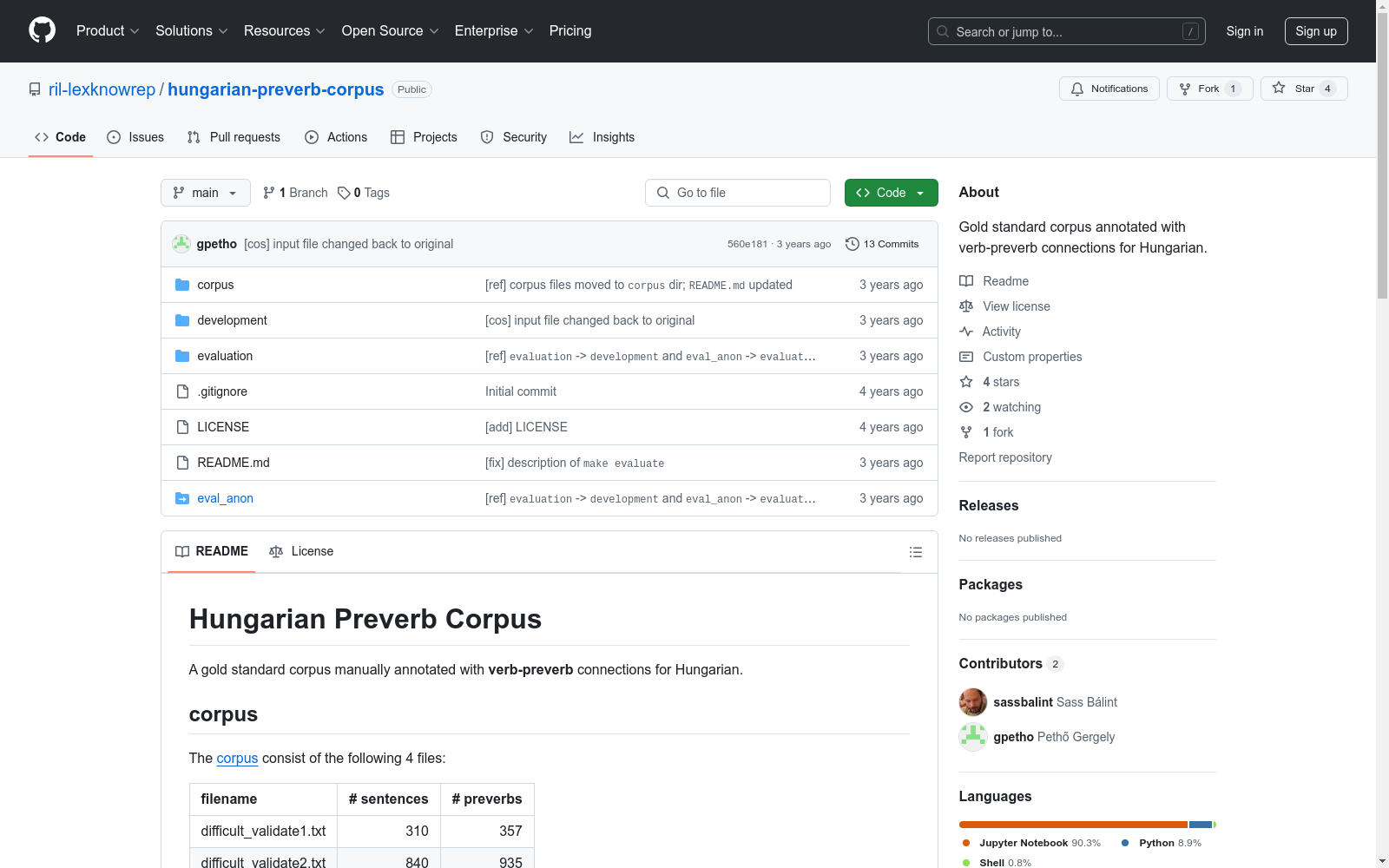
数据集包含以下四个文件:
| 文件名 | 句子数量 | 前缀数量 |
|---|---|---|
| difficult_validate1.txt | 310 | 357 |
| difficult_validate2.txt | 840 | 935 |
| difficult_test.txt | 327 | 376 |
| general_test.txt | 503 | 500 |
数据集特点
general数据集中的前缀分布与匈牙利语普通文本中的分布相同。difficult数据集是特别设计的,排除了最常见和最易处理的模式。validate用于开发/验证,test用于测试。
标注指南
- 前缀通过后缀反斜杠和数字ID标记:
meg1。 - 前缀分离的单词通过管道和相同ID标记:
főzve|1。 - 同一行中不同的动词-前缀对必须使用不同的ID。
- 不属于任何单词的前缀(如省略号等)标记为零ID:
"Hazakísérhetlek?" "Meg� hát."。 difficult数据集中,动词直接跟随其前缀的情况未标注。general数据集中,所有模式均被标注。
评估
数据集用于评估emPreverb工具,该工具基于difficult示例开发,并在difficult和general数据上进行测试。
引用信息
若使用该数据集,请引用以下论文: Pethő, Gergely and Sass, Bálint and Kalivoda, Ágnes and Simon, László and Lipp, Veronika: Igekötő-kapcsolás. In: MSZNY 2022.
搜集汇总
数据集介绍
构建方式
匈牙利语前缀动词语料库(Hungarian Preverb Corpus)的构建基于人工标注的动词与前缀之间的连接关系。语料库包含四个文件,分别为`difficult_validate1.txt`、`difficult_validate2.txt`、`difficult_test.txt`和`general_test.txt`。其中,`difficult`数据集特意排除了最常见的动词直接跟随前缀的模式,以专注于更具挑战性的语言现象,而`general`数据集则保留了自然文本中的前缀分布。标注过程中,前缀和动词通过唯一的ID号进行关联,确保每个前缀与其对应的动词能够准确匹配。
特点
该语料库的特点在于其精细的标注体系和多样化的数据集设计。`difficult`数据集通过排除简单的前缀-动词组合,专注于复杂的前缀分离现象,为研究提供了更具挑战性的语言样本。`general`数据集则反映了匈牙利语中前缀的自然分布,适用于更广泛的语言学研究。此外,语料库中的每个前缀和动词都通过唯一的ID号进行标注,确保了数据的一致性和可追溯性。这种设计使得该语料库不仅适用于前缀动词连接的研究,还可用于开发相关的自然语言处理工具。
使用方法
该语料库的使用方法主要包括数据集的加载与评估。用户可以通过克隆`emPreverb`工具库并运行`make evaluate`命令,自动下载该语料库并进行评估。评估结果将生成在`general_test_results.txt`和`difficult_test_results.txt`文件中,与相关论文中的结果一致。此外,用户还可以通过Jupyter Notebook打开`evaluate.ipynb`文件,进一步探索语料库的标注细节和评估过程。使用该语料库时,建议引用相关论文以尊重作者的研究成果。
背景与挑战
背景概述
匈牙利语前缀动词语料库(Hungarian Preverb Corpus)是一个专门针对匈牙利语中动词与前缀连接关系的手动标注黄金标准语料库。该语料库由匈牙利的研究团队开发,主要研究人员包括Gergely Pethő、Bálint Sass、Ágnes Kalivoda、László Simon和Veronika Lipp。该语料库的创建旨在解决匈牙利语中动词与前缀连接的复杂性问题,特别是在自然语言处理任务中,如句法分析和语义理解。语料库分为两个主要部分:`general`数据集和`difficult`数据集,前者反映了匈牙利语文本中前缀动词的常见分布,后者则专门剔除了最常见的简单模式,以挑战更复杂的连接情况。该语料库的发布为匈牙利语的自然语言处理研究提供了重要的资源支持。
当前挑战
匈牙利语前缀动词语料库在构建和应用过程中面临多重挑战。首先,匈牙利语中动词与前缀的连接模式复杂多样,尤其是在`difficult`数据集中,剔除了最常见的简单模式后,模型需要处理更为复杂和罕见的连接情况,这对模型的泛化能力提出了更高要求。其次,语料库的标注过程需要高度精确,以确保每个前缀动词与其对应动词的正确连接,这对标注人员的语言学和计算语言学知识提出了较高要求。此外,语料库的评估依赖于外部工具(如`e-magyar`)的形态和词性标注,若工具标注错误,可能导致语料库中的某些标注被误删,进而影响模型的性能评估。这些挑战不仅体现在数据构建过程中,也直接影响了基于该语料库的自然语言处理任务的性能提升。
常用场景
经典使用场景
Hungarian Preverb Corpus 数据集在自然语言处理领域中被广泛用于匈牙利语动词与前缀(preverb)连接的研究。该数据集通过手动标注的动词与前缀连接,为研究者提供了一个高质量的标准语料库,特别适用于开发和分析匈牙利语中动词与前缀的复杂关系。其经典使用场景包括训练和评估匈牙利语动词与前缀连接的自动化工具,如 `emPreverb` 工具的开发与测试。
解决学术问题
该数据集解决了匈牙利语中动词与前缀连接的自动识别问题。匈牙利语中的动词与前缀关系复杂,传统方法难以准确处理。通过提供手动标注的语料,该数据集为研究者提供了一个可靠的基准,帮助开发出能够自动识别和连接动词与前缀的算法。这不仅提升了匈牙利语自然语言处理的准确性,还为其他语言中类似问题的研究提供了参考。
衍生相关工作
基于 Hungarian Preverb Corpus 数据集,研究者开发了 `emPreverb` 工具,该工具能够自动连接匈牙利语中的动词与前缀。这一工具的开发不仅验证了数据集的实用性,还为后续研究提供了基础。此外,该数据集还启发了其他语言中类似问题的研究,推动了多语言自然语言处理技术的发展。相关研究论文如 Pethő 等人(2022)的工作,进一步扩展了该数据集在学术界的应用和影响力。
以上内容由遇见数据集搜集并总结生成


