L2-ARCTIC corpus
收藏arXiv2025-09-30 收录
下载链接:
https://ttslr.github.io/Ai-TTS
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了非母语者带有口音的英语录音,并附有音素级别的对齐注释。此外,数据集中还包含了脚本和音素级别的对齐注释,采样率为44.10千赫兹,以16位编码。该数据集规模达到26小时,其任务是用以训练人工智能语音合成模型。
This dataset contains accented English speech recordings from non-native speakers, paired with orthographic transcripts and phoneme-level alignment annotations. The audio files have a sampling rate of 44.10 kHz and are encoded in 16-bit format. The total duration of the dataset is 26 hours, and it is intended for training artificial intelligence speech synthesis models.
提供机构:
L2-ARCTIC
搜集汇总
数据集介绍
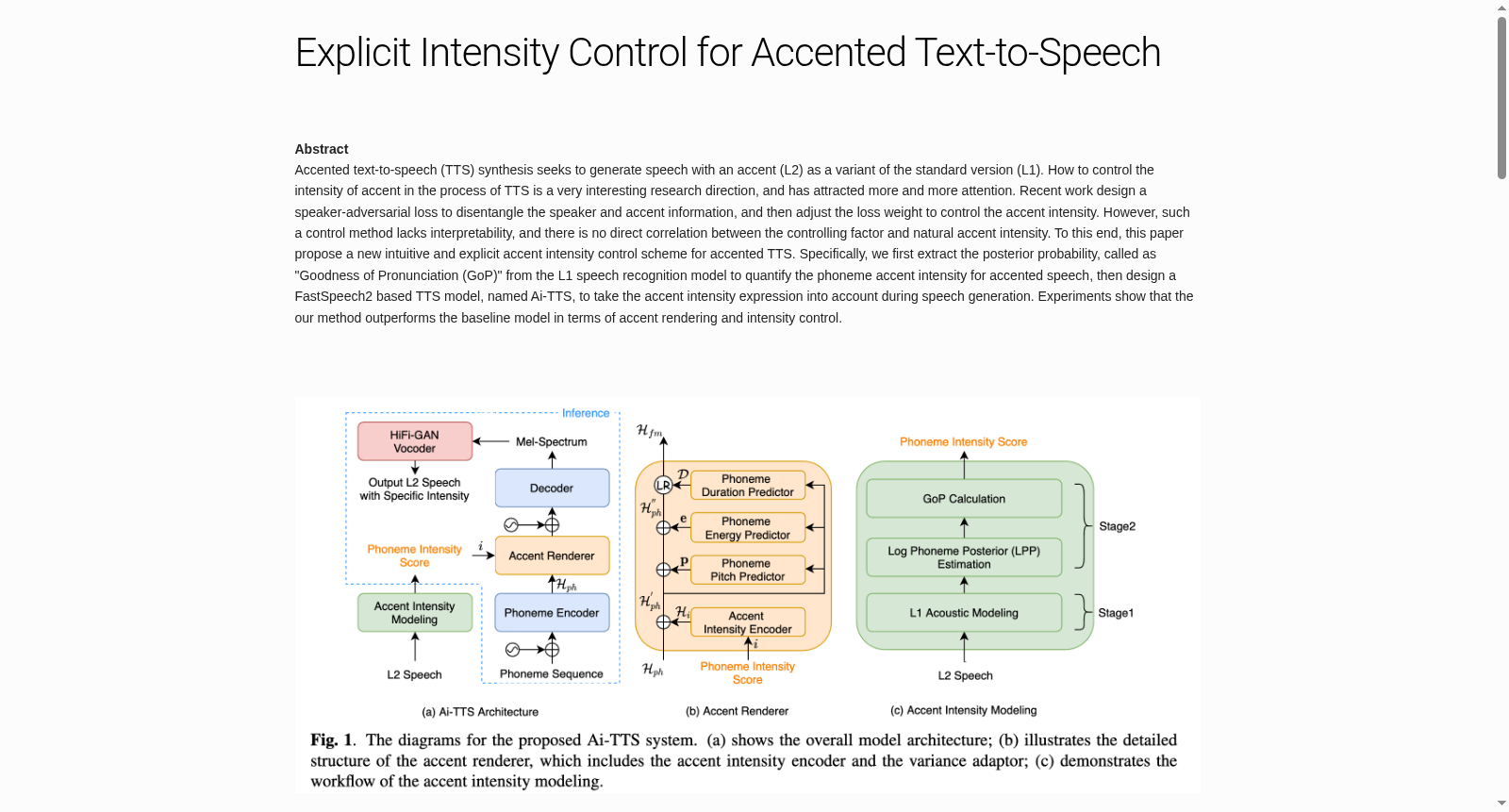
背景与挑战
背景概述
L2-ARCTIC corpus是一个专注于口音文本到语音合成的研究数据集,提供了明确的强度控制方法,用于调整生成语音中的口音强度。研究提出了一种基于FastSpeech2的TTS模型,通过量化音素口音强度来实现对口音强度的直观和显式控制。
以上内容由遇见数据集搜集并总结生成


