MATHREAL
收藏arXiv2025-08-08 更新2025-08-12 收录
下载链接:
https://huggingface.co/datasets/junfeng0288/MathReal
下载链接
链接失效反馈官方服务:
资源简介:
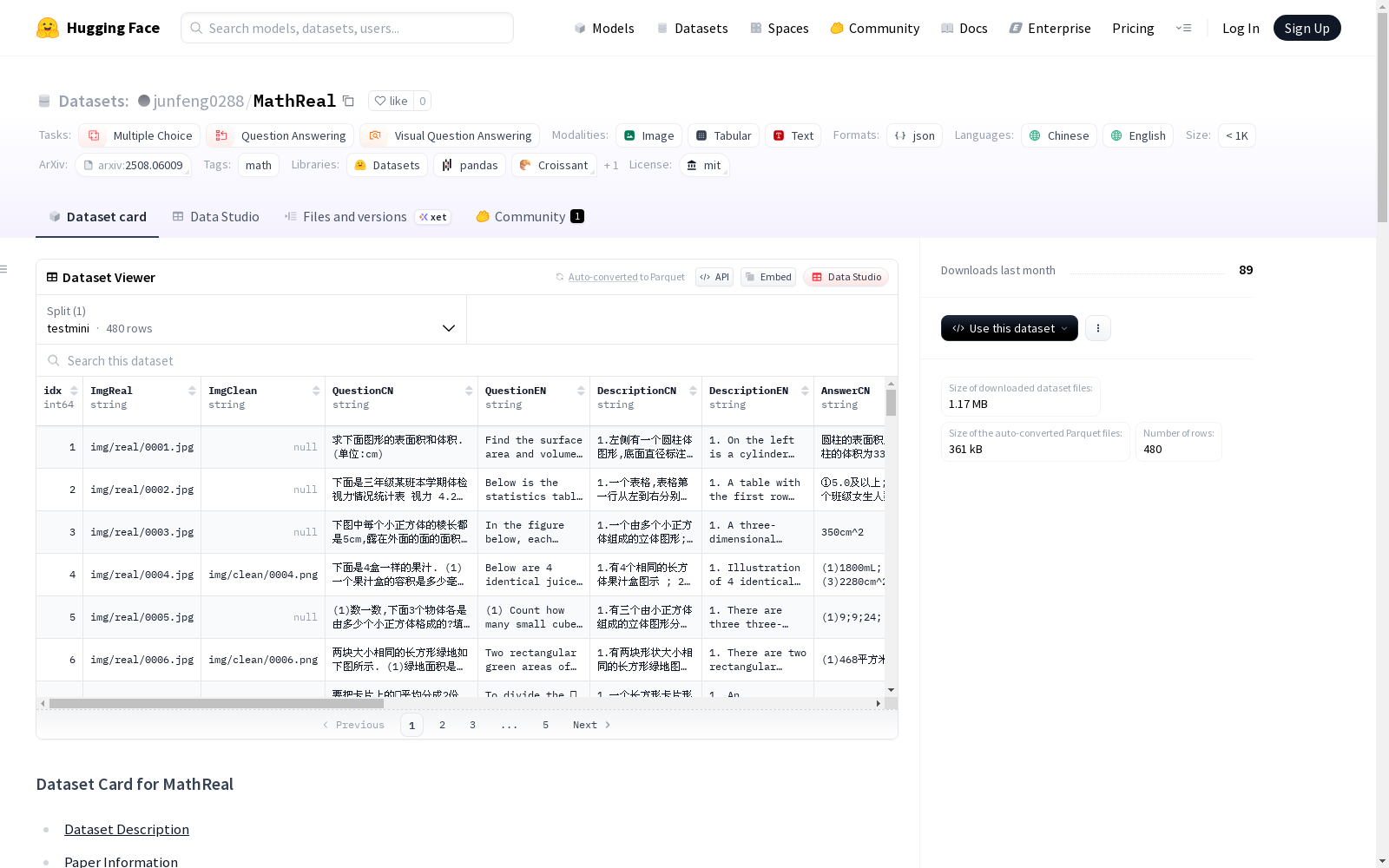
MATHREAL是一个精心策划的数据集,包含2000个通过手持移动设备在真实场景中拍摄的数学问题图像。每个问题都是一个图像,包含问题文本和视觉元素。数据集系统地分类真实图像为三个主要类别:图像质量退化、视角变化和无关内容干扰,这些类别进一步细分为14个子类别。MATHREAL涵盖了五个核心知识和能力类别,包括三种问题类型,并分为三个难度级别。为了全面评估最先进的MLLMs在现实世界场景中的多模态数学推理能力,我们设计了六个实验设置,以便系统地分析其性能。通过广泛的实验,我们发现现有MLLMs在现实的教育环境中解决问题的关键能力受到显著挑战。基于此,我们对其性能和错误模式进行了彻底的分析,提供了对其识别、理解和推理能力的见解,并概述了未来改进的方向。数据集包括三种类型的问题:选择题、填空题和构造性回答题。在学术阶段方面,问题分布在三个教育阶段:小学、中学和高中,确保涵盖了K-12范围内的内容。此外,745个问题仅由真实图像伴随,而1255个问题既有真实图像也有干净图像。数据集还包括一个包含480个问题的testmini子集。详细的统计数据,包括问题类型和视觉内容类别,总结在表1中。数据收集过程包括从大规模用户上传的库中采样150万个拍摄的数学问题,并应用两阶段过滤过程来确保质量和相关性。数据标注过程包括三个完全人工阶段,最终确保最终数据集反映了多样化的现实世界条件,同时保持了用于评估多模态数学推理的高语义和结构质量。
MATHREAL is a carefully curated dataset containing 2000 images of mathematical problems captured in real-world scenarios using handheld mobile devices. Each problem is presented as an image that includes both the problem text and visual elements. The dataset systematically classifies real-world images into three main categories: image quality degradation, viewpoint variation, and irrelevant content interference, which are further subdivided into 14 subcategories. MATHREAL covers five core knowledge and competency categories, includes three types of problems, and is divided into three difficulty levels. To comprehensively evaluate the multimodal mathematical reasoning capabilities of state-of-the-art MLLMs in real-world scenarios, we designed six experimental settings to systematically analyze their performance. Through extensive experiments, we found that the core problem-solving abilities of existing MLLMs face significant challenges in realistic educational environments. Based on this, we conducted a thorough analysis of their performance and error patterns, provided insights into their recognition, understanding, and reasoning capabilities, and outlined directions for future improvements. The dataset includes three types of problems: multiple-choice questions, fill-in-the-blank questions, and constructive response questions. In terms of academic stages, the problems are distributed across three educational levels: primary school, middle school, and high school, ensuring coverage of K-12 content. Additionally, 745 problems are accompanied only by real images, while 1255 problems have both real images and clean images. The dataset also includes a testmini subset containing 480 problems. Detailed statistics, including problem types and visual content categories, are summarized in Table 1. The data collection process involved sampling 1.5 million captured mathematical problems from a large-scale user-uploaded repository, and applying a two-stage filtering process to ensure quality and relevance. The data annotation process included three fully manual stages, ultimately ensuring that the final dataset reflects diverse real-world conditions while maintaining high semantic and structural quality for evaluating multimodal mathematical reasoning.
提供机构:
Baidu Inc., Nanyang Technological University, Xiaopeng Motors, Gaoling School of Artificial Intelligence, Renmin University of China, Beihang University
创建时间:
2025-08-08
原始信息汇总
MathReal数据集概述
基本信息
- 许可证: MIT
- 任务类别: 多项选择、问答、视觉问答
- 语言: 中文、英文
- 模态: 文本、图像
- 标签: 数学
- 规模: 1K<n<10K
- 配置:
- 默认配置
- 数据文件: testmini.json
- 分割: testmini
- 默认配置
数据集描述
MathReal数据集旨在评估**多模态大语言模型(MLLMs)**在真实世界K-12数学问题上的表现。包含2000个高质量数学问题,每个问题以真实教育场景中的图像形式呈现。问题类型包括多项选择、填空和构建回答,并按难度级别和知识领域分类。
数据集结构
- 图像目录:
img/clean/: 175张PNG格式的清晰图像img/real/: 480张JPG格式的真实图像
图像类别
- 真实图像: 480张原始图像,代表真实教育场景中的数学问题
- 清晰图像: 175张处理后的图像,适合模型评估
论文信息
- 代码: https://github.com/YourUsername/MathReal
- 项目: https://mathreal-project.github.io/
- 可视化: https://mathreal-project.github.io/#visualization
- 排行榜: https://mathreal-project.github.io/#leaderboard
- 论文: https://arxiv.org/abs/2508.06009
数据集示例
- 平面几何(PG): 几何形状和计算问题
- 立体几何(SG): 3D形状和体积计算问题
- 逻辑推理(LR): 需要数学推理的问题
- 函数图(FG): 函数图分析和解释问题
- 统计图表(SC): 统计图表分析和数据解释问题
排行榜
展示多模态大语言模型在MathReal数据集上的性能比较。
引用
bash @misc{feng2025mathrealrealrealscene, title={MathReal: We Keep It Real! A Real Scene Benchmark for Evaluating Math Reasoning in Multimodal Large Language Models}, author={Jun Feng and Zixin Wang and Zhentao Zhang and Yue Guo and Zhihan Zhou and Xiuyi Chen and Zhenyang Li and Dawei Yin}, year={2025}, eprint={2508.06009}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2508.06009}, }
搜集汇总
数据集介绍
构建方式
MATHREAL数据集通过精心设计的数据收集与标注流程构建而成,涵盖2000个真实场景下的K-12数学问题。数据采集阶段从150万用户上传的数学问题库中筛选,经过两轮模型过滤确保样本质量,最终由GPT-4o等先进模型确认问题完整性和图形相关性。标注过程采用三阶段人工审核机制,包括问题筛选、图像条件分类(14种干扰子类型)和元数据标注(题型、难度层级等),每个问题均通过双专家验证并补充标准答案与视觉描述,形成兼具教育实用性和研究严谨性的基准数据集。
特点
该数据集创新性地模拟真实教育场景中的三大挑战:图像质量退化(模糊、阴影等)、视角变化(旋转、畸变等)和内容干扰(手写批注、背面透印等),涵盖选择题、填空题和建构题三种题型,并按小学、初中、高中划分难度层级。其核心特色在于视觉唯一输入机制——所有解题信息均嵌入单张移动设备拍摄的图像,迫使模型先完成视觉信息提取再进行数学推理,与现有基于清洁文本或多模态分离输入的基准形成鲜明对比。数据集还提供745道纯真实图像题和1255道附带清洁图像的对照题,支持感知-推理能力的解耦研究。
使用方法
使用MATHREAL时可选择六种实验设置:纯图像输入(I)、统一端到端推理(IUER)及四种增强输入模式(结合模型生成或人工标注的文本/图形描述)。评估采用严格准确率(Accstr)和宽松准确率(Acc)双指标,前者要求所有子问题完全正确,后者允许部分正确。建议先通过testmini子集(480题)进行快速验证,再在完整测试集(1520题)上评估。典型流程包括:图像预处理(可选)、模型推理、答案提取(支持boxed标记或末端提取)以及基于数学等价性的自动评分,特别需要注意单位一致性和多步推理的完整性验证。
背景与挑战
背景概述
MATHREAL是2025年由百度、南洋理工大学等机构的研究人员共同推出的一个多模态大型语言模型(MLLMs)数学推理评估基准数据集。该数据集包含2000个真实场景下通过移动设备拍摄的K-12数学问题图像,涵盖了图像质量退化、视角变化和无关内容干扰三大类共14种子类型的视觉噪声。数据集覆盖几何、代数、统计、逻辑推理和函数图像五大知识领域,包含选择题、填空题和建构回答题三种题型,并按难度分为三个等级。MATHREAL的创建填补了现有数学推理基准主要使用清洁或处理后图像的空白,为评估MLLMs在真实教育场景中的表现提供了重要工具。
当前挑战
MATHREAL面临的核心挑战包括:1) 领域问题挑战:现有MLLMs在真实场景的数学图像理解上表现不佳,最佳模型准确率仅53.9%,远低于清洁图像下的表现,凸显视觉感知与符号推理的结合难题;2) 构建过程挑战:数据收集需处理手持设备拍摄导致的复杂视觉噪声(如模糊、阴影、透视畸变等),标注需专家团队对图像条件、问题内容和解题要素进行多阶段验证,且需保持与真实教育场景的问题分布一致性。此外,数据集中视觉唯一输入的特性要求模型具备从单一噪声图像中同时提取文本和视觉信息的能力,这对标注规范和模型评估提出了更高要求。
常用场景
经典使用场景
MATHREAL数据集作为首个基于真实K-12教育场景构建的多模态数学推理基准,其经典使用场景聚焦于评估多模态大语言模型(MLLMs)在复杂现实条件下的表现。该数据集通过2000道由移动设备拍摄的数学题目图像,系统模拟了图像质量退化、视角变化和无关内容干扰三大类共14种子干扰场景,覆盖几何、代数、统计等五大知识领域。研究者可通过六种实验设置(如纯图像输入、图像+人工标注文本等)分层检验模型在视觉感知与符号推理的耦合能力,特别适用于验证模型对模糊文本、倾斜几何图形及手写批注等教育场景典型噪声的鲁棒性。
解决学术问题
MATHREAL有效解决了现有数学评测基准过度依赖清洁数据的局限性,填补了真实教育场景下多模态推理评估的空白。其实验结果表明,当前最先进模型Doubao-1.5-thinking-vision-pro在严格准确率(Accstr)下仅达41%,揭示了MLLMs在联合处理视觉退化与数学推理时的显著缺陷。该数据集通过细粒度错误分析(如OCR错误占16%、图形感知错误占25%)为学界提供了模型改进的明确方向,推动了面向教育应用的噪声不变性表征学习、跨模态对齐等关键技术的发展。
衍生相关工作
MATHREAL的发布催生了一系列围绕教育场景鲁棒性提升的研究。基于其构建的视觉-符号联合训练框架VL-Rethinker在噪声图像推理任务中表现优异(Accstr提升12%),衍生出专注数学图形理解的MathVerse等后续工作。数据集划分的testmini子集已成为轻量化模型开发的通用基准,而标注的14种干扰类型启发了如DynaMath等动态数据增强方法。此外,其揭示的模型在统计图表(SC类)与逻辑推理(LR类)任务间高达29%的性能差异,推动了领域自适应推理技术的创新。
以上内容由遇见数据集搜集并总结生成


