REPOCOD
收藏REPOCOD 数据集概述
数据集信息
- 许可证: BSD-3-Clause-Clear
- 特征:
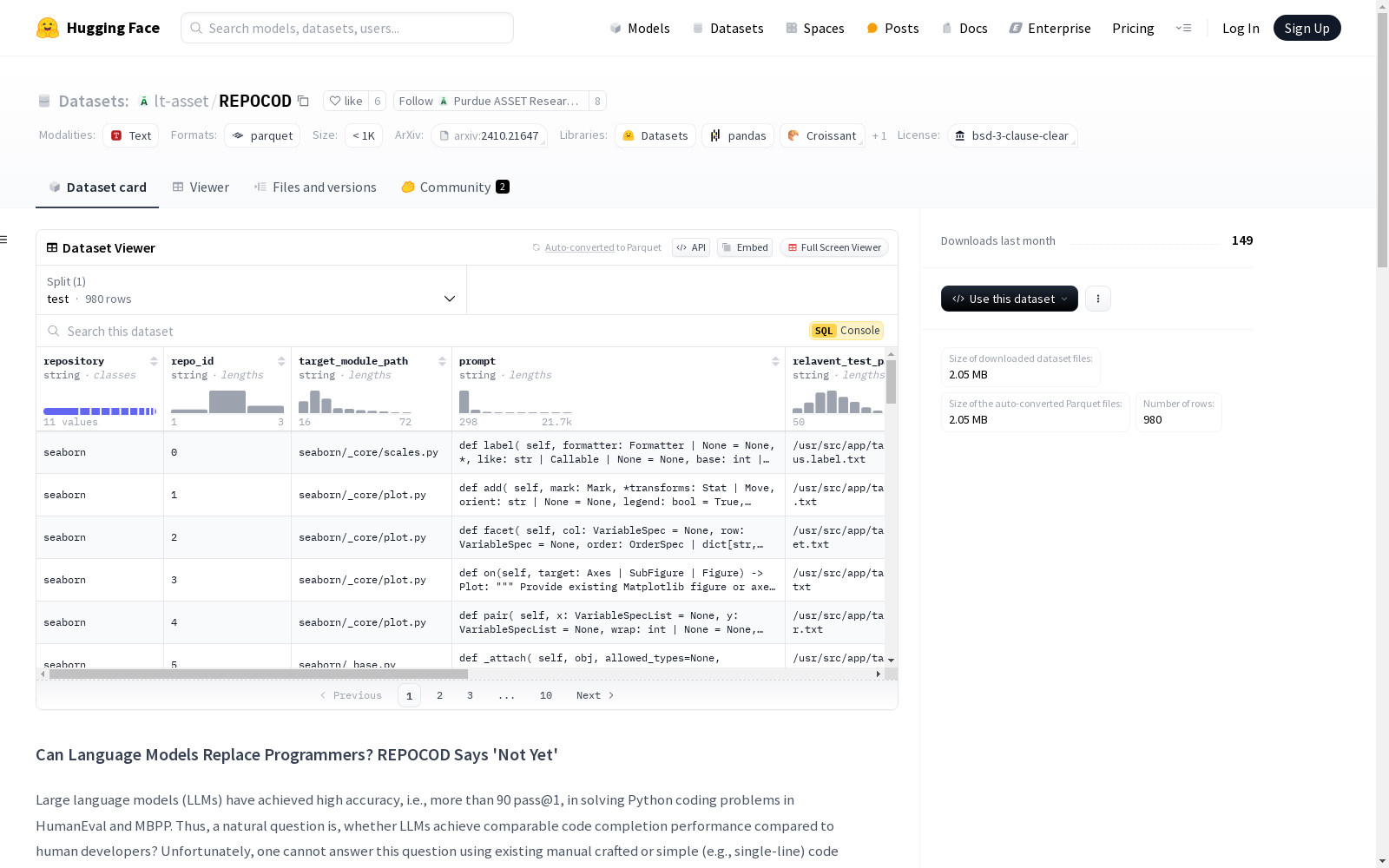
repository: 字符串,当前样本的源仓库repo_id: 字符串,当前样本在对应源仓库中的唯一索引target_module_path: 字符串,包含当前样本的文件路径,相对于源仓库的根目录prompt: 字符串,开发者提供的函数签名和文档字符串relavent_test_path: 字符串,相关测试用例的路径full_function: 字符串,当前样本的规范解决方案function_name: 字符串,目标函数(当前样本)的名称
- 拆分:
train: 训练集,包含980个样本,大小为5410189字节
- 下载大小: 2045590字节
- 数据集大小: 5410189字节
- 配置:
default: 默认配置,数据文件路径为data/train-*
数据集描述
REPOCOD是一个代码生成基准,包含从11个流行的真实世界项目中收集的980个问题,其中超过58%的问题需要文件级或仓库级的上下文信息。REPOCOD的平均规范解决方案长度(331.6个token)和平均圈复杂度(9.00)均高于现有基准。每个任务在REPOCOD中平均包含313.5个开发者编写的测试用例,以更好地评估正确性。在十个大型语言模型(LLMs)的评估中,没有任何模型在REPOCOD上的pass@1超过30,这表明构建更强大的LLMs以帮助开发者在真实世界软件开发中的必要性。
使用示例
python from datasets import load_dataset
data = load_dataset(lt-asset/REPOCOD) print(data)
数据字段
repository: 当前样本的源仓库repo_id: 当前样本在对应源仓库中的唯一索引target_module_path: 包含当前样本的文件路径,相对于源仓库的根目录prompt: 开发者提供的函数签名和文档字符串relavent_test_path: 相关测试用例的路径full_function: 当前样本的规范解决方案function_name: 目标函数(当前样本)的名称
示例
json { "repository": "seaborn", "repo_id": "0", "target_module_path": "seaborn/_core/scales.py", "prompt": " def label(self, formatter: Formatter | None = None, *, like: str | Callable | None = None, base: int | None | Default = default, unit: str | None = None) -> Continuous: ....", "relevant_test_path": "/usr/src/app/target_test_cases/failed_tests_Continuous.label.txt", "full_function": " def label(self, formatter: Formatter | None = None, *, like: str | Callable | None = None, base: int | None | Default = default, unit: str | None = None) -> Continuous: ....", "function_name": "Continuous.label" }
引用
@misc{liang2024repocod, title={Can Language Models Replace Programmers? REPOCOD Says Not Yet}, author={Shanchao Liang and Yiran Hu and Nan Jiang and Lin Tan}, year={2024}, eprint={2410.21647}, archivePrefix={arXiv}, primaryClass={cs.SE}, url={https://arxiv.org/abs/2410.21647}, }