---
language:
- en
bigbio_language:
- English
license: cc-by-3.0
multilinguality: monolingual
bigbio_license_shortname: CC_BY_3p0
pretty_name: BioNLP 2011 GE
homepage: https://sites.google.com/site/bionlpst/bionlp-shared-task-2011/genia-event-extraction-genia
bigbio_pubmed: True
bigbio_public: True
bigbio_tasks:
- EVENT_EXTRACTION
- NAMED_ENTITY_RECOGNITION
- COREFERENCE_RESOLUTION
---
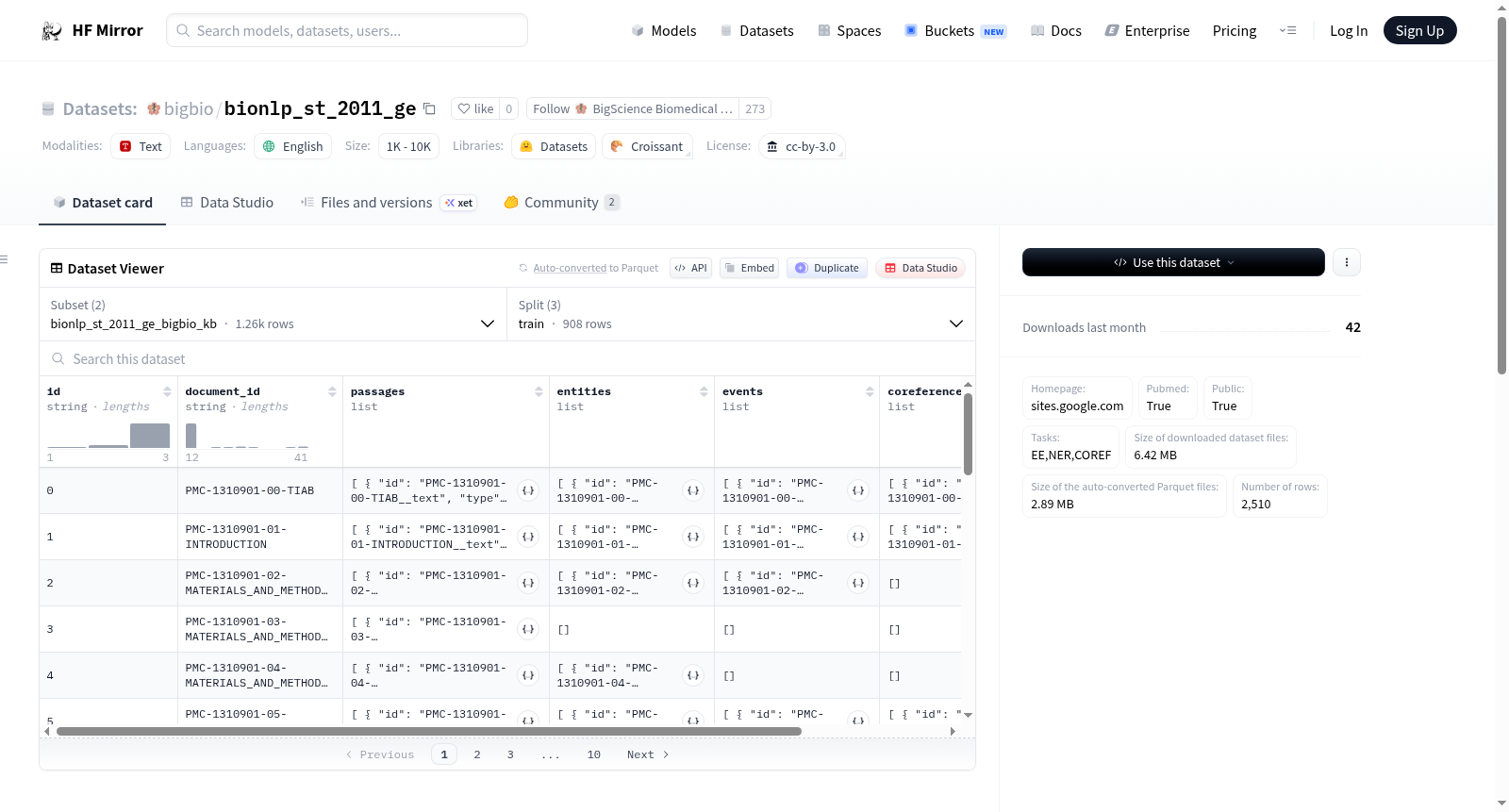
# Dataset Card for BioNLP 2011 GE
## Dataset Description
- **Homepage:** https://sites.google.com/site/bionlpst/bionlp-shared-task-2011/genia-event-extraction-genia
- **Pubmed:** True
- **Public:** True
- **Tasks:** EE,NER,COREF
The BioNLP-ST GE task has been promoting development of fine-grained information extraction (IE) from biomedical
documents, since 2009. Particularly, it has focused on the domain of NFkB as a model domain of Biomedical IE.
The GENIA task aims at extracting events occurring upon genes or gene products, which are typed as "Protein"
without differentiating genes from gene products. Other types of physical entities, e.g. cells, cell components,
are not differentiated from each other, and their type is given as "Entity".
## Citation Information
```
@inproceedings{10.5555/2107691.2107693,
author = {Kim, Jin-Dong and Wang, Yue and Takagi, Toshihisa and Yonezawa, Akinori},
title = {Overview of Genia Event Task in BioNLP Shared Task 2011},
year = {2011},
isbn = {9781937284091},
publisher = {Association for Computational Linguistics},
address = {USA},
abstract = {The Genia event task, a bio-molecular event extraction task,
is arranged as one of the main tasks of BioNLP Shared Task 2011.
As its second time to be arranged for community-wide focused
efforts, it aimed to measure the advance of the community since 2009,
and to evaluate generalization of the technology to full text papers.
After a 3-month system development period, 15 teams submitted their
performance results on test cases. The results show the community has
made a significant advancement in terms of both performance improvement
and generalization.},
booktitle = {Proceedings of the BioNLP Shared Task 2011 Workshop},
pages = {7–15},
numpages = {9},
location = {Portland, Oregon},
series = {BioNLP Shared Task '11}
}
```
language:
- 英语
bigbio_language:
- 英语
license: 知识共享署名3.0(CC BY 3.0)
multilinguality: 单语
bigbio_license_shortname: CC_BY_3p0
pretty_name: BioNLP 2011 GE
homepage: https://sites.google.com/site/bionlpst/bionlp-shared-task-2011/genia-event-extraction-genia
bigbio_pubmed: 是
bigbio_public: 是
bigbio_tasks:
- 事件抽取(EVENT_EXTRACTION)
- 命名实体识别(NAMED_ENTITY_RECOGNITION)
- 共指消解(COREFERENCE_RESOLUTION)
# BioNLP 2011 GE 数据集卡片
## 数据集描述
- **官方主页:** https://sites.google.com/site/bionlpst/bionlp-shared-task-2011/genia-event-extraction-genia
- **PubMed 关联:** 是
- **公开性:** 是
- **任务:** 事件抽取(EE)、命名实体识别(NER)、共指消解(COREF)
自2009年起,BioNLP-ST GE任务便致力于推动生物医学文档的细粒度信息抽取(Information Extraction,简称IE)技术发展。尤为特别的是,该任务以NFkB(核因子κB)作为生物医学信息抽取的示范领域展开研究。GENIA任务的目标是抽取发生于基因或基因产物之上的事件,此类实体被归类为"蛋白质(Protein)",且不区分基因与基因产物本身。其他类型的物理实体(例如细胞、细胞组分)则不做相互区分,统一标注为"实体(Entity)"。
## 引用信息
@inproceedings{10.5555/2107691.2107693,
author = {Kim, Jin-Dong and Wang, Yue and Takagi, Toshihisa and Yonezawa, Akinori},
title = {BioNLP 2011共享任务中GENIA事件任务综述(Overview of Genia Event Task in BioNLP Shared Task 2011)},
year = {2011},
isbn = {9781937284091},
publisher = {计算语言学协会(Association for Computational Linguistics)},
address = {美国},
abstract = {GENIA事件任务是一项生物分子事件抽取任务,作为BioNLP 2011共享任务的核心任务之一开展。这是该任务第二次面向社区开展集中式研究攻关,旨在衡量2009年以来该领域的技术进展,并评估技术对全文文献的泛化能力。经过3个月的系统开发周期,共有15支团队在测试集上提交了性能结果。结果显示,该领域社区在性能提升与技术泛化两方面均取得了显著进展。},
booktitle = {BioNLP 2011共享任务研讨会论文集(Proceedings of the BioNLP Shared Task 2011 Workshop)},
pages = {7–15},
numpages = {9},
location = {美国俄勒冈州波特兰市},
series = {BioNLP Shared Task '11}
}