CUBE-MT
收藏Hugging Face2025-05-22 更新2025-05-23 收录
下载链接:
https://huggingface.co/datasets/albertmeronyo/CUBE-MT
下载链接
链接失效反馈官方服务:
资源简介:
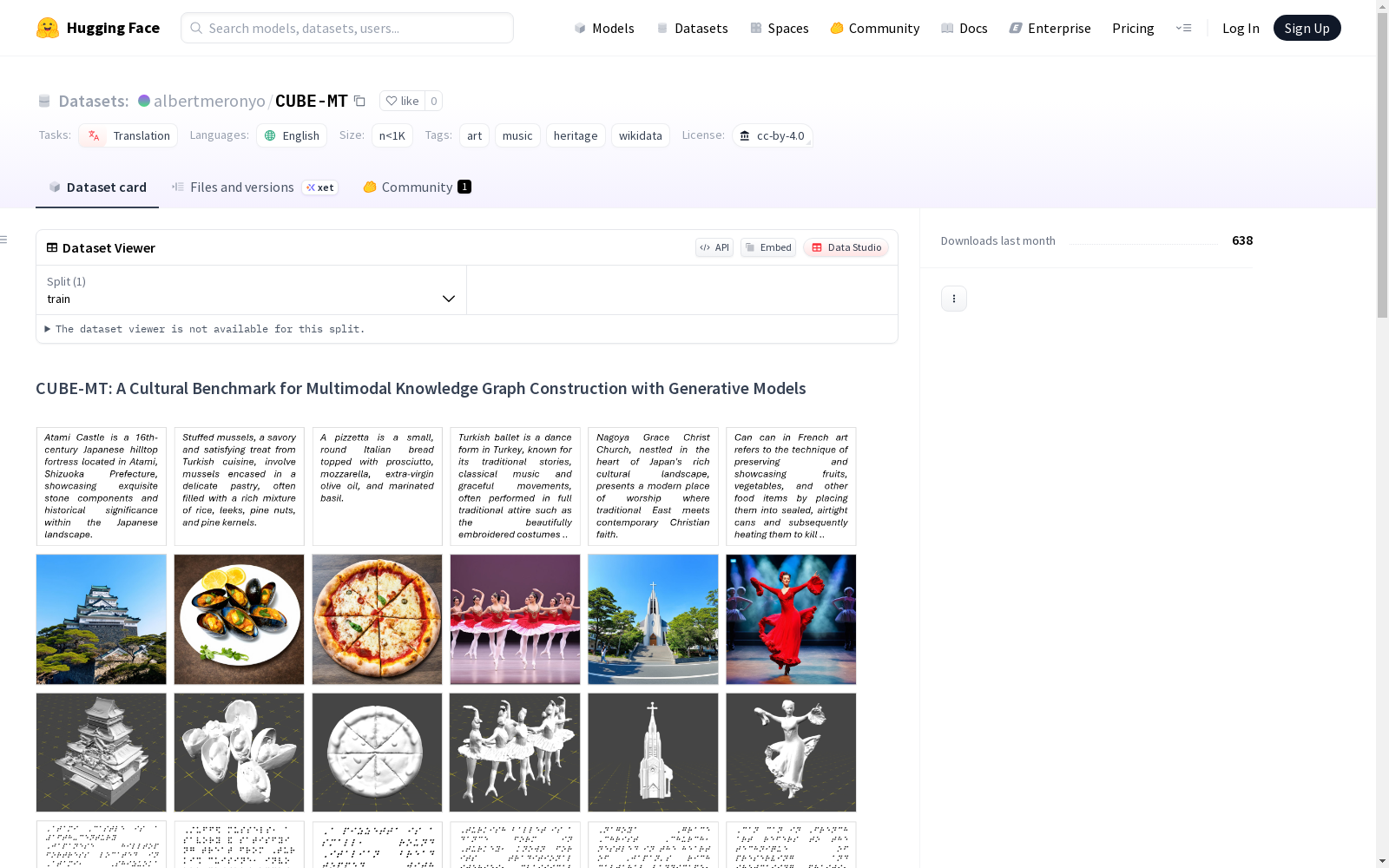
CUBE-MT(文化多模态基准)是一个用于多模态知识图谱构建的文化基准数据集,它包含了来自巴西、法国、印度、意大利、日本、尼日利亚、土耳其和美国的8个国家,以及饮食、地标和艺术等3个领域的300K个文化 artifact。数据集还包括了1000个用于评估生成AI模型文化意识的文本到图像生成提示。CUBE-MT扩展了原有的CUBE数据集,支持文本、盲文、语音、音乐、视频和3D等多种模态,并使用公共可用的Hugging Face模型生成了相应的多模态数据实例。
CUBE-MT (Cultural Multimodal Benchmark) is a cultural benchmark dataset for multimodal knowledge graph construction. It encompasses 300,000 cultural artifacts spanning 8 countries: Brazil, France, India, Italy, Japan, Nigeria, Turkey, and the United States, across three domains including diet, landmarks, and art. The dataset also includes 1,000 text-to-image generation prompts developed to evaluate the cultural awareness of generative AI models. CUBE-MT extends the original CUBE dataset, supporting diverse modalities such as text, Braille, speech, music, video, and 3D, and generates corresponding multimodal data instances using publicly available Hugging Face models.
创建时间:
2025-05-13
原始信息汇总
CUBE-MT数据集概述
基本信息
- 许可证: CC-BY-4.0
- 任务类别: 翻译 (translation)
- 语言: 英语 (en)
- 标签: 艺术 (art)、音乐 (music)、文化遗产 (heritage)、Wikidata (wikidata)
- 数据集名称: CUBE-MT: A Cultural Benchmark for Multimodal Knowledge Graph Construction with Generative AI
- 数据规模: 小于1K (n<1K)
数据集描述
CUBE-MT是CUltural BEnchmark for Text-to-Image models (CUBE)的扩展版本,旨在评估生成式AI模型的文化意识。CUBE包含来自8个国家(巴西、法国、印度、意大利、日本、尼日利亚、土耳其和美国)和3个领域(美食、地标、艺术)的30万件文化艺术品,以及1K个文本到图像生成提示。
扩展内容
- 多模态支持: 扩展至6种模态,包括文本、盲文、语音、音乐、视频和3D。
- 提示扩展: 扩展提示以评估生成这些模态的文化意识。
- 基准测试: 使用Hugging Face公开模型(如Stable Diffusion、Phi3、FastSpeech、MusicGen)生成模态实例。
数据集组成
- 元数据文件: CUBE-MT.json
- 数据转储: 数据转储链接
- Parquet版本:
refs/convert/parquet分支
使用基准
- 主文件: mt.ipynb包含用于每种模态的模型变量,可替换为其他模型。
- 支持的模型: Hugging Face上托管的模型,包括:
文档
- Wiki: CUBE-MT Wiki
引用
bibtex @misc{merono2025cubemt, title={{CUBE-MT: A Cultural Benchmark for Multimodal Knowledge Graph Construction with Generative Models}}, author={Albert Meroño-Peñuela and Nitisha Jain and Filip BIrcanin and Timothy Neate}, year={2025}, url={doi:10.5281/zenodo.15398577}, }
搜集汇总
数据集介绍
构建方式
在文化遗产数字化研究领域,CUBE-MT数据集通过扩展CUBE基准框架实现多模态知识图谱构建。其核心方法是从涵盖八国三领域的Wikidata知识库中自动生成文化描述提示,并利用Hugging Face平台的开源生成模型(如Stable Diffusion、MusicGen等)系统性地生成文本、盲文、语音、音乐、视频及三维模型六种模态数据,形成权威知识源驱动的多模态文化实例库。
特点
作为文化计算领域的前沿资源,该数据集以多模态协同为显著特征,覆盖视觉、听觉、触觉等多维感知通道。其文化代表性体现在精选巴西、法国等八国文化遗产数据,并通过统一的知识图谱结构确保跨模态语义关联。数据规模虽不足千例,但凭借精心设计的文化属性标注体系,为生成式人工智能的文化敏感性评估提供了标准化测试基准。
使用方法
研究者可通过修改基准测试脚本中的模型变量,灵活替换Hugging Face模型库中不同模态的生成模型进行评估。数据集提供JSON元数据文件与Parquet格式数据版本,支持跨平台分析。针对盲文生成等特殊模态,需结合pybraille等专用库进行扩展,而其他模态可直接调用平台预置接口实现端到端的文化内容生成与评测。
背景与挑战
背景概述
在文化遗产数字化保护与生成式人工智能融合的背景下,CUBE-MT数据集由Albert Meroño-Peñuela等学者于2025年构建,作为CUBE基准的多模态扩展。该数据集依托来自八个国家的三十万件文化遗产 Wikidata知识图谱,聚焦于评估生成模型在跨文化语境下的多模态内容生成能力。通过整合文本、盲文、语音等六种模态,该研究致力于解决生成式人工智能在文化敏感性表达方面的核心问题,为数字人文领域的知识图谱构建提供了标准化评估框架。
当前挑战
该数据集旨在应对生成式人工智能在跨文化多模态内容生成中的核心挑战,包括模型对多元文化符号的语义对齐、不同模态间信息一致性的保持,以及文化遗产实体在生成过程中的表征保真度。构建过程中面临知识图谱到多模态数据的复杂映射,需协调 Wikidata结构化属性与生成模型的非结构化输出;同时需克服多模态数据采集的技术壁垒,确保语音、盲文等特殊模态在文化语境下的生成质量与可访问性。
常用场景
经典使用场景
在文化遗产数字化研究领域,CUBE-MT数据集通过整合文本、盲文、语音等六种模态数据,为评估生成式AI模型的文化感知能力提供了标准化测试框架。该数据集基于维基数据知识图谱构建的3000个文化实体,能够系统检验多模态生成模型在烹饪、艺术等文化场景中的表现,成为衡量模型文化适应性的重要基准。
衍生相关工作
基于CUBE-MT的基准测试方法,研究者开发了文化感知的文本生成模型评估体系,并衍生出跨模态对齐技术的研究方向。在知识图谱增强生成领域,该数据集催生了结合Wikidata实体链接的多模态生成框架,同时启发了对生成模型文化偏见检测工具的开发,形成了一系列具有影响力的后续研究。
数据集最近研究
最新研究方向
在文化遗产数字化保护领域,CUBE-MT数据集通过扩展多模态知识图谱构建范式,将生成式人工智能与文化认知评估紧密结合。当前研究聚焦于跨模态生成模型的文化敏感性验证,利用涵盖文本、盲文、语音、音乐等六种模态的基准测试,探索生成模型在多元文化语境下的表征能力。该方向与全球文化遗产数字化浪潮相呼应,通过结构化知识图谱与生成模型的协同创新,为构建具有文化包容性的人工智能系统提供重要技术支撑,推动跨学科研究在数字人文领域的深度融合。
以上内容由遇见数据集搜集并总结生成


