HuggingFaceH4/stack-exchange-preferences
收藏Hugging Face2023-03-08 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/HuggingFaceH4/stack-exchange-preferences
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-sa-4.0
task_categories:
- question-answering
language:
- en
pretty_name: H4 Stack Exchange Preferences Dataset
tags:
- RLHF
- preferences
- human-feedback
- Stack Exchange
download_size: 22132072448
size_categories:
- 10M<n<100M
---
# Dataset Card for H4 Stack Exchange Preferences Dataset
## Dataset Description
- **Homepage:** https://archive.org/details/stackexchange
- **Repository:** (private for now) https://github.com/huggingface/h4
- **Point of Contact:** Nathan Lambert, nathan@huggingface.co
- **Size of downloaded dataset:** 22.13 GB
- **Number of instructions:** 10,741,532
### Dataset Summary
This dataset contains questions and answers from the [Stack Overflow Data Dump](https://archive.org/details/stackexchange) for the purpose of **preference model training**.
Importantly, the questions have been filtered to fit the following criteria for preference models (following closely from [Askell et al. 2021](https://arxiv.org/abs/2112.00861)): *have >=2 answers*.
This data could also be used for instruction fine-tuning and language model training.
The questions are grouped with answers that are assigned a score corresponding to the Anthropic paper:
```
score = log2 (1 + upvotes) rounded to the nearest integer, plus 1 if the answer was accepted by the questioner (we assign a score of −1 if the number of upvotes is negative).
```
Some important notes when using this dataset for preference model pretraining (PMP), which can be ignored for other uses:
* the data will likely need to be filtered more due to matching scores.
* see section 4.1 of Askel et al 2021 for instructions on using each pair of samples twice via the following `binarization` (for better pre-training initialization):
```
Subsequently, we created a binary dataset by applying a ‘binarization’ procedure to the ranked dataset. That
is, for every ranked pair A > B, we transform it into two independent binary comparisons:
GOOD:A > BAD:A
BAD:B > GOOD:B
```
To see all the stackexchanges used in this data, please see [this file](https://huggingface.co/datasets/HuggingFaceH4/pmp-stack-exchange/blob/main/stack_exchanges.json).
Unfortunately, sharing the binarized data directly without metadata violates the license, so we have shared a script for binarization.
### Using the data
Here is a script from our internal tooling used to create a binarized dataset:
```
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import random
from argparse import ArgumentParser
from pathlib import Path
import numpy as np
from datasets import Dataset, concatenate_datasets, load_dataset
from h4.data.utils import save_dataset_shards
H4_DIR = Path(__file__).resolve().parents[3]
DATA_DIR = H4_DIR / "data"
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--debug", action="store_true", help="Added print statements / limit data size for debugging")
parser.add_argument(
"--output_dir",
default=f"{DATA_DIR}/pmp-binarized",
type=str,
help="Where to save the processed dataset",
)
parser.add_argument(
"--exchange_name",
type=str,
default=None,
help="Optional argument to specify a specific subsection of the dataset",
)
parser.add_argument(
"--binary_score", type=int, default=8, help="Score assigned to binarized pairs for preference data."
)
parser.add_argument(
"--stream_data", action="store_true", help="Optionally stream data, which can be useful with weaker computers"
)
parser.set_defaults(debug=False, stream_data=False) # default will process full dataset
args = parser.parse_args()
specific_exchange = args.exchange_name
stream_dataset = args.stream_data
binary_score = args.binary_score
if specific_exchange:
data_dir = "data/" + args.exchange_name
else:
data_dir = None
if args.debug:
data_len_limit = 10000
else:
data_len_limit = np.inf
dataset = load_dataset(
"HuggingFaceH4/pmp-stack-exchange",
data_dir=data_dir,
split="train",
streaming=stream_dataset,
)
pmp_data = []
for i, d in enumerate(iter(dataset)):
# check debug limit, quit if in debug mode (don't save)
if i > data_len_limit:
print("Early exit for debug mode!")
print(pmp_data)
break
question = d["question"]
answers = d["answers"]
num_answers = len(answers)
answer_scores = [a["pm_score"] for a in answers]
if len(np.unique(answer_scores)) < 2:
print(f"PM Scores are {answer_scores}, skipping this question {i}")
else:
# Sample 2 unique scores for binarization
dif_scores = False
while not dif_scores:
# print("infinite loop...?")
two_answers = random.sample(answers, 2)
if two_answers[0]["pm_score"] != two_answers[1]["pm_score"]:
dif_scores = True
answer_0 = two_answers[0]
answer_1 = two_answers[1]
text_0 = "Question: " + question + "\n" + "Answer: " + answer_0["text"]
text_1 = "Question: " + question + "\n" + "Answer: " + answer_1["text"]
score_0 = binary_score
score_1 = binary_score
pmp_data.append({"context": text_0, "score": score_0})
pmp_data.append({"context": text_1, "score": score_1})
# Save binarized data
sublist_len = 100000
print(f"Dataset length is {len(pmp_data)}")
# bypass known issue in arrow https://issues.apache.org/jira/browse/ARROW-17137
print(f"Processed dataset length > {sublist_len}, processing to HF dataset in chunks")
chunks = [pmp_data[x : x + sublist_len] for x in range(0, len(pmp_data), sublist_len)]
ds_chunks = [Dataset.from_list(ch) for ch in chunks]
ds = concatenate_datasets(ds_chunks)
save_dataset_shards(ds, args.output_dir, subset="stackexchange", shard_size="100MB")
```
### Languages
This is intended to be English only, thought other languages may be present. Some Stack Exchanges that are omitted include:
```
spanish: es.meta.stackoverflow.com, es.stackoverflow.com
japanese: ja.meta.stackoverflow.com, ja.stackoverflow.com
portugese: pt.stackoverflow.com, pt.meta.stackoverflow.com
russian: ru.stackoverflow, ru.meta.stackoverflow
```
### Licensing Information
License: https://creativecommons.org/licenses/by-sa/4.0/
The cc-by-sa 4.0 licensing, while intentionally permissive, does require attribution:
Attribution — You must attribute the work in the manner specified by the author or licensor (but not in any way that suggests that they endorse you or your use of the work).
Specifically the attribution requirements are as follows:
1. Visually display or otherwise indicate the source of the content as coming from the Stack Exchange Network. This requirement is satisfied with a discreet text blurb, or some other unobtrusive but clear visual indication.
2. Ensure that any Internet use of the content includes a hyperlink directly to the original question on the source site on the Network (e.g., http://stackoverflow.com/questions/12345)
3. Visually display or otherwise clearly indicate the author names for every question and answer used
4. Ensure that any Internet use of the content includes a hyperlink for each author name directly back to his or her user profile page on the source site on the Network (e.g., http://stackoverflow.com/users/12345/username), directly to the Stack Exchange domain, in standard HTML (i.e. not through a Tinyurl or other such indirect hyperlink, form of obfuscation or redirection), without any “nofollow” command or any other such means of avoiding detection by search engines, and visible even with JavaScript disabled.
For more information, see the Stack Exchange Terms of Service.
### Citation Information
```
@online{h4stackexchange,
author = {Lambert, Nathan and Tunstall, Lewis and Rajani, Nazneen and Thrush, Tristan},
title = {HuggingFace H4 Stack Exchange Preference Dataset},
year = 2023,
url = {https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences},
}
```
---
license: CC BY-SA 4.0(知识共享署名-相同方式共享4.0)
task_categories:
- 问答(question-answering)
language:
- 英语(en)
pretty_name: H4 Stack Exchange 偏好数据集
tags:
- 强化学习从人类反馈中进行训练(RLHF)
- 偏好数据
- 人类反馈
- Stack Exchange
download_size: 22132072448
size_categories:
- 1000万<样本数<1亿
---
# H4 Stack Exchange 偏好数据集 数据集卡片
## 数据集概述
- **主页**:https://archive.org/details/stackexchange
- **代码仓库**:(目前私有)https://github.com/huggingface/h4
- **联系人**:内森·兰伯特(Nathan Lambert),邮箱:nathan@huggingface.co
- **下载后数据集大小**:22.13 GB
- **指令条数**:10741532
### 数据集摘要
本数据集源自[Stack Overflow 数据转储文件](https://archive.org/details/stackexchange),专为**偏好模型训练(preference model training)**打造。尤为关键的是,本数据集已按照偏好模型训练的标准进行筛选(严格遵循[Askell等人2021](https://arxiv.org/abs/2112.00861)的方案):**问题至少配有2个回答**。该数据集同样可用于指令微调与大语言模型训练。
数据集将问题与对应回答绑定,并为回答赋予评分,评分规则源自Anthropic的相关论文:
score = log₂(1 + 点赞数),并取最接近的整数;若回答被提问者采纳,则额外加1分(若点赞数为负,则评分为−1)。
若将本数据集用于偏好模型预训练(Preference Model Pretraining, PMP),需注意以下几点(其他使用场景可忽略):
* 由于评分匹配要求,可能需要对数据集进行进一步筛选。
* 详见[Askell等人2021]的4.1节,了解如何通过以下**二值化(binarization)**流程将每对样本复用两次(以获得更优的预训练初始化效果):
随后,我们通过对排序后的数据集执行「二值化」流程,构建了二分类数据集。具体而言,对于每一组排序对A > B,我们将其转换为两组独立的二值比较:
GOOD:A > BAD:A
BAD:B > GOOD:B
若需查看本数据集用到的所有Stack Exchange站点,请参阅[此文件](https://huggingface.co/datasets/HuggingFaceH4/pmp-stack-exchange/blob/main/stack_exchanges.json)。
遗憾的是,未经元数据直接共享二值化后的数据集会违反本许可证协议,因此我们仅提供二值化处理脚本。
### 数据使用方法
以下为我们内部用于生成二值化数据集的脚本:
python
# 版权所有 2023 HuggingFace团队。保留所有权利。
#
# 根据Apache许可证2.0版("许可证")获得许可;除非符合许可证要求,否则您不得使用此文件。
# 您可在以下网址获取许可证副本:
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# 除非适用法律要求或书面同意,否则按"原样"分发的软件,不附带任何明示或暗示的担保或条件。
# 有关许可证下的特定权限和限制的详细信息,请参阅许可证。
import random
from argparse import ArgumentParser
from pathlib import Path
import numpy as np
from datasets import Dataset, concatenate_datasets, load_dataset
from h4.data.utils import save_dataset_shards
H4_DIR = Path(__file__).resolve().parents[3]
DATA_DIR = H4_DIR / "data"
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--debug", action="store_true", help="启用调试模式,添加打印语句并限制数据集大小以方便调试")
parser.add_argument(
"--output_dir",
default=f"{DATA_DIR}/pmp-binarized",
type=str,
help="处理后数据集的保存路径",
)
parser.add_argument(
"--exchange_name",
type=str,
default=None,
help="可选参数,用于指定数据集的特定子模块",
)
parser.add_argument(
"--binary_score", type=int, default=8, help="为二值化后的偏好数据对分配的评分。"
)
parser.add_argument(
"--stream_data", action="store_true", help="可选参数,启用数据流模式,适用于配置较低的设备"
)
parser.set_defaults(debug=False, stream_data=False) # 默认处理完整数据集
args = parser.parse_args()
specific_exchange = args.exchange_name
stream_dataset = args.stream_data
binary_score = args.binary_score
if specific_exchange:
data_dir = "data/" + args.exchange_name
else:
data_dir = None
if args.debug:
data_len_limit = 10000
else:
data_len_limit = np.inf
dataset = load_dataset(
"HuggingFaceH4/pmp-stack-exchange",
data_dir=data_dir,
split="train",
streaming=stream_dataset,
)
pmp_data = []
for i, d in enumerate(iter(dataset)):
# 检查调试模式限制,若启用则在达到限制后提前退出(不保存数据)
if i > data_len_limit:
print("调试模式提前退出!")
print(pmp_data)
break
question = d["question"]
answers = d["answers"]
num_answers = len(answers)
answer_scores = [a["pm_score"] for a in answers]
if len(np.unique(answer_scores)) < 2:
print(f"PM评分为{answer_scores},跳过该问题 {i}")
else:
# 采样两个不同评分的回答用于二值化
dif_scores = False
while not dif_scores:
two_answers = random.sample(answers, 2)
if two_answers[0]["pm_score"] != two_answers[1]["pm_score"]:
dif_scores = True
answer_0 = two_answers[0]
answer_1 = two_answers[1]
text_0 = "问题:" + question + "
" + "回答:" + answer_0["text"]
text_1 = "问题:" + question + "
" + "回答:" + answer_1["text"]
score_0 = binary_score
score_1 = binary_score
pmp_data.append({"context": text_0, "score": score_0})
pmp_data.append({"context": text_1, "score": score_1})
# 保存二值化数据集
sublist_len = 100000
print(f"数据集长度为 {len(pmp_data)}")
# 绕过Apache Arrow已知问题 https://issues.apache.org/jira/browse/ARROW-17137
print(f"处理后的数据集长度 > {sublist_len},将分块转换为HF数据集")
chunks = [pmp_data[x : x + sublist_len] for x in range(0, len(pmp_data), sublist_len)]
ds_chunks = [Dataset.from_list(ch) for ch in chunks]
ds = concatenate_datasets(ds_chunks)
save_dataset_shards(ds, args.output_dir, subset="stackexchange", shard_size="100MB")
### 语言说明
本数据集默认仅包含英语内容,但可能存在少量其他语言的内容。以下为被排除的Stack Exchange站点:
- 西班牙语站点:es.meta.stackoverflow.com、es.stackoverflow.com
- 日语站点:ja.meta.stackoverflow.com、ja.stackoverflow.com
- 葡萄牙语站点:pt.stackoverflow.com、pt.meta.stackoverflow.com
- 俄语站点:ru.stackoverflow、ru.meta.stackoverflow.com
### 许可证信息
许可证:https://creativecommons.org/licenses/by-sa/4.0/
尽管CC BY-SA 4.0许可证旨在放宽使用限制,但仍需遵守署名要求:
1. 需以视觉标识或其他方式说明内容源自Stack Exchange网络。可通过低调的文本标注或其他不突兀但清晰的视觉标识满足此要求。
2. 若在互联网上使用本数据集内容,需添加直接指向源网站上原始问题的超链接(例如:http://stackoverflow.com/questions/12345)
3. 需以视觉标识或其他方式清晰展示所使用的每个问题和回答的作者姓名
4. 若在互联网上使用本数据集内容,需为每位作者的姓名添加直接指向其在源网站用户资料页面的超链接(例如:http://stackoverflow.com/users/12345/username),需直接指向Stack Exchange域名,使用标准HTML格式(不得通过Tinyurl或其他间接链接、混淆或重定向方式),不得使用“nofollow”标签或其他规避搜索引擎检测的手段,且即使禁用JavaScript也能正常显示链接。
更多信息请参阅Stack Exchange服务条款。
### 引用信息
bibtex
@online{h4stackexchange,
author = {Lambert, Nathan and Tunstall, Lewis and Rajani, Nazneen and Thrush, Tristan},
title = {HuggingFace H4 Stack Exchange Preference Dataset},
year = 2023,
url = {https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences},
}
提供机构:
HuggingFaceH4
原始信息汇总
H4 Stack Exchange Preferences Dataset 概述
数据集描述
- 数据集名称: H4 Stack Exchange Preferences Dataset
- 数据集用途: 主要用于偏好模型训练,也可用于指令微调和语言模型训练。
- 数据集内容: 包含从Stack Overflow数据转储中筛选出的问题及其至少两个答案,每个答案附有根据Anthropic论文定义的评分。
- 评分机制: 评分计算公式为
score = log2 (1 + upvotes) 四舍五入到最近的整数,如果答案被提问者接受则加1,如果upvotes为负则评分设为-1。 - 数据集大小: 下载大小为22.13 GB。
- 数据集语言: 主要为英语。
使用指南
- 数据预处理: 提供了一个脚本用于将数据集二值化,以便于偏好模型预训练。
- 注意事项: 使用此数据集进行偏好模型预训练时,可能需要进一步过滤数据以匹配评分。
许可证信息
- 许可证: CC-BY-SA-4.0
- 使用要求: 使用时必须按照许可证要求进行适当的归属,包括显示内容来源、作者信息及直接链接至原始问题和作者个人资料页。
引用信息
@online{h4stackexchange, author = {Lambert, Nathan and Tunstall, Lewis and Rajani, Nazneen and Thrush, Tristan}, title = {HuggingFace H4 Stack Exchange Preference Dataset}, year = 2023, url = {https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences}, }
搜集汇总
数据集介绍
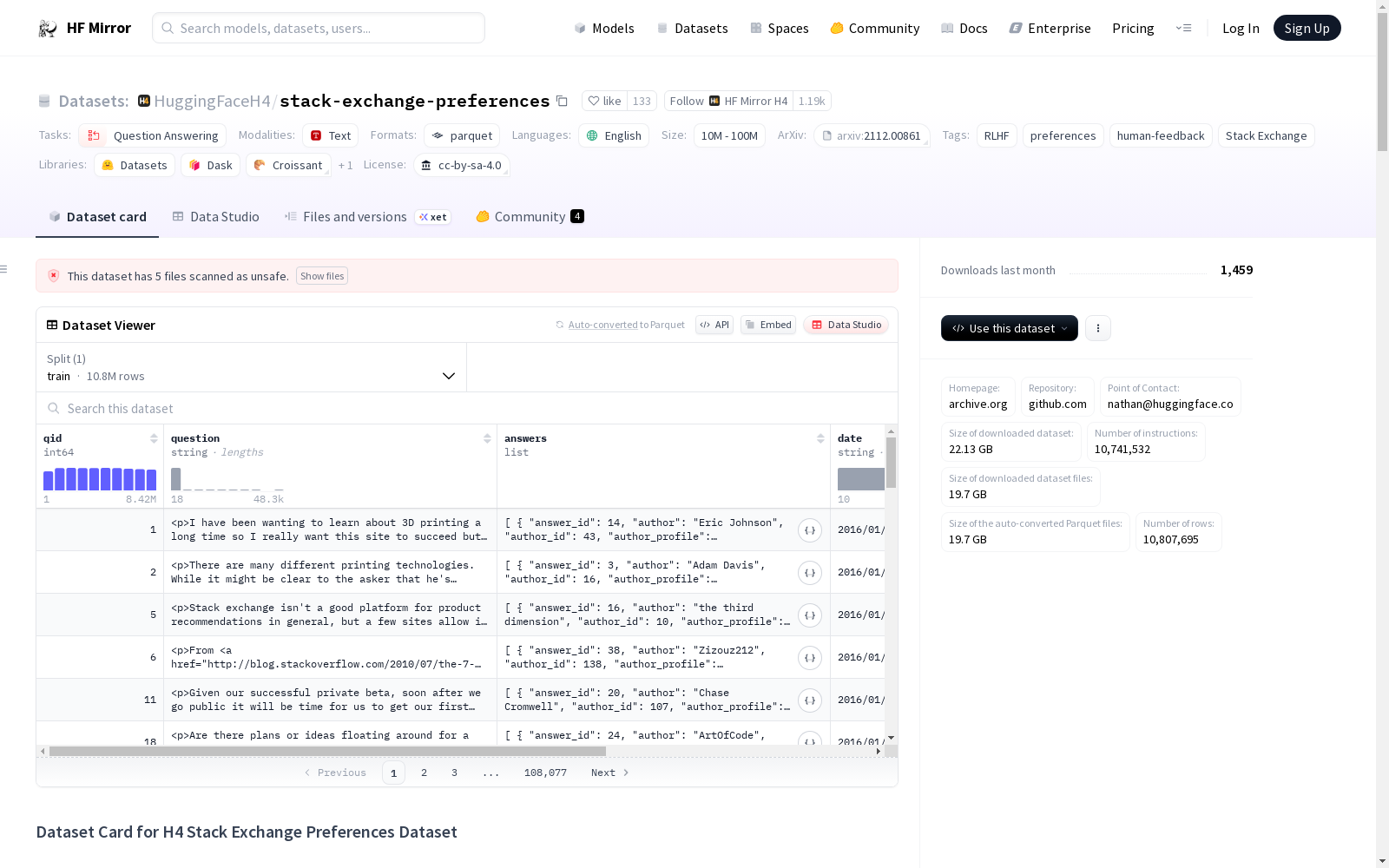
构建方式
H4 Stack Exchange Preferences Dataset 数据集的构建基于Stack Overflow数据源,经过筛选以确保每个问题至少有两个答案,进而适用于偏好模型的训练。数据集通过特定的评分机制对答案进行排序,并采用二值化处理以优化偏好模型的预训练初始化。
特点
该数据集的特点在于,其包含的问答对源自Stack Overflow社区,且针对每个答案的评分机制旨在反映用户对答案的偏好程度。数据集遵循Creative Commons BY-SA 4.0许可,允许在一定条件下共享和改编。此外,数据集的二值化处理增加了其在偏好模型训练中的应用价值。
使用方法
使用该数据集时,用户需遵循特定的二值化脚本,将评分数据转换为二元比较形式,以支持偏好模型的预训练。用户可以通过脚本参数来控制输出目录、数据子集以及二值化分数等,以便于在较弱计算设备上进行数据流式处理。
背景与挑战
背景概述
H4 Stack Exchange Preferences Dataset是一款由HuggingFace团队开发的,用于偏好模型训练的数据集。该数据集的创建可追溯至2023年,主要研究人员包括Nathan Lambert、Lewis Tunstall、Nazneen Rajani和Tristan Thrush。该数据集的核心研究问题是利用Stack Overflow数据.dump中的问题和答案,来训练偏好模型,进而为指令微调和语言模型训练提供支持。该数据集在自然语言处理领域具有重要的研究价值,尤其是在偏好学习模型的研究和开发中,提供了丰富的实验资源和基准数据。
当前挑战
该数据集在构建和应用过程中面临的挑战主要包括:1)领域问题挑战:如何利用Stack Overflow数据.dump中的问题和答案,有效地训练出具有高准确度的偏好模型;2)构建挑战:数据集构建过程中,如何处理和匹配分数,以避免数据偏差和过拟合问题。此外,由于数据集采用cc-by-sa 4.0许可,如何在保证合规的前提下,有效利用和共享数据,也是一项重要挑战。
常用场景
经典使用场景
在机器学习领域,特别是在偏好模型训练中,H4 Stack Exchange Preferences Dataset数据集扮演着至关重要的角色。该数据集收集了Stack Overflow数据.dump中的问题及答案,旨在通过用户对答案的投票来训练模型,以区分答案的优劣。
实际应用
在实际应用中,该数据集被广泛用于改进问答系统的答案排序,优化搜索引擎结果,以及提升推荐系统的个性化水平。通过对用户偏好的深入理解,相关应用能够提供更加贴合用户需求的服务,从而增强用户体验。
衍生相关工作
基于该数据集,衍生出了众多相关研究工作,包括但不限于偏好模型训练的新算法、更高效的数据处理方法以及针对不同场景的模型微调策略,这些工作进一步拓展了数据集的应用范围,推动了人工智能领域的发展。
以上内容由遇见数据集搜集并总结生成


