patrepeval
收藏Hugging Face2026-05-15 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/gebhart/patrepeval
下载链接
链接失效反馈官方服务:
资源简介:
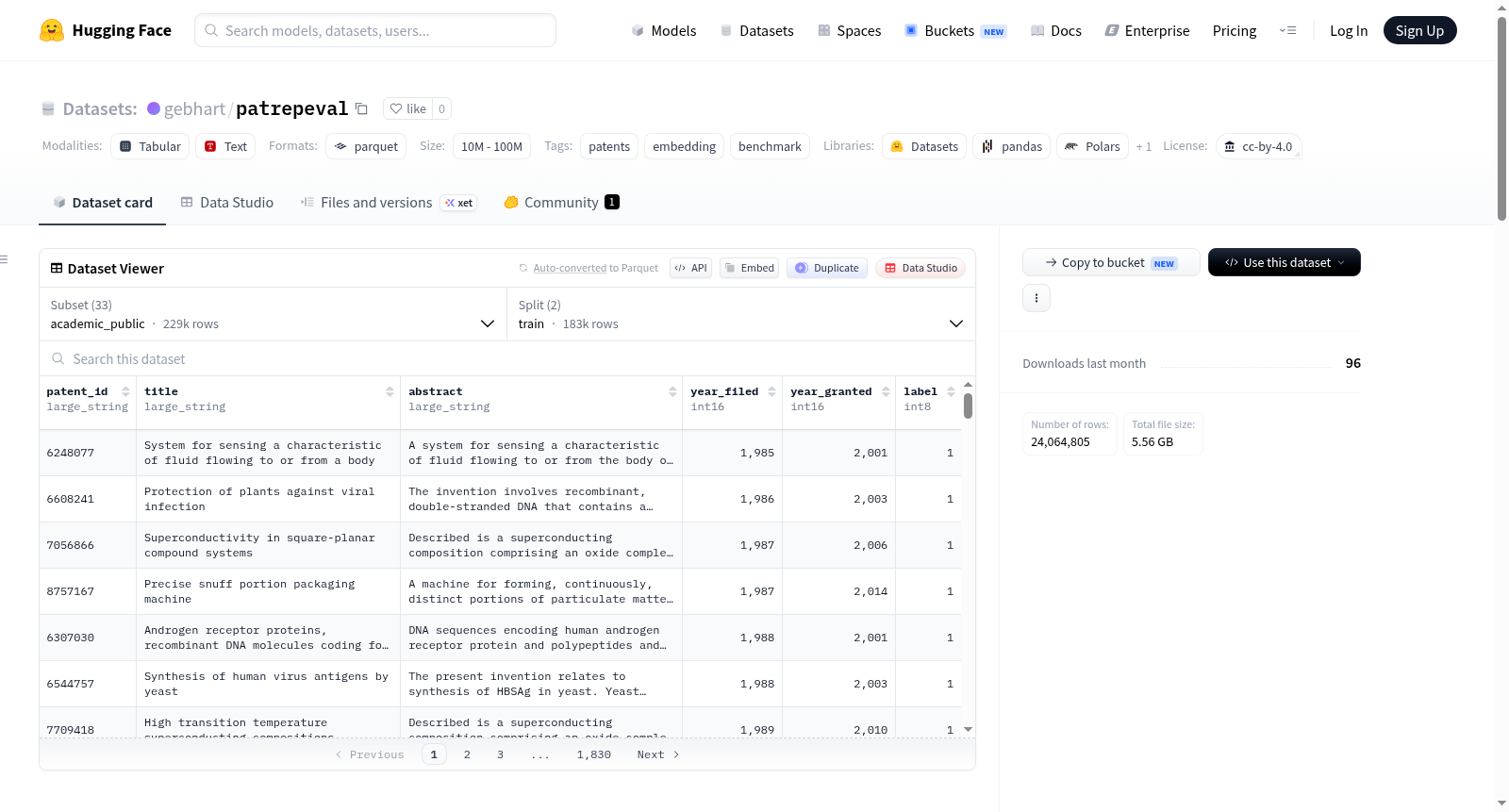
PaTRepEval(v0.4)是一个专门用于评估专利文本嵌入模型的综合性基准测试套件,类似于科学文献领域的SciRepEval。它旨在为专利领域的嵌入模型提供标准化、多任务的评估环境。核心数据来源于美国专利商标局(USPTO)的授权专利和预授权公布数据表,并整合了Kogan KPSS和Marx & Fuegi Reliance on Science等外部数据源以构建特定任务(Pool B / Phase 5)。数据集包含多个配置,覆盖三大类任务:1) 分类与回归任务:如专利受让人类型分类、CPC分类、专利续期预测、专利价值(Kogan值)回归、前向引用预测等,数据通常包含专利ID、标题、摘要、标签及申请/授权年份等字段,并按训练集/测试集划分。2) 检索任务:包括专利间引用检索、专利与论文互引检索、相同发明人检索、相同初始受让人检索等多种检索场景,每个检索配置均提供语料库、查询集和相关度判断文件。3) 基础语料库:`pool_a` 配置提供了约105万件实用专利的基准语料,按年份和合作专利分类(CPC)进行分层抽样,可供分类和回归任务在评估时共享使用。数据集采用Parquet格式存储,支持通过Hugging Face `datasets`库便捷加载,适用于专利文本表示学习、信息检索、分类预测等多种自然语言处理任务的研究与评估。
PaTRepEval (v0.4) is a comprehensive benchmark suite specifically designed for evaluating patent text embedding models, analogous to SciRepEval in the scientific literature domain. This dataset aims to provide a standardized, multi-task evaluation environment for embedding models in the patent field. The core data is sourced from the United States Patent and Trademark Office (USPTO) open data portal, including granted patents and pre-grant publication tables, and integrates external data sources such as Kogan KPSS and Marx & Fuegi Reliance on Science to construct specific tasks (Pool B / Phase 5). The dataset includes multiple configurations covering three major task categories: 1) Classification and regression tasks: e.g., patent assignee type classification, CPC classification, patent renewal prediction, patent value (Kogan value) regression, forward citation prediction, etc. The data typically includes patent ID, title, abstract, labels, and application/grant years, and is split into training/test sets. 2) Retrieval tasks: including patent-to-patent citation retrieval, patent-to-paper citation retrieval, same inventor retrieval, same original assignee retrieval, and other retrieval scenarios, with each retrieval configuration providing a corpus, query set, and relevance judgment files. 3) Base corpus: the `pool_a` configuration provides a benchmark corpus of approximately 1.05 million utility patents, stratified by year and Cooperative Patent Classification (CPC), which can be shared for classification and regression tasks during evaluation. The dataset is stored in Parquet format, supports easy loading via the Hugging Face `datasets` library, and is suitable for various natural language processing tasks such as patent text representation learning, information retrieval, and classification prediction research and evaluation.
创建时间:
2026-05-13
搜集汇总
数据集介绍
构建方式
在专利智能分析领域,对嵌入模型的评估需要覆盖多样化的任务场景。PaTRepEval数据集基于美国专利商标局开放数据门户中的授权专利与预授权公开数据表,并融合了Kogan KPSS、Marx & Fuegi Reliance on Science等外部权威数据源。其构建策略科学严谨,涵盖了分类、回归与检索三大类任务;在检索任务中,数据集提供了完整的语料库、查询集及关联判断文件,而分类与回归任务则划分了明确的训练集与测试集。此外,所有数据均以Parquet格式存储,便于高效读取与处理。
特点
该数据集具备卓越的全面性与层次化设计。它包含超过30个配置项,覆盖了从专利分类、引用预测到学术论文与专利交叉检索等多种任务,并特别设置了“困难”模式(如paper_patent_retrieval_hard)以挑战模型在复杂场景下的表现。评估指标因任务而异,检索任务采用MAP与nDCG@10,分类任务使用F1值,回归任务则选用Kendall Tau,确保了评价的精准与多元。此外,池A作为基础语料库,包含约105万件实用专利,采用年份与CPC分类分层抽样,为模型提供了坚实的数据底座。
使用方法
用户可通过HuggingFace datasets库便捷地加载该数据集。对于分类或回归任务,只需调用load_dataset函数并指定配置名称,即可获取包含训练集与测试集的字典对象,每条数据包含专利ID、标题、摘要及标签等字段。对于检索任务,则需分别加载语料库、查询集和关联判断三个分片。推荐在评估时共用池A语料库作为基础背景,以保持实验的一致性。当前版本为v0.4,建议在重现论文结果时通过Git标签锁定版本,以避免后续更新带来的分片变动。
背景与挑战
背景概述
专利数据作为技术创新的重要载体,蕴含着丰富的技术、经济与法律信息。然而,由于专利文本具有高度专业化的术语体系和复杂的结构化特征,传统自然语言处理模型在专利领域的表现往往不尽如人意。为此,PaTRepEval数据集应运而生,它由研究团队基于美国专利商标局(USPTO)开放数据门户的授权专利和预授权公开表格,辅以Kogan KPSS、Marx & Fuegi Reliance on Science等外部数据源构建而成。该数据集旨在为专利领域训练的嵌入模型提供一个系统化的评测基准,涵盖分类、回归和检索三大任务家族,共计30余种配置。PaTRepEval的发布填补了专利嵌入模型标准化评估的空白,为相关研究人员提供了衡量模型在专利文本理解、技术关联挖掘及经济价值预测等方面能力的权威工具。
当前挑战
PaTRepEval数据集所面临的挑战首先源自其核心研究问题的复杂性和跨领域性。专利评估涉及从技术分类(如CPC章节与子类)、法律状态(如授权与放弃)到经济价值(如Kogan价值)和科学关联度(如科学引用)等多维度问题,这对嵌入模型提出了融合异构信息与捕捉细微语义差异的要求。在构建过程中,挑战尤为突出:从USPTO等大规模数据库中提取、清洗和结构化过百万份专利记录,确保时间跨度和CPC分层抽样的代表性;平衡不同任务间样本分布的不均匀性并设计公平的评判标准(如F1宏平均、Kendall tau等);此外,还需处理专利与论文、专利权人与发明人之间的复杂关联,构建出既包含简单匹配又包含困难样本的检索对,以全面评测模型的鲁棒性。
常用场景
经典使用场景
在专利表征学习与知识图谱构建的交叉领域,PaTRepEval数据集堪称评估专利嵌入模型性能的权威基准。其最经典的使用场景在于为专利文本嵌入提供涵盖分类、回归和检索三大任务类型的标准化评测框架。具体而言,该数据集包含25个子配置,覆盖从CPC分类预测、专利价值回归分析到发明人与专利匹配检索等多元任务,其中检索类任务配备了严格的corpus-queries-qrels三元组结构。这种设计使得研究者能够系统性地评估嵌入模型在不同粒度上的语义捕获能力,尤其适合对比基于Transformer架构的专利语言模型与传统词嵌入方法的性能差异。
实际应用
在实际产业应用中,PaTRepEval所评测的嵌入能力直接服务于智能专利审查与知识管理平台。例如,基于该基准优化的专利检索模型可应用于专利审查员的前案检索系统,通过发明人与受让人匹配任务提升无效检索的准确率;其专利价值回归模块(如kogan_value与grant_abandon任务)被创新咨询机构用于自动化评估专利组合的经济潜力;而跨语言专利权人匹配功能则支持跨国企业在知识产权尽调中快速识别竞争对手的专利布局。此外,专利-论文关联检索能力已融入科研政策分析系统,用于量化基础研究对产业创新的科学吸纳(science_uptake)效率。
衍生相关工作
自PaTRepEval发布以来,若干重要研究工作围绕其基准任务展开延伸。首先,作为其直接继承者,NTX模型(Neural Text Embedding for Patents)利用该数据集的检索子集训练跨专利相似度表示,在专利引文预测任务上刷新了记录。其次,一系列关于专利多语言表示学习的研究,如Miao等人提出的Pat-BERT-XLM,借助PaTRepEval的中分类(cpc_subclass)任务验证了多语言预训练在专利文本上的迁移效果。再者,专利-论文跨模态检索领域涌现了RepPatent与SciPatentLink等工作,它们均采用该数据集的paper_patent_retrieval_hard配置作为核心验证基准。值得关注的是,该数据集还催生了专利元学习综述PICO,其零样本分类设定直接复用了PaTRepEval的学术公开(academic_public)任务。
以上内容由遇见数据集搜集并总结生成


