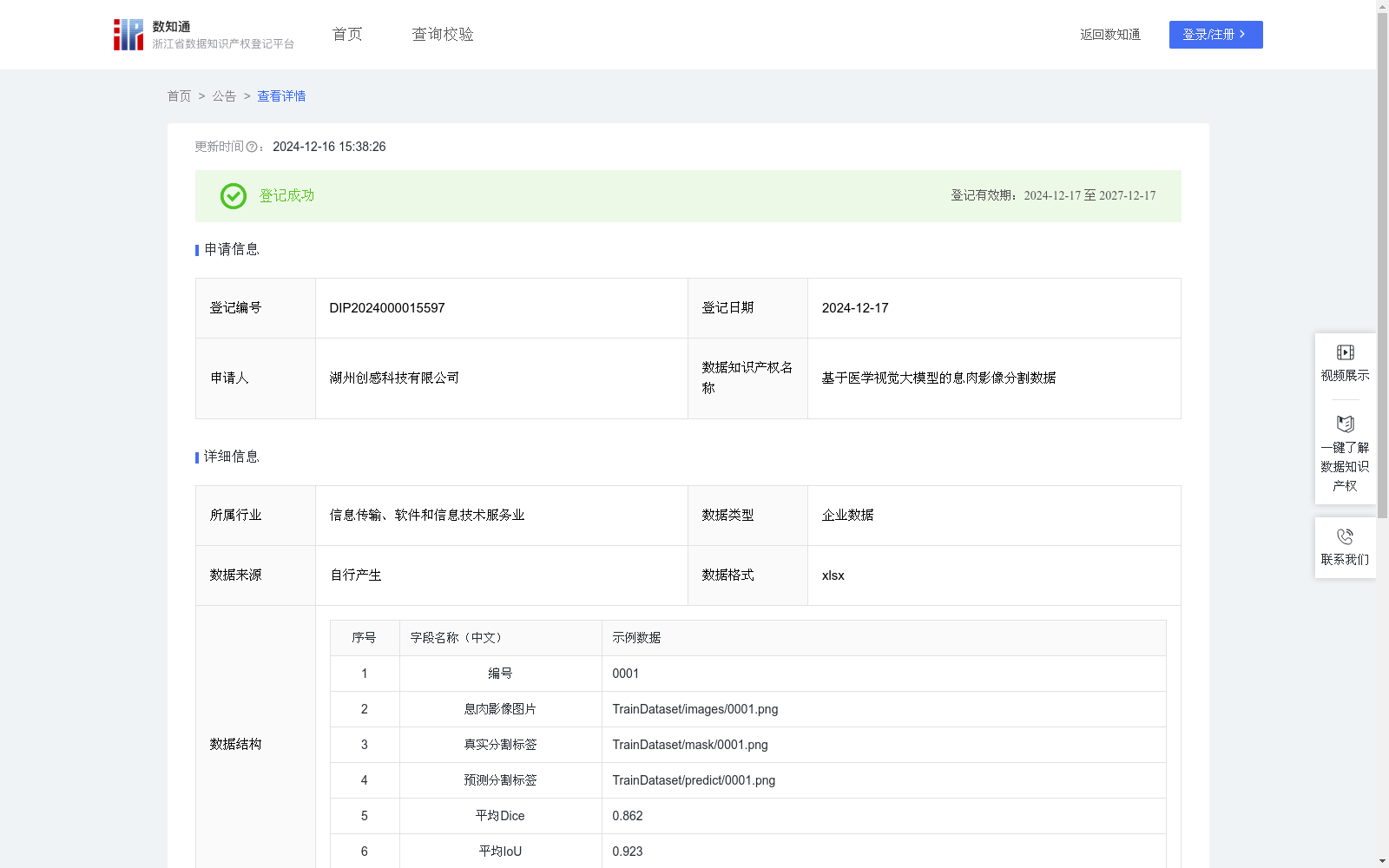
基于医学视觉大模型的息肉影像分割数据
收藏浙江省数据知识产权登记平台2024-12-16 更新2024-12-17 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/104898
下载链接
链接失效反馈官方服务:
资源简介:
医学影像分析是医学领域中重要的一环,特别是在肿瘤、息肉等病变的早期检测与诊断中。通过基于视觉大模型的图像分割技术,能够精准地从医学图像中提取息肉等病变区域,这对医生的诊断决策具有重要意义。基于大模型的医学息肉分割不仅能够提高分割精度,减少人工误差,还能实现高效、自动化的医学图像处理,极大地推动医疗领域的智能化应用。此技术可广泛应用于胃肠道疾病的筛查、临床辅助诊断、自动化影像标注和健康管理等方面。数据收集:在医学影像领域,通过采集不同类型的息肉图像,并进行专业的标注处理,构建数据集。每个数据样本包括:息肉影像图片,展示了包含息肉的图像区域。真实分割标签,由医学专家标注的真实分割图,精确标出了息肉区域。
数据预处理:所有医学图像首先通过图像增强和预处理技术进行标准化处理,例如尺寸归一化、去噪、亮度对比度调整等,以提高分割算法的鲁棒性和精度。每张图像都需要被处理为合适的输入格式,以适应深度学习模型的训练。
模型构建:采用先进的视觉大模型SAM进行微调训练。模型通过输入息肉图片数据,输出预测分割标签。公式如下:P=f_θ(I),其中f_θ表示视觉大模型,参数为θ,P为模型输出的预测分割标签。训练过程中,通过使用基于平均Dice系数和平均IoU的评价指标来评估模型的分割性能:
Medical image analysis is a critical component of the medical field, particularly for the early detection and diagnosis of lesions such as tumors and polyps. Image segmentation technology based on visual large models can accurately extract lesion regions including polyps from medical images, which holds great significance for physicians' diagnostic decision-making. Medical polyp segmentation based on large models not only improves segmentation accuracy and reduces manual errors, but also enables efficient and automated medical image processing, greatly advancing the intelligent applications of the healthcare sector. This technology can be widely applied in gastrointestinal disease screening, clinical auxiliary diagnosis, automated image annotation, health management, and other related fields.
Data Collection: In the medical imaging domain, a dataset is constructed by collecting various types of polyp images and conducting professional annotation work. Each data sample consists of two parts:
1. Polyp image: an image region containing polyps.
2. Ground-truth segmentation mask: a real segmentation map annotated by medical experts, which precisely marks the polyp regions.
Data Preprocessing: All medical images first undergo standardized processing via image enhancement and preprocessing techniques, such as size normalization, denoising, brightness and contrast adjustment, etc., to enhance the robustness and accuracy of the segmentation algorithm. Each image must be processed into a suitable input format to meet the training requirements of deep learning models.
Model Construction: The advanced visual large model SAM (Segment Anything Model) is utilized for fine-tuning training. The model takes polyp image data as input and outputs predicted segmentation masks. The formula is as follows:
$$P = f_ heta(I)$$
where $f_ heta$ represents the visual large model with parameter $ heta$, and $P$ is the predicted segmentation mask output by the model. During the training process, the mean Dice coefficient and mean IoU are used as evaluation metrics to assess the model's segmentation performance.
提供机构:
湖州创感科技有限公司
创建时间:
2024-11-14
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


