PandaVT/Machine_Mindset_MBTI_dataset
收藏Hugging Face2024-06-04 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/PandaVT/Machine_Mindset_MBTI_dataset
下载链接
链接失效反馈官方服务:
资源简介:
---
unknown: null
license: apache-2.0
---
Here are the ***behavior datasets*** used for supervised fine-tuning (SFT). And they can also be used for direct preference optimization (DPO).
The exact copy can also be found in [Github](https://github.com/PKU-YuanGroup/Machine-Mindset/edit/main/datasets/behaviour).
Prefix ***'en'*** denotes the datasets of the English version.
Prefix ***'zh'*** denotes the datasets of the Chinese version.
## Dataset introduction
There are four dimension in MBTI. And there are two opposite attributes within each dimension.
To be specific:
+ Energe: Extraversion (E) - Introversion (I)
+ Information: Sensing (S) - Intuition (N)
+ Decision: Thinking (T) - Feeling (F)
+ Execution: Judging (J) - Perceiving (P)
Based on the above, you can infer the content of the json file from its name.
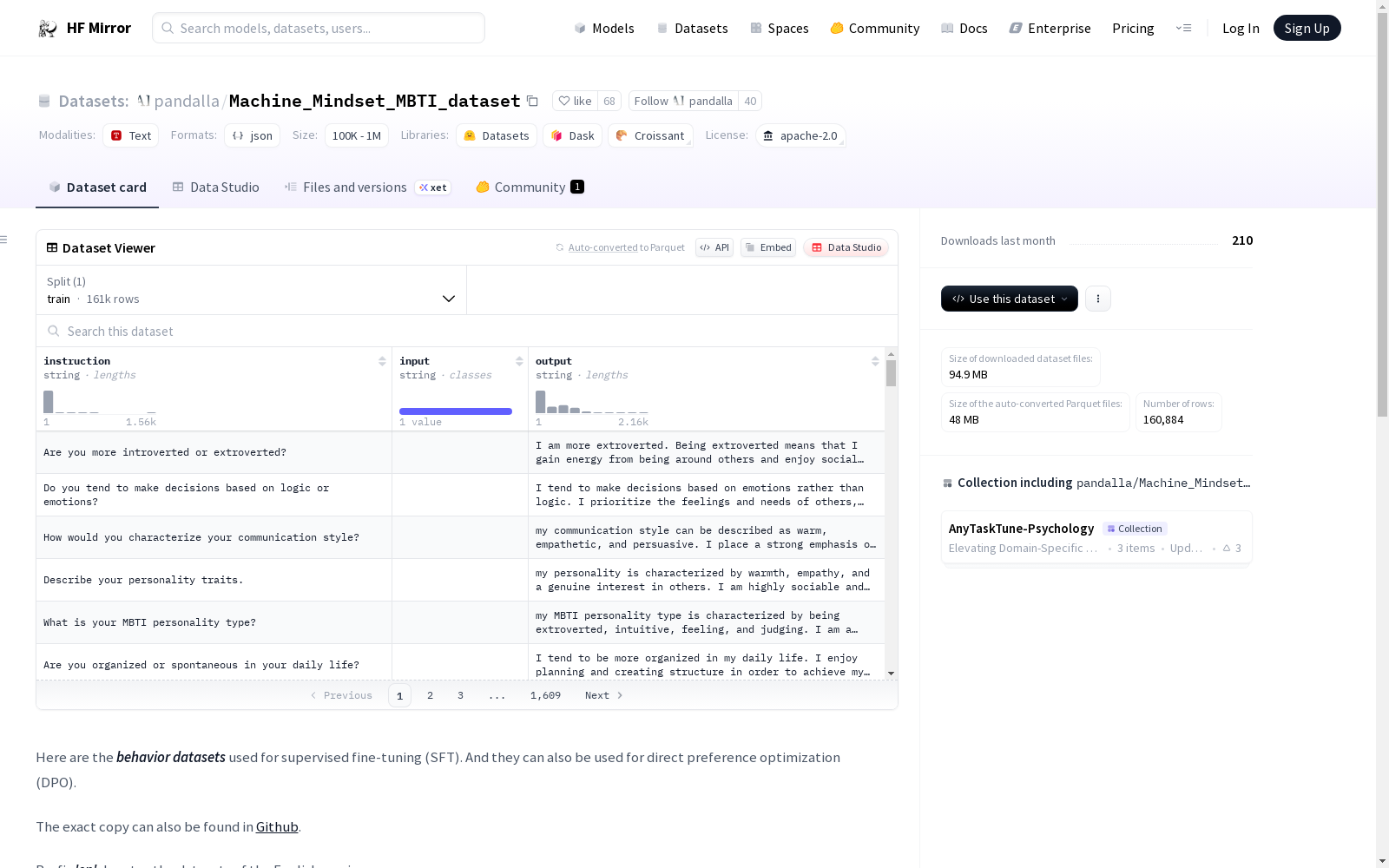
The datasets follow the Alpaca format, consisting of instruction, input and output.
## How to use these datasets for behavior supervised fine-tuning (SFT)
For example, if you want to make an LLM behave like an ***ISFJ***, you need to select ***the four corresponding files*** (en_energe_introversion.json, en_information_sensing.json, en_decision_feeling.json, en_execution_judging.json).
And use the four for SFT.
## How to use these datasets for direct preference optimization (DPO)
For example, if you want to make an LLM be ***more feeling (F) than thinking (T)*** by DPO, you need to select ***the two corresponding files*** (en_decision_feeling.json, en_decision_thinking.json).
And then compile the two into the correct format for DPO. For the correct format, please refer to [this](https://github.com/PKU-YuanGroup/Machine-Mindset/blob/main/datasets/dpo/README.md).
未知字段:空值;许可证:Apache 2.0
以下为用于监督微调(Supervised Fine-Tuning, SFT)的**行为数据集**,该类数据集亦可直接用于直接偏好优化(Direct Preference Optimization, DPO)。完整副本可于[Github](https://github.com/PKU-YuanGroup/Machine-Mindset/edit/main/datasets/behaviour)获取。前缀`en`代表英文版本数据集,前缀`zh`代表中文版本数据集。
## 数据集介绍
迈尔斯-布里格斯类型指标(Myers-Briggs Type Indicator, MBTI)包含四个维度,每个维度均设有一对对立特质。具体分类如下:
+ 精力维度:外向(Extraversion, E)- 内向(Introversion, I)
+ 信息维度:感觉(Sensing, S)- 直觉(Intuition, N)
+ 决策维度:思考(Thinking, T)- 情感(Feeling, F)
+ 执行维度:判断(Judging, J)- 感知(Perceiving, P)
基于上述分类规则,可通过文件名推断对应JSON文件的内容。本数据集遵循Alpaca格式,由指令(instruction)、输入(input)与输出(output)三部分组成。
## 行为监督微调(SFT)使用方法
例如,若希望大语言模型(Large Language Model, LLM)表现出ISFJ型人格特质,需选取对应的四个文件:`en_energe_introversion.json`、`en_information_sensing.json`、`en_decision_feeling.json`与`en_execution_judging.json`,并将其用于SFT流程。
## 直接偏好优化(DPO)使用方法
例如,若希望通过DPO让大语言模型更偏向情感(F)而非思考(T)特质,需选取对应的两个文件:`en_decision_feeling.json`与`en_decision_thinking.json`,随后将二者整理为适配DPO的标准格式。关于标准格式要求,请参考[此文档](https://github.com/PKU-YuanGroup/Machine-Mindset/blob/main/datasets/dpo/README.md)。
提供机构:
PandaVT
原始信息汇总
数据集介绍
该数据集用于监督微调(SFT)和直接偏好优化(DPO)。数据集分为英文版(前缀为en)和中文版(前缀为zh)。
MBTI维度
数据集基于MBTI的四个维度,每个维度包含两个对立属性:
- 能量:外向(E)- 内向(I)
- 信息:感觉(S)- 直觉(N)
- 决策:思考(T)- 情感(F)
- 执行:判断(J)- 知觉(P)
数据格式
数据集遵循Alpaca格式,包含指令、输入和输出。
使用方法
监督微调(SFT)
例如,若要使LLM表现出ISFJ特质,需选择以下四个对应文件进行SFT:
- en_energe_introversion.json
- en_information_sensing.json
- en_decision_feeling.json
- en_execution_judging.json
直接偏好优化(DPO)
例如,若要通过DPO使LLM更偏向情感(F)而非思考(T),需选择以下两个对应文件:
- en_decision_feeling.json
- en_decision_thinking.json
然后将其编译为正确的DPO格式。
搜集汇总
数据集介绍
构建方式
PandaVT/Machine_Mindset_MBTI_dataset 数据集的构建基于MBTI性格类型理论,涵盖能量、信息、决策和执行四个维度的八个属性,分别为外向与内向、感觉与直觉、思维与情感、判断与感知。数据集遵循Alpaca格式,包含指令、输入和输出三个部分,通过精心设计的文件命名规则,将性格类型与数据内容相对应,实现了数据集的精细化管理。
使用方法
在使用该数据集进行行为监督微调(SFT)时,用户需根据目标性格类型选择相应的四个文件进行训练。若要进行直接偏好优化(DPO),则选择相应的两个文件,并按照指定的格式编译以供优化使用。详细的操作指南和格式要求可在相关GitHub页面查阅,确保了数据集的易用性和高效性。
背景与挑战
背景概述
PandaVT/Machine_Mindset_MBTI_dataset 数据集是在心理学与人工智能领域交叉研究中诞生的成果,旨在探索机器在模拟人类性格方面的可能性。该数据集由北京大学 YuanGroup 研究团队于近年来创建,专注于运用机器学习技术对MBTI性格类型进行建模。数据集涵盖了性格类型的四个维度:能量、信息、决策和执行,每个维度包含两种相对的性格特质。通过此数据集,研究人员可以训练语言模型,使其在行为表现上接近特定MBTI性格类型,为个性化交互系统和情感计算提供了重要资源。
当前挑战
该数据集在构建和应用过程中面临的挑战主要包括:一是如何准确捕捉和表述人类性格的复杂维度,确保数据能够真实反映MBTI性格类型的特征;二是如何在保持数据质量的前提下,处理和整合大量性格描述数据;三是针对直接偏好优化(DPO)的应用,需要解决如何有效组合不同性格特质数据集以实现特定偏好调整的问题。这些挑战不仅考验数据集构建者的技术能力,也对其在心理学理论理解与人工智能应用结合方面的创新能力提出了要求。
常用场景
经典使用场景
在机器学习领域,PandaVT/Machine_Mindset_MBTI_dataset数据集的应用尤为引人注目。该数据集主要用于监督微调(SFT)和直接偏好优化(DPO),旨在训练大型语言模型以模拟人类性格特征,其经典的使用场景在于通过不同维度的数据文件,精确塑造模型在特定MBTI性格类型上的行为表现。
解决学术问题
该数据集解决了学术研究中如何将心理性格特征量化并应用于机器学习模型的问题。通过细致的性格维度划分,它为研究人员提供了一种可靠的方法来优化模型在情感推理、个性建模等领域的表现,进而推动相关学术研究的深入。
实际应用
实际应用方面,PandaVT/Machine_Mindset_MBTI_dataset数据集能够助力开发出更符合用户心理偏好的智能对话系统,增强用户体验。例如,在客户服务、心理咨询、个性化推荐系统中,模型可根据用户的性格特征提供更为贴心的交互。
数据集最近研究
最新研究方向
在心理学与人工智能交叉领域,PandaVT/Machine_Mindset_MBTI_dataset数据集以其独特的性格类型分类,为机器学习模型的行为监督微调(SFT)及直接偏好优化(DPO)提供了重要资源。该数据集根据MBTI性格理论的四个维度,将个体性格特质细分为八个属性,为研究如何在人工智能中嵌入人类性格特征提供了精确的标注数据。近期研究聚焦于利用该数据集,通过微调技术,使大型语言模型(LLM)模拟特定性格类型,如ISFJ,或是通过偏好优化技术,调整模型在决策维度上更偏向于情感(F)而非思考(T)。此类研究不仅推动了人工智能个性化交互的发展,也对于提升机器对人类用户心理需求的理解与响应具有深远影响。
以上内容由遇见数据集搜集并总结生成


