bigbio/scifact
收藏Hugging Face2022-12-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/bigbio/scifact
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
bigbio_language:
- English
license: cc-by-nc-2.0
multilinguality: monolingual
bigbio_license_shortname: CC_BY_NC_2p0
pretty_name: SciFact
homepage: https://scifact.apps.allenai.org/
bigbio_pubmed: False
bigbio_public: True
bigbio_tasks:
- TEXT_PAIRS_CLASSIFICATION
---
# Dataset Card for SciFact
## Dataset Description
- **Homepage:** https://scifact.apps.allenai.org/
- **Pubmed:** False
- **Public:** True
- **Tasks:** TXT2CLASS
### Scifact Corpus Source
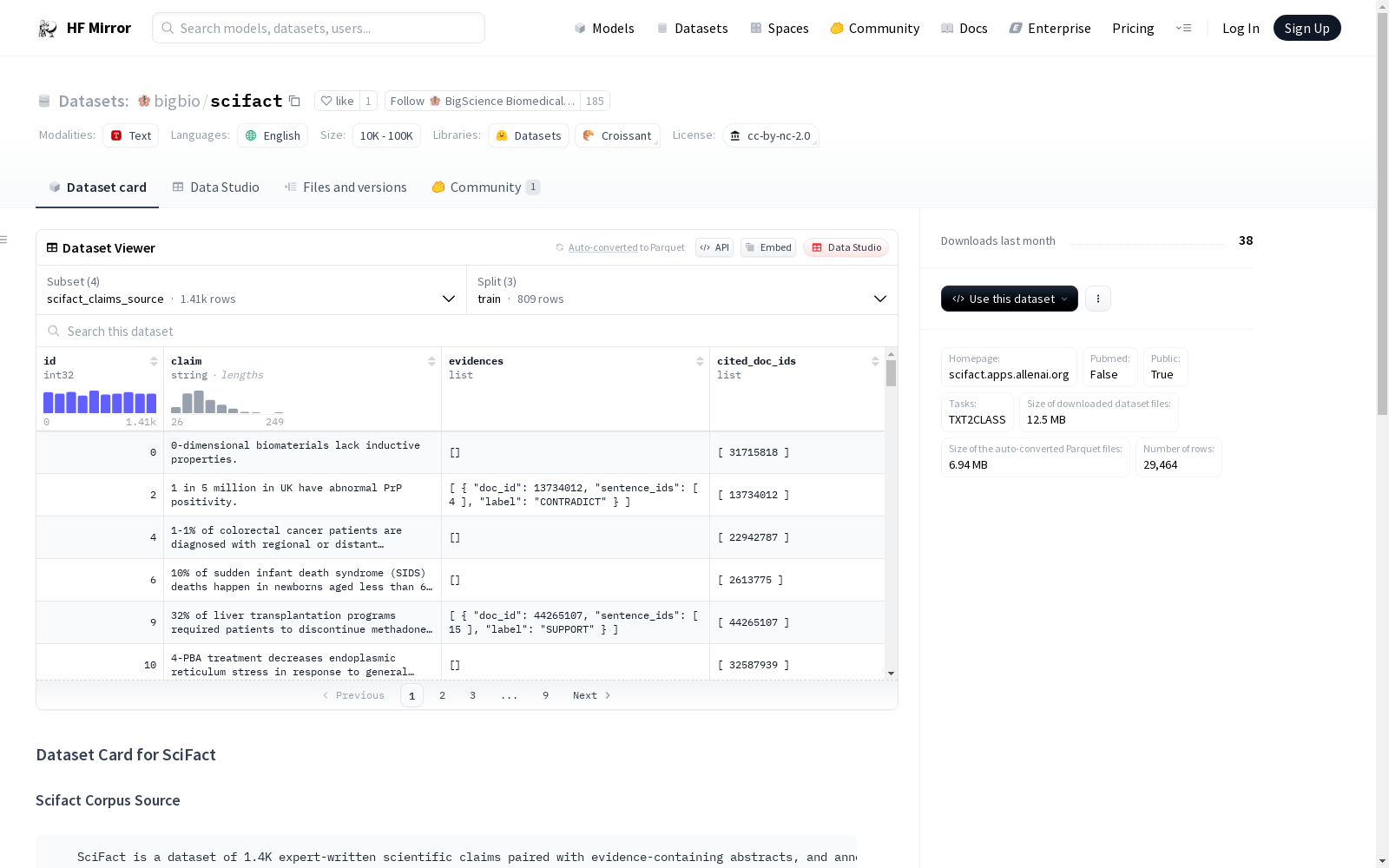
SciFact is a dataset of 1.4K expert-written scientific claims paired with evidence-containing abstracts, and annotated with labels and rationales.
This config has abstracts and document ids.
### Scifact Claims Source
{_DESCRIPTION_BASE} This config connects the claims to the evidence and doc ids.
### Scifact Rationale Bigbio Pairs
{_DESCRIPTION_BASE} This task is the following: given a claim and a text span composed of one or more sentences from an abstract, predict a label from ("rationale", "not_rationale") indicating if the span is evidence (can be supporting or refuting) for the claim. This roughly corresponds to the second task outlined in Section 5 of the paper."
### Scifact Labelprediction Bigbio Pairs
{_DESCRIPTION_BASE} This task is the following: given a claim and a text span composed of one or more sentences from an abstract, predict a label from ("SUPPORT", "NOINFO", "CONTRADICT") indicating if the span supports, provides no info, or contradicts the claim. This roughly corresponds to the thrid task outlined in Section 5 of the paper.
## Citation Information
```
@article{wadden2020fact,
author = {David Wadden and Shanchuan Lin and Kyle Lo and Lucy Lu Wang and Madeleine van Zuylen and Arman Cohan and Hannaneh Hajishirzi},
title = {Fact or Fiction: Verifying Scientific Claims},
year = {2020},
address = {Online},
publisher = {Association for Computational Linguistics},
url = {https://aclanthology.org/2020.emnlp-main.609},
doi = {10.18653/v1/2020.emnlp-main.609},
pages = {7534--7550},
biburl = {},
bibsource = {}
}
```
---
language:
- 英语
bigbio_language:
- 英语
license: 知识共享署名-非商业性使用2.0协议(CC-BY-NC-2.0)
multilinguality: 单语言
bigbio_license_shortname: CC_BY_NC_2p0
pretty_name: SciFact
homepage: https://scifact.apps.allenai.org/
bigbio_pubmed: 否
bigbio_public: 是
bigbio_tasks:
- 文本对分类(TEXT_PAIRS_CLASSIFICATION)
---
# SciFact 数据集卡片
## 数据集描述
- **Homepage:** 官方主页:https://scifact.apps.allenai.org/
- **Pubmed:** 否
- **Public:** 公开可用
- **Tasks:** 文本对分类(TEXT_PAIRS_CLASSIFICATION)
### SciFact 语料库源
SciFact是一个包含1400条专家撰写的科学主张的数据集,配套带有含证据的学术摘要,并附带标签与推理依据(rationale)的标注。此配置项包含摘要与文档ID。
### SciFact 主张源
{_DESCRIPTION_BASE} 此配置项将科学主张与证据及文档ID相关联。
### SciFact 推理依据BigBio样本对
本任务设定如下:给定一条科学主张,以及一段由学术摘要中的一个或多个句子组成的文本片段,从("rationale", "not_rationale")中预测标签,以表明该片段是否可作为该主张的证据(可起到支持或反驳作用)。这大致对应论文第5节中概述的第二项任务。
### SciFact 标签预测BigBio样本对
{_DESCRIPTION_BASE} 本任务设定如下:给定一条科学主张,以及一段由学术摘要中的一个或多个句子组成的文本片段,从("SUPPORT", "NOINFO", "CONTRADICT")中预测标签,分别表示该片段支持该主张、未提供相关信息,或与该主张相矛盾。这大致对应论文第5节中概述的第三项任务。
## 引用信息
@article{wadden2020fact,
author = {David Wadden and Shanchuan Lin and Kyle Lo and Lucy Lu Wang and Madeleine van Zuylen and Arman Cohan and Hannaneh Hajishirzi},
title = {Fact or Fiction: Verifying Scientific Claims},
year = {2020},
address = {Online},
publisher = {Association for Computational Linguistics},
url = {https://aclanthology.org/2020.emnlp-main.609},
doi = {10.18653/v1/2020.emnlp-main.609},
pages = {7534--7550},
biburl = {},
bibsource = {}
}
提供机构:
bigbio
原始信息汇总
数据集概述
基本信息
- 名称: SciFact
- 语言: 英语
- 许可证: CC BY NC 2.0
- 多语言性: 单语种
- 公开状态: 公开
- PubMed链接: 无
数据集内容
- 数据集大小: 包含1.4K专家撰写的科学声明,每个声明均与包含证据的摘要配对,并附有标签和理由。
- 数据结构:
- SciFact Corpus Source: 包含摘要和文档ID。
- SciFact Claims Source: 连接声明与证据及文档ID。
- SciFact Rationale Bigbio Pairs: 任务为判断给定声明和文本跨度(由摘要中的一个或多个句子组成)是否为证据,标签为("rationale", "not_rationale")。
- SciFact Labelprediction Bigbio Pairs: 任务为判断给定声明和文本跨度是否支持、提供无信息或反驳声明,标签为("SUPPORT", "NOINFO", "CONTRADICT")。
任务类型
- 主要任务: TEXT_PAIRS_CLASSIFICATION
- 具体任务:
- 判断文本跨度是否为声明的证据。
- 判断文本跨度对声明的支持、无信息或反驳情况。
引用信息
@article{wadden2020fact, author = {David Wadden and Shanchuan Lin and Kyle Lo and Lucy Lu Wang and Madeleine van Zuylen and Arman Cohan and Hannaneh Hajishirzi}, title = {Fact or Fiction: Verifying Scientific Claims}, year = {2020}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2020.emnlp-main.609}, doi = {10.18653/v1/2020.emnlp-main.609}, pages = {7534--7550}, biburl = {}, bibsource = {} }
搜集汇总
数据集介绍
构建方式
SciFact数据集是由专家撰写的科学声明与包含证据的摘要配对而成,总计包含1.4K条数据。该数据集通过精细的标注过程,将声明与摘要中的文本片段相关联,并标注上相应的标签和理由,为文本对分类任务提供了坚实的基础。
使用方法
使用SciFact数据集时,研究者可以通过其提供的Homepage获取数据集详情,并根据数据集的配置文件连接声明与证据及文档ID。数据集支持两种任务:预测文本片段是否为证据,以及预测文本片段对声明的支持程度。用户可根据具体的研究需求,选择适当的任务进行模型训练与评估。
背景与挑战
背景概述
SciFact数据集,由Wadden等人于2020年构建,旨在为科学声明验证领域提供支持。该数据集包含了1.4K个由专家撰写的科学声明及其对应的含有证据的摘要,并标注了标签和解释。SciFact的创建,为自然语言处理领域中的信息抽取和验证任务提供了重要资源,对于提升机器理解科学文献的能力产生了显著影响。
当前挑战
SciFact数据集面临的挑战主要包括两个方面:一是如何准确地将科学声明与摘要中的证据文本进行匹配,并标注出支持或反驳的关系;二是构建过程中,确保数据质量的高标准,包括声明与证据的相关性以及标签的准确性。这些挑战对于提升模型的推理能力和减少误判至关重要。
常用场景
经典使用场景
在科学文献的理解与验证领域,SciFact数据集以其独特的文本对分类任务,成为研究者的得力工具。该数据集通过提供专家撰写的科学声明及其对应的证据摘要,辅以标签和解释,为文本对的分类研究提供了标准化且高质量的实验材料。
解决学术问题
SciFact数据集解决了科学声明验证中的标注一致性问题和证据识别的准确性问题。通过精确的标注和丰富的证据文本,该数据集为学术研究提供了可靠的基准,有助于提升自然语言处理技术在科学文本理解中的应用性能。
实际应用
在现实应用中,SciFact数据集的应用场景广泛,如辅助科学文章的写作、提升信息检索系统的精准度,以及在教育领域中辅助学生进行科学论证的训练等。
数据集最近研究
最新研究方向
在自然语言处理领域,SciFact数据集正引领着对科学声明进行验证的研究前沿。该数据集通过将专家撰写的科学声明与包含证据的摘要配对,并标注上标签和理由,为研究者提供了深入探索文本 pairs classification任务的宝贵资源。目前,学者们正致力于利用SciFact数据集,开发能够准确预测文本片段是否为声明证据的模型,以期为科学信息的真实性和可靠性提供自动化的验证工具。这一研究不仅对学术出版物的质量控制具有重要意义,而且对于公众科学素养的提升亦具有深远影响。
以上内容由遇见数据集搜集并总结生成


