All-CVE-Records-Training-Dataset
收藏魔搭社区2026-04-30 更新2025-06-21 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/All-CVE-Records-Training-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
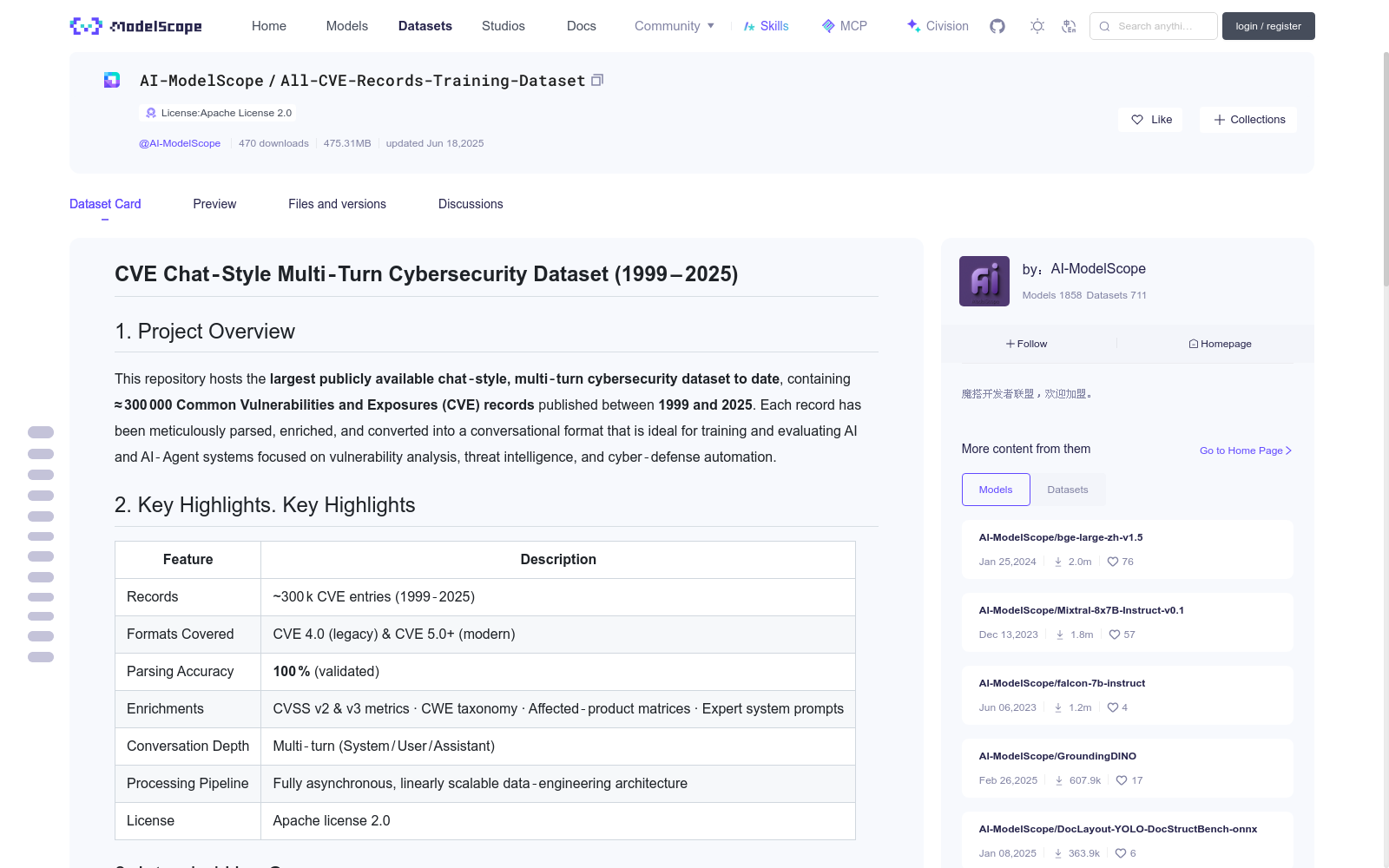
# CVE Chat‑Style Multi‑Turn Cybersecurity Dataset (1999 – 2025)
 
## 1. Project Overview
This repository hosts the **largest publicly available chat‑style, multi‑turn cybersecurity dataset to date**, containing **≈ 300 000 Common Vulnerabilities and Exposures (CVE) records** published between **1999 and 2025**. Each record has been meticulously parsed, enriched, and converted into a conversational format that is ideal for training and evaluating AI and AI‑Agent systems focused on vulnerability analysis, threat intelligence, and cyber‑defense automation.
## 2. Key Highlights. Key Highlights
| Feature | Description |
| ------------------- | --------------------------------------------------------------------------------------- |
| Records | \~300 k CVE entries (1999‑2025) |
| Formats Covered | CVE 4.0 (legacy) & CVE 5.0+ (modern) |
| Parsing Accuracy | **100 %** (validated) |
| Enrichments | CVSS v2 & v3 metrics · CWE taxonomy · Affected‑product matrices · Expert system prompts |
| Conversation Depth | Multi‑turn (System / User / Assistant) |
| Processing Pipeline | Fully asynchronous, linearly scalable data‑engineering architecture |
| License | Apache license 2.0 |
## 3. Intended Use Cases
- **Fine‑tuning LLMs** for vulnerability triage and severity prediction.
- **Temporal trend analysis** of vulnerability disclosures.
- **Retrieval‑Augmented Generation (RAG)** and autonomous **AI‑Agent** pipelines.
- **Real‑time threat‑intelligence** enrichment services.
- **Automated penetration‑testing** (pentest) orchestration.
> **Benchmark Note**\
> Early experiments with *Llama 3.2* and *Gemma* models achieved **94 % accuracy** on CVE class‑prediction tasks after full fine‑tuning on this dataset.
## 4. Dataset Structure
Each dialogue is stored as a single **JSON Lines (`.jsonl`)** object with **three top‑level keys**:
```json
{
"System": "You are a cybersecurity expert specializing in penetration testing, vulnerability research, and exploit development. Provide comprehensive technical analysis of CVE vulnerabilities with academic rigor and practical exploitation insights.",
"User": "Provide a comprehensive technical analysis of CVE‑2010‑3763, including exploitation vectors, impact assessment, and remediation strategies.",
"Assistant": "## CVE‑2010‑3763 Vulnerability Details
### CVE Metadata
- **CVE ID**: CVE‑2010‑3763
- **State**: PUBLISHED
..."
}
```
### Field Reference
| Key | Type | Description |
|-------------|--------|---------------------------------------------------------------------|
| `System` | string | System prompt that frames the assistant’s role and response style. |
| `User` | string | End‑user request or question. |
| `Assistant` | string | Model answer containing enriched CVE analysis and metadata. |
> **Note**: Multi‑turn conversations are represented as separate JSONL lines that share the same `System` context while `User` and `Assistant` evolve turn by turn.
## 5. Processing Pipeline. Processing Pipeline
1. **Source Aggregation** – CVE XML feeds (4.0) + JSON feeds (5.0+).
2. **Asynchronous Parsing** – Custom Rust & Python pipeline (Tokio + asyncio) for 100 % parsing success.
3. **Enrichment Layer** – CVSS scoring, CWE classification, product‑matrix generation.
4. **Conversation Generation** – Expert prompts injected to produce System / User / Assistant structure.
5. **Validation & QA** – Schema checks, de‑duplication, manual spot‑checks.
## 6. Quick Start
### Load with 🤗 `datasets`
```python
from datasets import load_dataset
cve_chat = load_dataset("<username>/<repo_name>", split="train")
print(cve_chat[0])
```
### Finetune Example (PEFT & QLoRA)
```bash
python train.py \
--model "meta-llama/Meta-Llama-3-8B" \
--dataset "<username>/<repo_name>" \
--peft lora \
--bits 4
```
## 7. Data Splits
| Split | Records | Notes |
| ------------ | ------- | ----- |
| `train` | 240 000 | 80 % |
| `validation` | 30 000 | 10 % |
| `test` | 27 441 | 10 % |
## 8. Contact
Contributions, feedback, and pull requests are warmly welcomed!
# CVE对话式多轮网络安全数据集(1999 – 2025)
## 1. 项目概述
本仓库托管了**截至目前规模最大的公开可用对话式多轮网络安全数据集**,包含1999年至2025年间发布的约30万条**通用漏洞与披露(Common Vulnerabilities and Exposures,CVE)**记录。每条记录均经过精细化解析、丰富标注,并转换为对话格式,非常适合训练和评估针对漏洞分析、威胁情报及网络防御自动化的人工智能(AI)与**AI智能体(AI Agent)**系统。
## 2. 核心亮点
| 特征项 | 描述 |
| ------------------- | -------------------------------------------------------------------- |
| 记录数 | 约30万条CVE条目(1999‑2025) |
| 支持格式 | CVE 4.0(旧版)与CVE 5.0+(现代版) |
| 解析准确率 | **100%**(已验证) |
| 丰富标注内容 | 通用漏洞评分系统(Common Vulnerability Scoring System,CVSS)v2与v3评分 · 通用弱点枚举(Common Weakness Enumeration,CWE)分类体系 · 受影响产品矩阵 · 专家系统提示词 |
| 对话深度 | 多轮格式(系统/用户/助手) |
| 处理流水线 | 全异步、可线性扩展的数据工程架构 |
| 许可证 | Apache许可证2.0 |
## 3. 预期应用场景
- **大语言模型(Large Language Model,LLM)**微调:用于漏洞分类与严重性预测
- 漏洞披露的时间趋势分析
- 检索增强生成(Retrieval-Augmented Generation,RAG)与自主**AI智能体(AI Agent)**流水线
- 实时威胁情报增强服务
- 自动化渗透测试(渗透测试)编排
> **基准测试说明**
> 早期基于Llama 3.2与Gemma模型的实验显示,在该数据集上完成全量微调后,在CVE类别预测任务上达到了**94%**的准确率。
## 4. 数据集结构
每条对话以单个**JSON行格式(JSON Lines,.jsonl)**对象存储,包含三个顶级键:
json
{
"System": "You are a cybersecurity expert specializing in penetration testing, vulnerability research, and exploit development. Provide comprehensive technical analysis of CVE vulnerabilities with academic rigor and practical exploitation insights.",
"User": "Provide a comprehensive technical analysis of CVE‑2010‑3763, including exploitation vectors, impact assessment, and remediation strategies.",
"Assistant": "## CVE‑2010‑3763 Vulnerability Details
### CVE Metadata
- **CVE ID**: CVE‑2010‑3763
- **State**: PUBLISHED
..."
}
### 字段说明
| 键名 | 类型 | 描述 |
|-------------|--------|--------------------------------------------------------------|
| `System` | 字符串 | 定义助手角色与回复风格的系统提示词。 |
| `User` | 字符串 | 终端用户的请求或提问。 |
| `Assistant` | 字符串 | 包含丰富标注的CVE分析与元数据的模型回复。 |
> **注意**:多轮对话通过多条共享同一`System`上下文的JSONL行表示,其中`User`与`Assistant`内容随对话轮次逐步演进。
## 5. 处理流水线
1. **源数据聚合**:获取CVE XML数据源(4.0版本)与JSON数据源(5.0及以上版本)
2. **异步解析**:基于Rust与Python的自定义流水线(使用Tokio与asyncio框架),实现100%解析成功率
3. **丰富标注层**:生成CVSS评分、CWE分类、受影响产品矩阵
4. **对话生成**:注入专家提示词以生成System/User/Assistant结构
5. **验证与质量检查**:执行模式校验、去重、人工抽样检查
## 6. 快速开始
### 使用🤗 `datasets`库加载
python
from datasets import load_dataset
cve_chat = load_dataset("<username>/<repo_name>", split="train")
print(cve_chat[0])
### 微调示例(参数高效微调Parameter-Efficient Fine-Tuning,PEFT与量化低秩适配器Quantized Low-Rank Adapter,QLoRA)
bash
python train.py
--model "meta-llama/Meta-Llama-3-8B"
--dataset "<username>/<repo_name>"
--peft lora
--bits 4
## 7. 数据划分
| 划分集 | 记录数 | 占比 |
| ------------ | ------- | ----- |
| `train` | 240 000 | 80% |
| `validation` | 30 000 | 10% |
| `test` | 27 441 | 10% |
## 8. 联系方式
欢迎贡献代码、反馈意见与提交拉取请求!
提供机构:
maas
创建时间:
2025-06-18
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是迄今为止最大的公开可用的聊天风格多轮网络安全数据集,包含约30万条1999年至2025年发布的CVE记录。每条记录都经过详细解析和丰富,转换为适合AI系统训练的对话格式,适用于漏洞分析、威胁情报和网络防御自动化等应用场景。
以上内容由遇见数据集搜集并总结生成


