EntropyMath-Gen-v1
收藏Hugging Face2026-05-05 更新2026-05-06 收录
下载链接:
https://huggingface.co/datasets/sgmlc1234/EntropyMath-Gen-v1
下载链接
链接失效反馈官方服务:
资源简介:
EntropyMath-Generated-v1是一个经过质量控制的、声明唯一的生成式数学推理评估数据集。该数据集包含934个问题,每个问题均配有声明、答案、解决方案、用于一致性验证的`verification_code`字段、谱系和来源元数据以及内容哈希值。数据集来源于EntropyMath生成框架,经过自动化质量门控和人工专家验证,确保了内容的独特性和质量。数据集的构建过程包括从生成运行中导出已验证的完整行、运行自动化质量门控、通过`statement_sha256`进行去重,以及单次人工专家验证确认。数据集适用于数学推理评估研究、生成器审计和基准方法研究,但不适合作为永久性隐藏排行榜使用。数据集已知的局限性包括偏向于种子和提示中代表的竞赛风格数学家族、`verification_code`仅检查计算一致性而非证明每个解决方案,以及LLM辅助验证可能遗漏的歧义、捷径解决方案或无效推导。数据集采用CC BY 4.0许可发布。
EntropyMath-Generated-v1 is a quality-controlled, statement-unique generative math reasoning evaluation dataset. It contains 934 problems, each accompanied by a statement, answer, solution, a `verification_code` field for consistency verification, lineage and source metadata, and a content hash. The dataset originates from the EntropyMath generation framework and has undergone automated quality gating and expert human validation to ensure content uniqueness and quality. The construction process includes exporting verified complete rows from generation runs, running automated quality gates, deduplication via `statement_sha256`, and a single expert human validation pass. The dataset is suitable for math reasoning evaluation research, generator auditing, and benchmark method research, but is not suitable for use as a permanent hidden leaderboard. Known limitations include bias towards competition-style math families represented in the seeds and prompts, `verification_code` only checking computational consistency rather than proving each solution, and potential ambiguities, shortcut solutions, or invalid derivations missed by LLM-assisted verification. The dataset is released under the CC BY 4.0 license.
创建时间:
2026-05-05
原始信息汇总
数据集概述:EntropyMath-Generated-v1
基本信息
- 数据集名称:EntropyMath-Generated-v1(EntropyMath-Gen-v1)
- 许可证:CC BY 4.0
- 语言:英语
- 数据集大小:1K < n < 10K(实际包含934条问题)
- 任务类别:问答
- 标签:数学推理、合成数据、评估、基准测试
数据内容
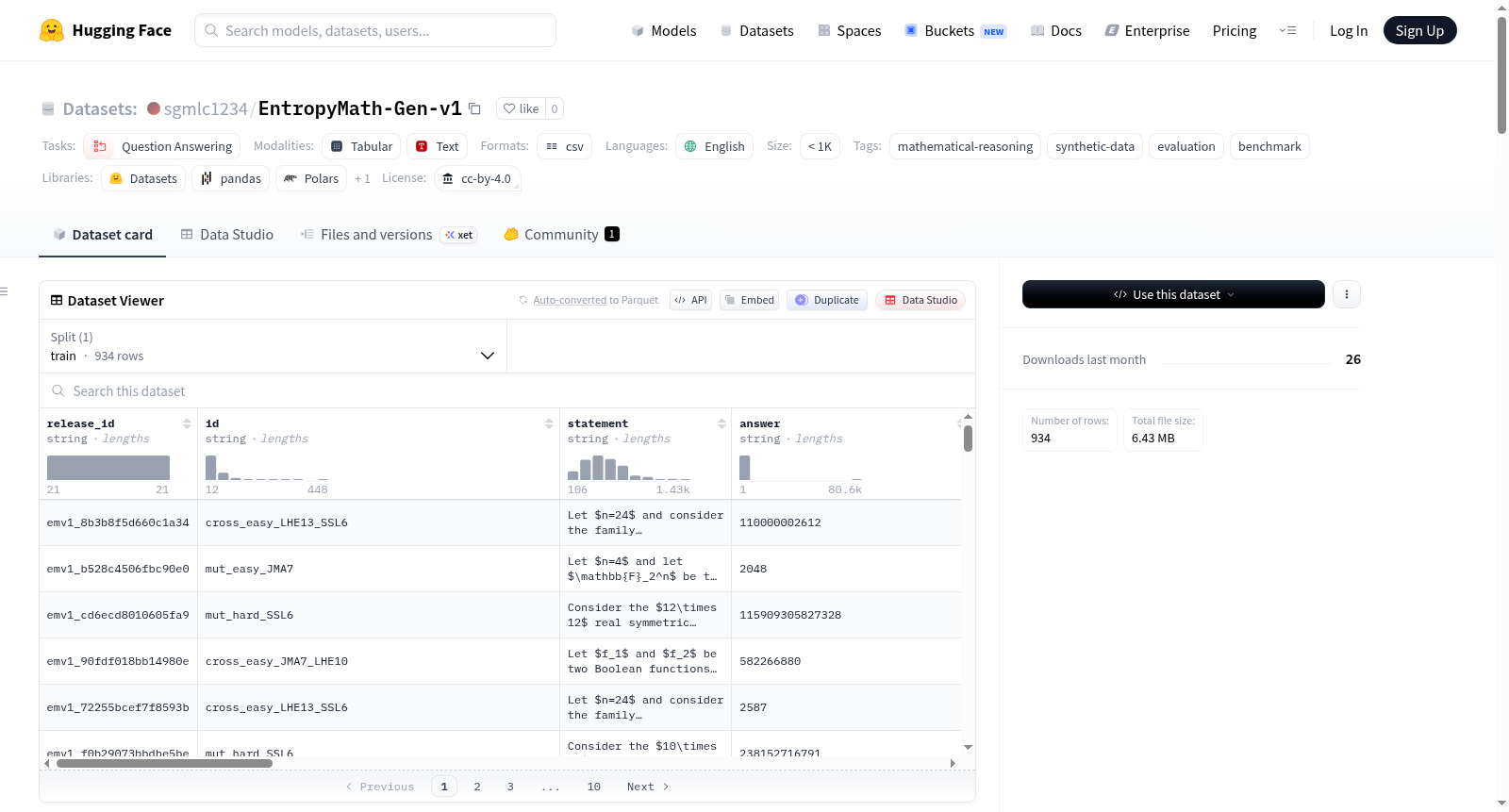
数据集包含934个经过质量门控和语句去重的数学推理评估问题,每个问题包含以下字段:
release_id:每条记录的稳定主键id:生成器标签,不保证唯一性statement:问题陈述answer:答案solution:解决方案verification_code:Python代码片段,用于验证计算一致性operation:操作类型difficulty/difficulty_label:难度信息generation/source_run/source_file/source_slot:生成来源元数据parent_ids/ancestor_ids:谱系信息statement_sha256/answer_sha256:内容哈希(去重依据)
文件结构
entropymath_generated_v1.csv:主数据表(934行)entropymath_generated_v1.jsonl:JSONL格式镜像croissant.json:MLCommons Croissant 1.1元数据metadata.json:质量门控统计信息LICENSE:CC BY 4.0许可证figures/:架构和生成器示意图
构建流程
- 从生成运行中导出1189个完整验证行
- 自动质量门控:隔离21个硬矛盾/运行时失败,228个支持缺口行,保留940行
- 按
statement_sha256去重至934行 - 单次人工专家验证通过(934/1176项,约79.4%)
数据生成方法
数据集通过一个以编排器为核心的进化生成框架生成,包含:
- 突变生成器:基于单个父问题通过受控变异生成新问题
- 交叉生成器:结合两个父问题通过不变束和桥接契约生成新问题
- 验证流程:包含合成简报、契约修复、沙箱检查和槽位级重试
预期用途
数学推理评估研究、生成器审计和基准方法学研究。注意:该数据集并非证明认证语料库,在高风险使用前需要独立审计。
已知限制
- 偏向种子和提示中代表的竞赛风格数学问题族
verification_code仅检查计算一致性,不证明所有解决方案- 大语言模型辅助验证可能遗漏歧义、快捷解法或无效推导
- 哈希检查有助于审计记忆化风险,但不保证污染自由
引用
Anonymous Authors. EntropyMath-Generated-v1: Evolutionary Generation and Validation for Auditable Mathematical Reasoning Evaluation. NeurIPS 2026 Evaluations & Datasets Track (under review).
许可证
搜集汇总
数据集介绍
构建方式
EntropyMath-Gen-v1是一个经过质量筛选与去重处理的数学推理评估数据集,源自EntropyMath生成框架的演化式构建流程。该流程首先从多次运行中导出1189条经过完整验证的候选样本,随后执行自动化质量控制门限,剔除21条存在硬性矛盾或运行时错误的条目及228条支持性不足的样本,保留940条。进一步基于statement_sha256进行哈希去重,最终获得934条陈述唯一的问题。整个发布版本还经过了单轮人类专家验证,从1176条候选中接受了934条,接受率约为79.4%。每一条数据均包含陈述、答案、解答、verification_code一致性证据字段以及谱系与溯源元数据。
特点
该数据集的核心特点在于其严谨的质量保障机制与丰富的元数据体系。每条数据均附带verification_code字段,这是一个可独立执行的Python代码片段,能在隔离沙箱中从陈述出发复现出发布的答案,为问题的计算一致性提供了可验证证据。数据集的去重策略采用内容哈希(statement_sha256)而非原始ID,保证了陈述级别的唯一性。此外,每条记录完整记录了生成上下文,包括操作类型、难度标签、来源运行与文件信息、父辈及祖辈ID等谱系数据,使得整个生成链条完全可追溯,为算法审计与方法论研究提供了坚实基础。
使用方法
该数据集主要面向数学推理评估研究、生成器审计与基准方法论研究等场景。用户可直接从Hugging Face加载entropymath_generated_v1.csv或对应的JSONL文件,利用其中的statement作为输入问题,answer作为标准答案,solution作为推理过程,verification_code作为一致性验证工具。由于答案、解答与验证代码均已公开,该数据集不适合用作永久隐藏排行榜,但在评估方案设计时,可利用其谱系信息控制训练集与测试集的分离,或使用verification_code对被试模型的输出进行自动化一致性检查。建议用户在高风险应用前独立审计数据质量,并注意其生成偏向于竞赛风格数学问题这一局限性。
背景与挑战
背景概述
EntropyMath-Gen-v1数据集由匿名研究团队于2026年创建,作为提交至NeurIPS Evaluations & Datasets Track的评审材料。该数据集专注于数学推理评估领域,通过进化生成框架与自动化质量门控机制,产出934道高质量、去重的数学问题。其核心研究问题在于构建一个兼具可审计性与计算一致性的合成推理基准,弥补现有数学推理数据集中缺乏系统化验证与溯源机制的不足。该工作通过引入verification_code作为计算一致性证据,以及完整的谱系元数据,为评估大型语言模型的数学推理能力提供了更为严谨的方法论框架,对推动可审计评估基准的发展具有重要影响。
当前挑战
该数据集面临的核心挑战包括:在领域问题层面,数学推理评估长期受困于数据泄漏和答案捷径问题,现有基准难以区分模型的真实推理与模式匹配能力,而EntropyMath通过合成生成与去重机制尝试缓解这一困境。在构建过程中,自动化质量门控需识别并隔离支持性不足或包含矛盾的样本,最终从1,189条候选数据中筛除21条矛盾失败与228条支持间隙样本,保留940条后经哈希去重确定934条。此外,人类专家验证仅接受约79.4%的候选样本,揭示了合成数据在保证推理深度与答案唯一性方面的固有难度,以及LLM辅助验证可能遗漏的语义歧义与无效推导风险。
常用场景
经典使用场景
EntropyMath-Gen-v1数据集的核心经典用途在于评估和基准测试大语言模型的数学推理能力。该数据集包含934道经过严格质量门控和去重处理的高质量数学问题,每道问题均配有语句、答案、解答过程以及可执行的验证代码片段。研究者可基于该数据集构建统一的数学推理评测基准,通过对比模型在标准问题集上的表现,量化评估模型的逻辑推导、数值计算和解题策略等核心能力。尤其适用于检验模型在竞赛级数学推理任务上的泛化性能与鲁棒性。
解决学术问题
该数据集系统性地回应了数学推理评估中数据污染和维护高难度、多样性题目的双重挑战。传统人工构建的推理基准往往受限于规模、领域覆盖或答案可被记忆的问题,而EntropyMath-Gen-v1通过进化生成框架自动产出问题,并配合自动化质量门控与人类专家验证的双重保障机制,提供了经过一致性检验的推理证据。它解决了如何生成可审计、可追溯且不易被模型记忆推理路径的数学问题这一关键学术难题,为构建动态、可控且具备统计可靠性的推理评测体系奠定了方法论基础。
衍生相关工作
基于EntropyMath-Gen-v1的构建范式,已催生出一系列围绕进化生成、质量控制与审计机制的重要衍生工作。其中最核心的贡献是提出了EntropyMath进化生成框架本身,该框架通过规划器、变异与交叉生成器以及多轮验证流水线,成功实现了从种子问题到高质量新问题的可控演化。此外,数据集附带的冻结模型评估输出、外部基准控制臂结果及审计样本等辅助证据文件,为研究数据生成过程的可追溯性、推理一致性的计算验证方法以及基准污染检测技术提供了公开参照系,有力推动了可审计数学推理评测领域的标准化进程。
以上内容由遇见数据集搜集并总结生成


