AIGC-Detection-Benchmark
收藏Hugging Face2026-04-03 更新2026-04-04 收录
下载链接:
https://huggingface.co/datasets/TheKernel01/AIGC-Detection-Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
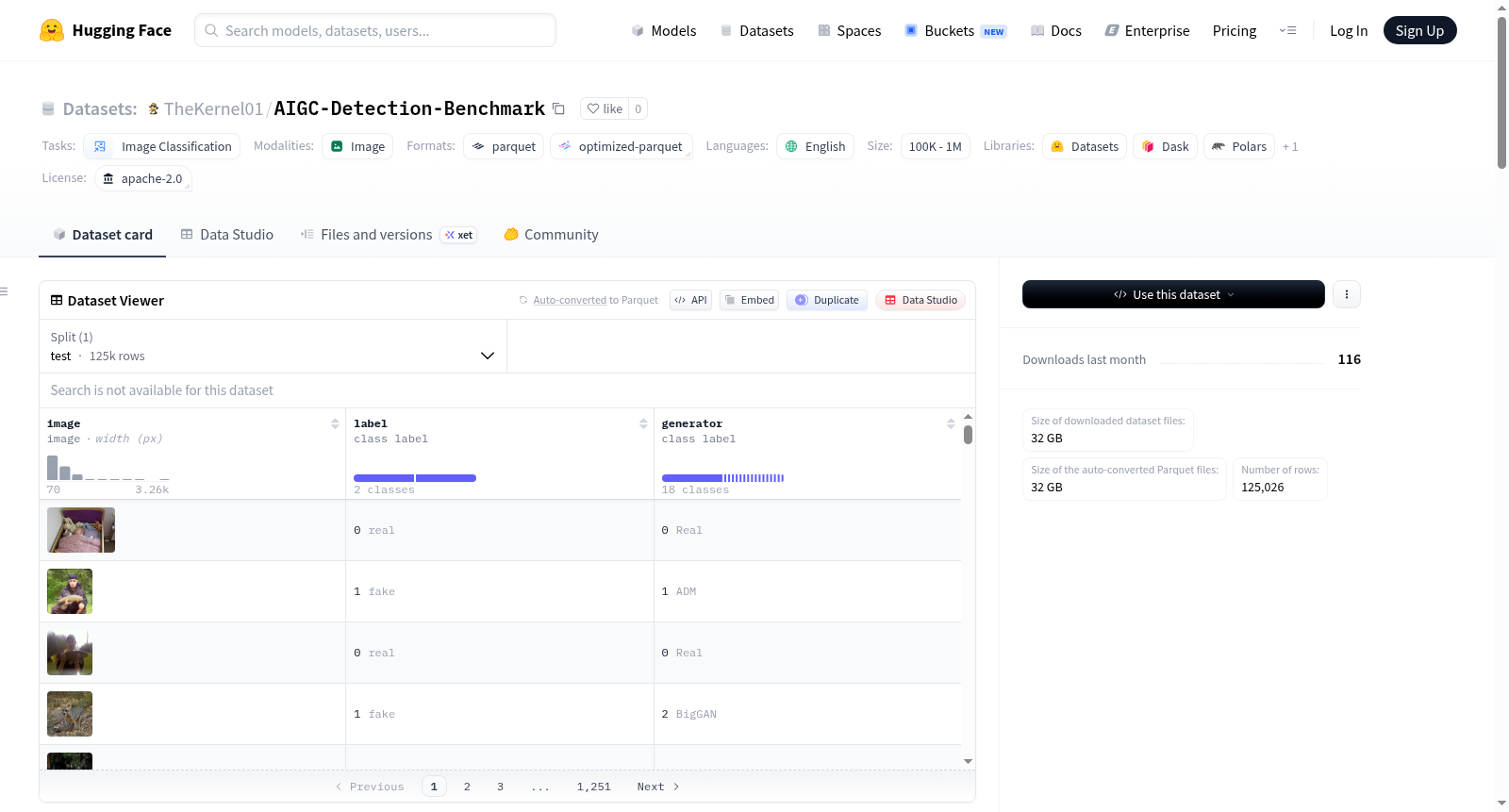
AIGC检测基准数据集是一个高质量的图像和元数据集合,旨在为检测和识别人工智能生成内容的模型提供基准测试。该数据集包含真实世界图像和由多种知名AI模型生成的图像,包括扩散模型(如Stable Diffusion、DALL-E 2、Midjourney、ADM)和GANs(如BigGAN、StyleGAN、ProGAN)。每张图像都经过精心标注,支持两个独立的计算机视觉任务:二元真实/虚假分类和多类别源模型识别。数据集共包含125,026个图像样本,全部用于测试和评估目的,分为一个测试集。每个数据实例包括一个图像文件和两个标签字段,分别表示图像的真实性和生成模型。数据集支持两个任务:任务A(二元真实性分类)和任务B(AI模型源识别),并提供了详细的标签定义和映射。
创建时间:
2026-04-01
原始信息汇总
AIGC Detection Benchmark 数据集概述
数据集基本信息
- 数据集名称:AIGC Detection Benchmark Dataset
- 发布平台:Hugging Face
- 数据集地址:https://huggingface.co/datasets/TheKernel01/AIGC-Detection-Benchmark
- 许可证:Apache-2.0
- 主要语言:英语 (en)
- 任务类别:图像分类
数据集简介
AIGC Detection Benchmark Dataset 是一个高质量的图像及相关元数据集合,旨在为检测和识别人工智能生成内容来源的模型提供基准测试。该数据集包含真实世界图像和由多种主流AI模型生成的图像,涵盖扩散模型(如Stable Diffusion、DALL-E 2、Midjourney、ADM)和生成对抗网络(如BigGAN、StyleGAN、ProGAN)。每个图像都经过精细标注,支持两项独立的计算机视觉任务:二元真伪分类和多类别源模型识别。此特定版本的数据集专为测试和评估目的设计,所有数据合并为单一的测试集。
数据详情
- 总样本数:125,026
- 数据分割:全部样本位于一个测试集(test)中,用于最终的无偏模型评估和基准测试。
- 下载大小:32,032,878,953 字节
- 数据集大小:29,870,625,563 字节
数据结构与字段
每个数据实例包含一个图像文件和两个标签。
数据字段
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| image | datasets.Image() |
图像内容(如.jpg, .png),加载为PIL对象。 |
| label | datasets.ClassLabel |
任务A:图像真伪的二元标签。 |
| generator | datasets.ClassLabel |
任务B:指定生成来源/模型的多类别标签。 |
支持的任务与标签定义
任务A:二元真伪分类
- 任务描述:将图像分类为真实或伪造。
- 输出类别:2类
real(值0):真实照片/非AI生成。fake(值1):由AI生成模型创建。
任务B:AI模型来源识别
- 任务描述:识别被标记为AI生成的图像所使用的特定AI生成模型。
- 输出类别:18类
| 标签 | 值 | 描述 |
|---|---|---|
| Real | 0 |
真实图像(未涉及AI生成)。 |
| ADM | 1 |
由Ablated Diffusion Model (Guided Diffusion) 生成。 |
| BigGAN | 2 |
由BigGAN生成。 |
| CycleGAN | 3 |
由CycleGAN生成。 |
| DALLE2 | 4 |
由OpenAI的DALL-E 2生成。 |
| GauGAN | 5 |
由GauGAN (SPADE)生成。 |
| GLIDE | 6 |
由GLIDE生成。 |
| Midjourney | 7 |
由Midjourney生成。 |
| ProGAN | 8 |
由ProGAN (Progressive GAN)生成。 |
| SD14 | 9 |
由Stable Diffusion 1.4生成。 |
| SD15 | 10 |
由Stable Diffusion 1.5生成。 |
| SDXL | 11 |
由Stable Diffusion XL生成。 |
| StarGAN | 12 |
由StarGAN生成。 |
| StyleGAN | 13 |
由StyleGAN生成。 |
| StyleGAN2 | 14 |
由StyleGAN2生成。 |
| VQDM | 15 |
由Vector Quantized Diffusion Model生成。 |
| WhichFaceIsReal | 16 |
来自WhichFaceIsReal数据集的真实人脸。 |
| Wukong | 17 |
由Wukong扩散模型生成。 |
数据来源
- 原始数据集:Ekko-zn/AIGCDetectBenchmark (https://github.com/Ekko-zn/AIGCDetectBenchmark)
搜集汇总
数据集介绍
构建方式
在人工智能生成内容检测领域,AIGC-Detection-Benchmark数据集的构建体现了严谨的学术规范。该数据集通过系统性地收集真实世界图像与多种前沿生成模型产生的合成图像,涵盖扩散模型如Stable Diffusion、DALL-E 2、Midjourney、ADM以及生成对抗网络如BigGAN、StyleGAN、ProGAN等代表性模型。每个样本均经过精细标注,包含二值真实性标签与多类生成源标识,确保了数据来源的多样性与标注的准确性。所有数据被整合为单一测试集,专为模型评估与基准测试设计,避免了训练与验证数据的混杂,从而保障了评测结果的客观性与可靠性。
使用方法
研究人员可通过HuggingFace数据集库直接加载该数据集,利用其标准化的图像与标签字段进行模型评测。数据集支持两种核心任务:使用`label`字段进行二值分类(真实与生成),或使用`generator`字段进行多类生成源识别。在评估过程中,模型需对测试集中的所有样本进行预测,并通过准确率、召回率等指标量化性能。该数据集专为最终评估阶段设计,建议在独立训练集上开发模型后,在此基准上进行严格测试,以客观衡量模型在AIGC检测与溯源任务上的实际效能。
背景与挑战
背景概述
随着生成式人工智能技术的飞速发展,合成图像的质量与多样性显著提升,对数字内容真实性鉴别提出了严峻挑战。AIGC-Detection-Benchmark数据集应运而生,旨在为人工智能生成内容检测领域提供标准化评估基准。该数据集由研究人员Ekko-zn等人构建,汇集了来自真实世界及多种主流生成模型的图像,包括扩散模型如Stable Diffusion、DALL-E 2以及生成对抗网络如StyleGAN、ProGAN等。其核心研究问题聚焦于图像真实性二元分类与生成模型多源识别,为计算机视觉领域在数字取证、媒体验证等应用方向提供了关键数据支撑,推动了检测算法在复杂生成场景下的性能评估与比较。
当前挑战
该数据集致力于解决人工智能生成内容检测领域的核心挑战,即如何在高保真合成图像日益泛滥的背景下,实现鲁棒且泛化性强的真实性鉴别。具体挑战包括:生成模型技术迭代迅速,新型架构产生的图像可能超出已有数据覆盖范围,导致检测模型泛化能力不足;不同生成模型在纹理、语义一致性等方面存在显著差异,要求检测算法具备细粒度特征区分能力。在构建过程中,挑战主要体现为数据收集与标注的复杂性,需平衡多种生成模型的代表性,确保数据分布无偏,同时应对大规模图像数据的存储与处理需求,维护标注一致性与准确性。
常用场景
经典使用场景
在人工智能生成内容(AIGC)检测领域,AIGC-Detection-Benchmark数据集被广泛用于评估模型在图像真实性鉴别方面的性能。该数据集整合了真实图像与多种主流生成模型(如扩散模型和生成对抗网络)产生的合成图像,为研究者提供了一个标准化的测试平台。经典使用场景包括对模型进行二分类(真实与伪造)和多分类(识别具体生成模型)任务的基准测试,从而推动检测算法的优化与比较。
解决学术问题
该数据集有效解决了AIGC检测中模型泛化能力不足和源模型识别困难等学术问题。通过涵盖多样化的生成模型和大量样本,它帮助研究者分析不同生成技术的特征差异,提升检测系统对未知生成方法的适应性。其意义在于为学术界提供了统一的评估标准,促进了检测技术的可重复性与公平比较,对防范虚假信息传播具有重要理论价值。
实际应用
在实际应用中,AIGC-Detection-Benchmark数据集支持开发用于内容审核、数字取证和媒体真实性验证的工具。例如,社交媒体平台可利用基于该数据集训练的模型自动识别AI生成的虚假图像,防止误导性内容扩散。在新闻行业和司法领域,它有助于鉴别深伪技术制造的证据,维护信息环境的可信度与安全性。
数据集最近研究
最新研究方向
在人工智能生成内容(AIGC)检测领域,AIGC-Detection-Benchmark数据集正成为评估模型性能的核心工具。随着生成式AI技术的飞速发展,特别是扩散模型和生成对抗网络(GAN)的广泛应用,虚假图像和深度伪造内容对社会信任与信息安全构成严峻挑战。当前研究聚焦于提升检测模型的泛化能力与鲁棒性,以应对新兴生成模型如Stable Diffusion XL和Midjourney等产生的复杂内容。前沿探索涉及多模态特征融合、对抗性样本防御以及可解释性分析,旨在构建更精准的源模型识别系统。这些进展不仅推动了计算机视觉技术的边界,也为数字内容认证和网络空间治理提供了关键支撑,呼应了全球范围内对AI伦理与安全监管的热点讨论。
以上内容由遇见数据集搜集并总结生成


